异构计算分析

异构计算分析
一. 基本概念
异构计算技术从80年代中期产生,由于它能经济有效地获取高性能计算能力、可扩展性好、计算资源利用率高、发展潜力巨大,已成为并行/分布计算领域中的研究热点之一。
随着通信和网络技术的迅速发展,网络计算概念应运而生。同构网络计算系统now或cow首先兴起,接着很快涌现出异构网络计算系统,从而使异构计算近年来成为并行/分布计算领域中的主要研究热点之一。


人工智能有三要素:算法,计算力,数据。我们今天主要来讲讲计算力。
计算力归根结底由底层芯片提供。按照计算芯片的组成方式,可以分成:
同构计算:使用相同类型指令集和体系架构的计算单元组成系统的计算方式。
异构计算:使用不同类型指令集和体系架构的计算单元组成系统的计算方式。常见的计算单元类别包括CPU、GPU、ASIC、FPGA等。
在异构计算系统上进行的并行计算通常称为异构计算。人们已从不同角度对异构计算进行定义,综合起来我们给出如下定义:异构计算是一种特殊形式的并行和分布式计算,它或是用能同时支持simd方式和mimd方式的单个独立计算机,或是用由高速网络互连的一组独立计算机来完成计算任务。它能协调地使用性能、结构各异地机器以满足不同的计算需求,并使代码(或代码段)能以获取最大总体性能方式来执行。
概括来说,理想的异构计算具有如下的一些要素:
(1)它所使用的计算资源具有多种类型的计算能力,如simd、mimd、向量、标量、专用等;
(2)它需要识别计算任务中各子任务的并行性需求类型;
(3)它需要使具有不同计算类型的计算资源能相互协调运行;
(4)它既要开发应用问题中的并行性,更要开发应用问题中的异构性,即追求计算资源所具有的计算类型与它所执行的任务(或子任务)类型之间的匹配性;
(5)它追求的最终目标是使计算任务的执行具有最短时间。
可见,异构计算技术是一种使计算任务的并行性类型(代码类型)与机器能有效支持的计算类型(即机器能力)最相匹配、最能充分利用各种计算资源的并行和分布计算技术。
二.CPU&GPU
1. CPU
CPU( Central Processing Unit, 中央处理器)就是机器的“大脑”,也是布局谋略、发号施令、控制行动的“总司令官”。
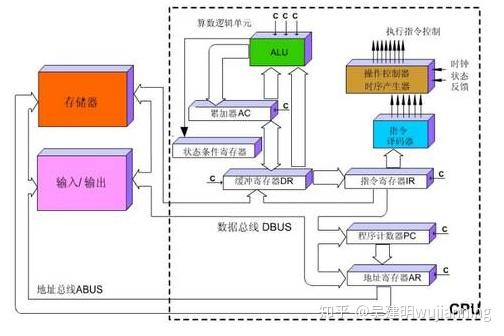
CPU的结构主要包括运算器(ALU, Arithmetic and Logic Unit)、控制单元(CU, Control Unit)、寄存器(Register)、高速缓存器(Cache)和它们之间通讯的数据、控制及状态的总线。
简单来说就是:计算单元、控制单元和存储单元。
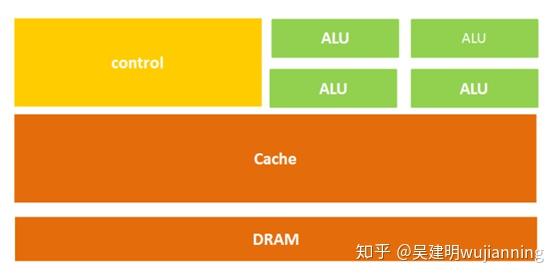


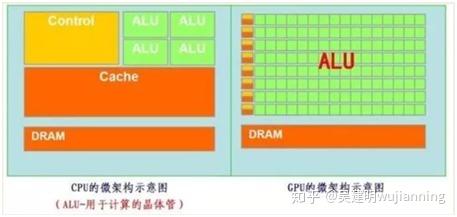
2. GPU
在正式讲解GPU之前,我们先来讲讲上文中提到的一个概念——并行计算。
并行计算(Parallel Computing)是指同时使用多种计算资源解决计算问题的过程,是提高计算机系统计算速度和处理能力的一种有效手段。它的基本思想是用多个处理器来共同求解同一问题,即将被求解的问题分解成若干个部分,各部分均由一个独立的处理机来并行计算。
并行计算可分为时间上的并行和空间上的并行。
时间上的并行是指流水线技术,比如说工厂生产食品的时候分为四步:清洗-消毒-切割-包装。
如果不采用流水线,一个食品完成上述四个步骤后,下一个食品才进行处理,耗时且影响效率。但是采用流水线技术,就可以同时处理四个食品。这就是并行算法中的时间并行,在同一时间启动两个或两个以上的操作,大大提高计算性能。



三.基本原理
1、异构计算系统。
它主要由以下三部分组成:
(1)一组异构机器。
(2)将各异构机器连接起来的高速网络。它可以是商品化网络,也可以是用户专门设计的。
(3)相应的异构计算支撑软件。

2、异构计算的基本工作原理。
异构计算需求在析取计算任务并行性类型基础上,将具有相同类型的代码段划分到同一子任务中,然后根据不同并行性类型将各子任务分配到最适合执行它的计算资源上加以执行,达到使计算任务总的执行时间为最小。下面通过一个简单例子来说明异构计算的基本工作原理。
假设在某一基准串行计算机上执行某一给定计算任务的时间为ts,其中向量、mimd、simd以及sisd各类子任务所占执行时间的百分比分别为30%、36%、24%和10%。假设某向量机执行上述各类子任务相对于基准串行机的加速比分别为30、2、8和1.25,则在该向量机上执行此任务所需的总时间为
tv=30%ts/30+36%ts/2+24%ts/8+10%ts/1.25=0.30ts,
故相应的加速比为sv=ts/tv=ts/0.3ts=3.33
若上述向量机与其他的mimd机、simd机以及一台高性能工作站(sisd型)构成一个异构计算系统,并假设mimd机、simd机以及工作站执行相匹配子任务的加速比分别为36、24和10,则在该异构计算系统上执行同样任务所需时间就变为
thet=30%ts/30+36%ts/36+24%ts/24+10%ts/10+tc
其中tc为机器间交互开销时间,假设需2%ts时间,则thet=0.06ts,从而相应的加速比为shet=ts/0.06ts=16.67。
由上例可见,异构计算系统可比同构计算系统获取高得多的加速比。这主要是因为同构计算系统中的加速比只是靠并行性开发获取的,而异构计算系统中的加速比除了并行性之外,更主要的是靠开发异构性获得的(即不同类型子任务与相应类型的计算资源相匹配),尽管此时会有相应的交互开销。交互开销越小,异构计算的优越性就越加明显。

3. 分类
异构计算按以何种形式来提供计算类型多样性,可分为系统异构计算(shc-system heterogeneous computing)和网络异构计算(nhc-network heterogeneous computing)两大类。shc以单机多处理器形式提供多种计算类型,而nhc则以网络连接的多计算机形式提供多种计算类型。
根据异构性实现方式不同,即是空间异构性还是时间异构性,shc和nhc各自又可进一步分为两类。shc分为单机多计算方式和单机混合计算方式两大类,前者在同一时刻允许以多种计算方式执行任务,后者在同一时刻只允许以一种计算方式执行任务,但在不同时刻计算可从一种方式自动切换到另一种方式,如simd和mimd方式间的切换。前者的实例有美国hughes研究实验室和mit共同研制的图像理解系统结构(iua),它是多层异构系统结构,按图像理解层次要求设计每一层,低层是simd位串网络(4096),用来处理像素级操作(如图像增强),中层是由64个数字信号处理(dsp)芯片构成的,以spmd或mimd(中粒度)方式执行模式分类等操作,顶层是一个通用mimd(粗粒度)机器,完成场景和动作分析等知识处理操作。后者的实例为美国普渡大学研制的pasm系统原型,由16个pe(处理单元)组成的系统,它们可动态地加以划分以形成各种大小的独立的混合方式子机器,执行方式可按需要在simd和mimd之间自动切换。
nhc可进一步分为同类异型多机方式和异类混合多机方式两类。同类异型多机方式中所使用的多机,它们的结构属同一类,即支持同一种并行性类型(如simd、mimd、向量等类型之一),但型号可能不同,因此性能可以各有差异。通常的now或cow为同类同型多机方式,因此可看成是同类异型多机方式中的特例。异类混合多机方式中所使用的多机,它们的结构则属不同类型。


4. 层次结构
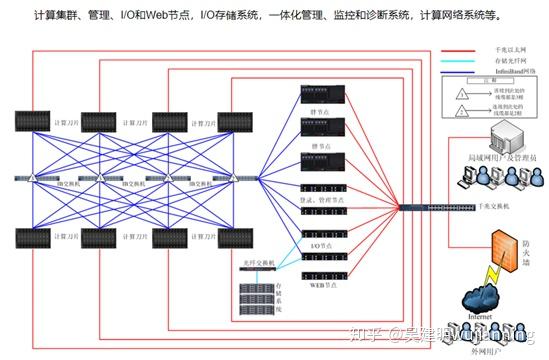
网络异构计算系统主要由一组异构计算机、一个连接所有机器的高速网络和一个并行编程环境所组成。逻辑上这种系统可分为三个层次:网络层、通信层和处理层。如图1所示。
网络层主要用来连接在不同地点的计算机,如图1中的计算站a和计算站b,并考虑其中消息传递的路由选择、网络流优化和网络排队理论等问题,这与传统的计算机网络设计类似。
通信层工作于网络层之上,主要为系统中各种不同的计算机提供能够相互通信的机制。通信工具软件应提供使众多异构计算机集合可视为是一个单一的系统映像、单个虚拟异构并行机的机制。这将方便用户编程。这种通信工具通常提供一组原语来提供各种通信。典型流行的通信工具是pvm(并行虚拟机)和mpi(消息传递标准接口)。
处理层主要用来管理异构机器组并保证任务的高效执行。它所提供的主要服务包括编程环境和语言支持、应用任务的类型分析和任务划分、任务的映射与调度以及负载平衡等。
5. 主要问题
异构计算处理过程本质上可分为三个阶段:并行性检测阶段、并行性特征(类型)析取阶段以及任务的映射和调度阶段。并行性检测不是异构计算特有的,同构计算也需要经历这一阶段。可用并行和分布计算中的常规方法加以处理。并行性特征析取阶段是异构计算特有的,这一阶段的主要工作是估计应用中每个任务的计算类型参数,包括映射及对任务间通信代价的考虑。任务映射和调度阶段(也称为资源分配阶段)主要确定每个任务(或子任务)应映射哪台机器上执行以及何时开始执行。
从用户来看,上述的异步计算处理过程可用两种方法来实现。第一种是用户指导法,即由用户用显式的编译器命令指导编译器完成对应用代码类型分析及有关任务的分解等工作,这是一种显式开发异构性和并行性方法,较易于实现,但对用户有一定要求,需将异构计算思想融入用户程序中。另一种是编译器指导法,需将异构思想融入编译器中,然后由具有“异构智力”的编译器自动完成应用代码类型分析、任务分解、任务映射及调度等工作,即实现自动异构计算。这是一种隐式开发异构性和并行性方法,是异构计算追求的终极目标,但难度很大,对编译器要求很高。