
BiLSTM_CNN_CRF分词程序—运行讲解

在线演示:http://118.25.42.251:7777/fenci?type=mine&text=南京市长莅临指导,大家热烈欢迎。公交车中将禁止吃东西!
一、源程序下载
以上文件夹中,我们只需要保留.py文件即可(为防止我的权重文件和你的语料、模型不匹配,只保留py文件即可)。




二、模块安装
python3.5
pip install keras==2.0.6
keras_contrib==2.0.8 【pip install git+https://www.github.com/keras-team/keras-contrib.git】
pip install gensim
如有其它模块缺失,可自行百度安装。
三、训练语料格式及存储
py文件的当前路径,新建corpus文件夹,该文件夹作为语料存储根路径。


corpus下,我们按文件夹存放子语料,比如我的子语料如下:


其中,conll_little是conll2012语料的一个领域(我后面又上传了conll2012全部领域,建议先使用conll_little将模型调试成功,再使用conll2012_all加入corpus中训练),law_100是法律文书语料;
子语料(例如law_100)下,按文件存放相关子文件:

其中,每个文件中内容为如下格式(例如 4.txt),空格将词隔开:

四、词向量训练
python embedding_model.py // word2vec的相关参数可调控,我设的100维词向量。
程序运行完,将会得到两个词向量文件(.m和.txt文件),如下:


其中,.m文件是给程序(模型)使用的,.txt是为了可视化,我们自己看的。
五、测试文件
py文件的当前路径下,新建test_documents文件夹,作为测试文件的根路径。
test_documents文件夹下,我放置了一个test_1的文件夹,test_1文件夹下存放需要分词的文件(33.txt和88.txt)。






33.txt中文本格式如下,为待分词文本。

以上是测试文本的介绍,这部分自由度较高,可以等模型训练好后自行安排。
六、模型训练
我们在 bilstm_cnn_crf.py中,将 is_train设为1(训练),将 nb_epoch设为10。
(网络的一些参数可以自行定位到程序中修改,如batch_size、nb_epoch、optimizer等)
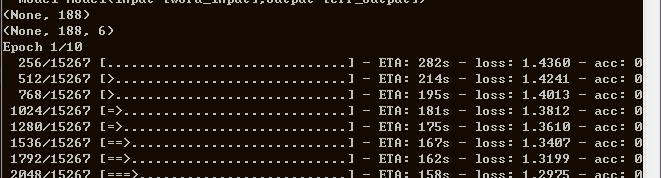
python bisltm_cnn_crf.py // 如不出错,如下图,则训练初步成功
训练时间跟语料多少、迭代次数有关。

七、性能评测


按文件分词为上述函数,其中第一个路径是待分词文本(test_1)、第二个路径是分词后文本(test_1_mine,该文件夹会自动生成,保存分词结果)
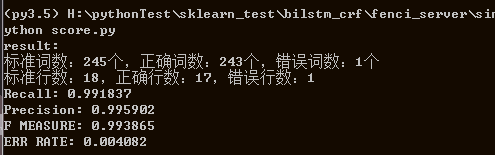
socre.py 程序可以通过输入两个文件名,计算(P、R、F和ERR)
如下,比较预测的33.txt和标准文件中33.txt,得到该文件的一些分词性能指标。


python score.py

八、使用我的权值文件
以上执行完,你将会生成你的权值文件,模型性能的好坏取决于训练语料的多少。
在my_weights文件夹下,有我预训练的权值文件(conll2012+law_100),性能不一定最优,仅供参考。
1. 删除py文件当前位置的其它权值文件,只保留py文件和文件夹(conll2012_test_gold是conll测试文件的gold文件)




将my_weights下的3个文件copy到py文件当前位置。

将bilstm_cnn_crf.py中is_train设为0



修改fenci_by_file函数的两个路径,对conll2012_test_raw进行分词
其中,test_documents/conll2012_test_raw/bc_conll_testing.utf8文件部分如下:


python bilstm_cnn_crf.py
运行结束后,test_documents下将出现conll2012_test_mine文件夹,其下6个文件对应于test_documents/conll2012_test_raw下6个文件的分词结果。
其中,test_documents/conll2012_test_mine/bc_conll_testing.utf8部分如下:


为了验证分词模型性能,我们比较test_documents/conll2012_test_mine下的6个测试结果文件和conll2012_test_gold下的6个黄金结果文件。
修改score.py中文件的路径


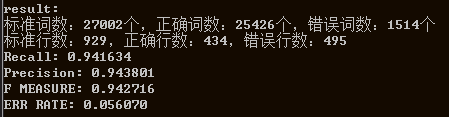
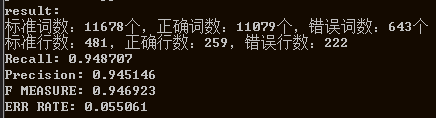
分别测试conll2012的6个领域测试集的分词性能,结果如下(结果还将就,说明模型work):
bc领域:


bn领域:

mz领域:


nw领域:

tc领域:
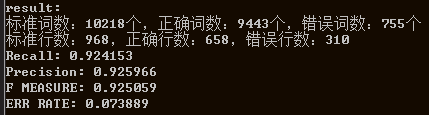

wb领域:
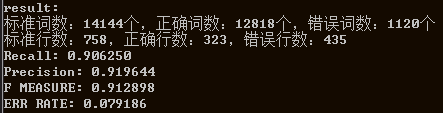

以上6个领域的测试性能F值均能达到0.91以上,说明模型训练还算成功。
此外,为进一步提高性能,需要进行一些参数的调整(如学习率、优化器等),或增加训练次数(本文不做探究,仅提供一个Demo)。
此外,以上是将6个不同领域的训练语料一起训练、最后再测试,可能存在领域适应性问题,分开训练、分开测试或许结果更优。
九、一些问题
1. 本文训练时将文件按几个常见的标点隔开(,。;),模型的输入长度maxlen以训练集中句子的最大长度决定。测试时句子按标点(,。!;?)隔开,之所以多加了几个标点,是为了尽量将句子切分的较短,不然测试时句子长度大于maxlen,将会被截断,信息丢失。这里我感觉处理的不够好,如果遇到奇怪的文本(例如没有标点,句子又很长),信息将会只保留maxlen长度。
2. 测试时,读入一个测试文件,本程序将按行进行分词,将行line输送给word_seg_by_sentences函数,该函数再将line按标点切分,组合成句子集的向量表示,输送给模型进行预测(分词),最后再拼接还原成分词后的line。这里运行效率较低,可以将一个文档的所有文本按标点切分,组合成向量,输送给模型预测。
3. 程序写的冗余、杂乱! 讲解写了一晚上,效率太低,心累,还望点赞支持~~~。
......
以上问题由于时间问题,不做修复。如有其它问题,可告知,共同思考。
