Lstm长期预测如何划分测试集?
关注者
8被浏览
23,792登录后你可以
不限量看优质回答私信答主深度交流精彩内容一键收藏

最近刚好在研究时序预测方面的东西,就贴个划分数据集的代码,可以参考一下。
在某SDN上看了很多时序预测划分数据集的帖子,其中比较合适的方式是将时序数据集转化为最常见的监督学习问题,即特征和标签的形式。
比如我想前一时刻的数据(t-1)来预测当前时刻(t)。我可以将t-1的数据当作训练数据,这个数据可以是单个变量也可以是多个变量,将t的值当作标签,然后构造n条这样的数据,直接用索引取值的方式就可以划分训练集和测试集了。
这里以一个空气污染数据集为例,数据集地址:
简单进行了一下数据处理:
import pandas as pd
df = pd.read_csv('weather.csv')
df['date'] = pd.to_datetime(df[['year','month','day','hour']])
df = df.loc[:,['date','pm2.5','DEWP','TEMP','PRES','Iws','Is','Ir']]
df.set_index('date',inplace=True)
df.columns = ['pollution','dew','temp','press','wndspd','snow','rain']
df.pollution.fillna(0,inplace=True)
df = df[24:]
num = len(df.columns)数据处理完是这个样子的:
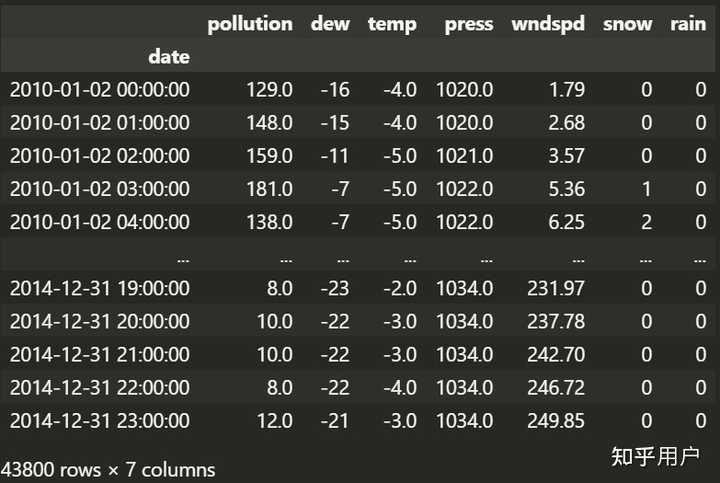

这里进行了一下归一化处理:
scaler = MinMaxScaler(feature_range=(0, 1),copy=True)
df.iloc[:,0:num] = scaler.fit_transform(df.iloc[:,0:num])之后就是将时序数据转化为监督问题数据的方法了:
这里如果不明白可以一步一步单独拿出来用print打印,我这个也是ctrl+c ,ctrl+v又改了改的~
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
df = pd.DataFrame(data)
columns = df.columns
cols, names = [],[]
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
#names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)]
names += [('%s(t-%d)' % (columns[j], i)) for j in range(n_vars)]
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
# names += [('var%d(t)' % (j+1)) for j in range(n_vars)]
names += [('%s(t)' % (columns[j])) for j in range(n_vars)]
else:
# names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]
names += [('%s(t+%d)' % (columns[j], i)) for j in range(n_vars)]
agg = pd.concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg调用方法:
我这里做的是多变量时序预测,是用前一时刻天的7个变量来预测其下一时刻的7个变量,为了方便观看,我又将数据逆归一化处理了一下,但实际训练时是需要归一化的。
reframed = series_to_supervised(df, 1, 1)
reframed.head(3) 生成的数据就是下面的样子:


如果你做的是单变量时序预测的话,可以将不需要的特征列删除
reframed = series_to_supervised(df, 1, 1)
reframed.drop(reframed.columns[[1,2,3,4,5,6,8,9,10,11,12,13]], axis=1, inplace=True)
reframed.head(3) 生成的数据就是这个样子的了:
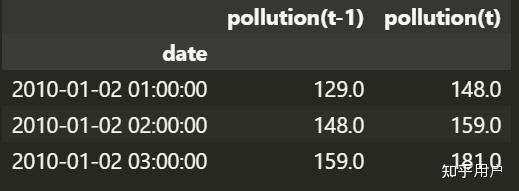

之后的思路就很简单了,就是按行索引切分数据就可以了,我这里取了一年的数据作为训练集,测试集为剩下的数据。因为数据的时间粒度是到小时的,所以一年就是365*24。
n_train_hours = 365 * 24
train = reframed.iloc[:n_train_hours, :].values
test = reframed.iloc[n_train_hours:, :].values然后就是划分“特征”和“标签”:
这里的变量num是在第一个代码块计算的特征数量
train_X, train_y = train[:, :-num], train[:, -num:]
test_X, test_y = test[:, :-num], test[:, -num:]之后的步骤我在这里就不写下去了,深度学习做时序预测只需要把数据reshape成神经元需要的形式就可以了。
相关资料: