
MARL:多智能体强化学习入门 第一讲

第一讲 多智能体系统与多智能体强化学习介绍
多智能体系统历史
多智能体系统(MAS)故名思义,是存在多个智能体的系统,是承接40-50年代single agent思想面对不同问题与现实环境的一种扩展。
在现实问题中,我们不免会面对各种资源和条件的限制,使得用一个中心化的agent来解决问题变得困难重重,甚至不可行,同时有些现实问题从形式上来说形式化成多个single agent交互是一种合理与直观想法。
比如:在你上网的时候,你输入Github,此时你的电脑向外发送请求,这个访问的请求通过不同的路由器逐步地向Github的服务器请求资源,然后返回给你电脑,让你能够获得相应的信息。在你的电脑与Github服务器间可能存在动态的不同路径来建立连接,那么怎么获得一条最优的链接呢?一种方法是你能够获得整个互联网的拓扑结构与此时的负载,通过拓扑结构与负载来全局计算出一条最优的连接路径。但是在现实中,你并不能获得整个互联网的网络拓扑结构,一者是路由器可能动态地新增或者减少,另外一者是有的组织并不愿意将自己的内部的路由拓扑告诉你,此外哪怕你能拿到全局的拓扑结构,在实际计算中其实并不需要全部的结构,我们可能需要关注一些局部的路由器即可。所以一个中心化的agent来解决这个问题看上去并不可行,那么另外一种直观的做法是将每个路由器看作一个agent,由每个路由器来与自己互连的路由器进行交互,每个agent自己动态地优化当前时刻的转发表,通过自己维护的局部的信息来帮助用户获得整个互联网的服务。这就是典型的MAS的做法,也是现实中互联网采用的做法。
在最开始的1980年,MIT组织过一个distributed AI的workshop,点燃了MAS研究的星星之火,并在90年代诞生一些多智能体的研究协会与相应的比赛,比如IFAAMAS,比如大部分人都听说过的RoboCup等等,在2000年以来MAS与game theory,社会学,分布式优化,分布式求解等等领域与方法相结合成为了AI领域中一个炙手可热的研究领域,比如在AAAI与IJCAI中收录文章最多的领域就是MAS。
多智能体强化学习
MAS中存在着很多的研究子领域,比如:DEC-MDP,DCOP,mechanism design,negotiations等等活跃的研究生子领域,而多智能体强化学习是其中一颗耀眼的珍珠。
如果用一句话来介绍多智能体强化学习,那么就是将强化学习的算法与方法论运用在真实复杂的多智能体环境中来解决最优的决策的问题。
新的环境与新的领域必然就会带来新的挑战与新的问题。比如在single agent中只需要考虑将自己的task做到最好就可以了,但是在MARL的环境设置中,有些环境是存在竞争与合作的,如果你一味最优自己的reward,最终可能会使得在同个环境中其他agent与你竞争,最终既导致自己累积的reward受到损伤,同时使所有的agent的累积reward之和受到损伤。比如game theory中常见的囚徒困境就可以视为2个agent进行博弈的多智能体环境,如图所示:
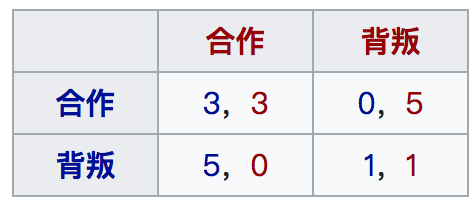

通过图片我们可以知道:不论对手采用什么策略,我们采用背叛的reward都比合作的reward高,简单地说就是背叛的策略支配合作的策略。对于一个理性的agent这个环境中进行学习,最终两个agent应该都会选择背叛的策略,也就是 背叛-背叛,这也就是经典的nash均衡。以nash均衡作为agent学习的目标是一种合理的想法,但是如果你的对手可能会与你合作的话,两个agent如果最终学习到 合作-合作,自身的reward大于背叛-背叛的reward,同时两个agent的reward也是最大的。在这个环境中,如果直接两个采用普通的RL的做法,最大化自己的累积收益,最终应该收敛到 背叛-背叛,从自身与整体的reward来考虑都不是一个很好的结果。
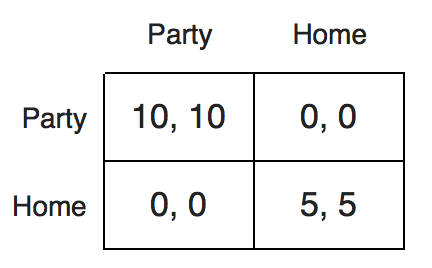
除了存在竞争与合作的环境,MAS中常见的还有合作类的环境设置。如图所示:


这一类环境相对囚徒困境中的勾心斗角,最终的目标相对简单:agent选择同样action。假设agent不知道另外agent选择的action,在这样的环境中,RL能够探索未知环境的学习能力成为了学习中的一种障碍,假设两个agent在这个环境中采用RL的方法进行学习,面对未知的环境agent会探索不同的ation,同时记录不同action对于reward的影响,但是在这个环境中,获得最好的reward是需要双方agent选择同个action,假设agent1,agent2此时同时选择left,那么他们都获得很多的reward,所以agent1可能会学习到left是一个好的选择,那么在下一次的交互中agent1还会选择left,但是如果agent2进行探索,选择了right,此时双方的reward都很小,所以会使得agent1很迷惑,left到底是不是一个好的选择,使得整个学习的过程中充满了随机性与困难。此外我们可能还能有一些扩展的环境设置,在这些环境的设置中,双方的reward并不是等同的,那么在合作的大前提下,他们需要进一步的博弈,来学习如果在合作的前提下,让对手让出自己的利益。

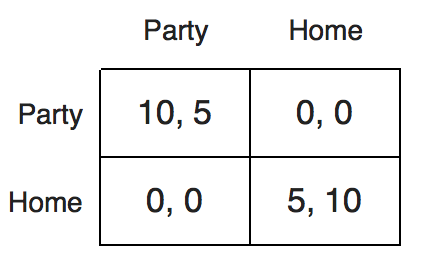



以上举了采用一次action就结束一局game的例子。在MAS环境中还对博弈进行的扩展:


如图所示,agent在grid world中进行移动,每次移动需要付出cost,每个agent需要移动到自己对应的终点来获得reward,同时终结掉这局game,那么agent间需要学会怎么避开与对手碰撞,怎么最优的路线等等。
MARL是一个热门的研究领域,在很多现实中的问题有广泛的应用,作者个人对于这类蕴含着合作与竞争的MARL更感兴趣,所以举出的例子多是与game theory结合的环境设置,MARL中还有其他让人激动的应用,比如学习communication等等,感兴趣的同学可以自行搜索最近的survey与summary,欢迎各种同学与我分享最新的survey与summary

