


引
当AI侵犯了你,你会怎么办?这是个顶顶有意思的问题。我旁边的小姐姐出门路过自动贩卖机,“被”刷脸买了一瓶上个同事没付款的可乐之后,就开启了黛玉模式拉着我叽叽喳喳。
当然如果我们抛开小姐姐不谈,这个问题本身其实很值得探讨:如果有一天我们面临AI安全,我们会怎么预防以及夺回控制权?
AI安全,也是今年蚂蚁集团“系统安全+AI”的极限攻防赛事——A-tech科技精英赛聚焦的主题 [1].主办方基于赛事,制作推出了《燃烧吧!天才程序员》真人秀,这或许是第一个关于程序员的真人秀节目。在节目中,20位选手需要在48小时内解决两大赛道难题——攻防赛道的层层内网渗透和AI赛道的野生动物检测。而在AI赛道中,组委会还特别开辟了AI安全的隐藏赛道。
自从1956年麦卡锡、明斯基、香农等人提出“人工智能”概念以来,随着AlphaGo战胜人类围棋冠军,如今遍布世界的传感器发展让“智能化”成为大势所趋。归根结底,海量数据的出现(互联网)、计算能力的快速提升(CPU、GPU、专用芯片)和开源运动的深入人心(大量开源算法)让人工智能正朝历史性时刻迈进。我想如果我在这里声明人工智能目前展现的潜能只是一个开始,应该也不会遭到太多反驳。
但是,正如文初的案例,快速发展的“智能+”也并不是完美的存在。当AI算法设计之初普遍没考虑相关安全风险时,更容易让程序流程 “误判”、算法“失准”或隐私数据“泄露”。 这种困扰如果被有心之人利用,会造成巨大危害且难以发觉。
而网络黑产就是这样的「有心之人」,庞大的网络黑产链条对大众信息进行收集、贩卖,为整个黑产行业提供重要支撑。2018年初央视315晚会曾经曝光过骚扰电话产业链,单个公司年呼出骚扰电话接近40亿,相当于14亿中国人每人收到2.85次。如何更好地保护用户隐私,抵御这些恶意利用AI的黑产链条的攻击,也成为科技企业重点攻克的问题。
另一方面,在AI模型的训练阶段,如果加入简单的噪音,有可能会使智能控制系统被训练出错误决策。这种情况在AI安全领域被叫做「数据完整性」挑战。而文初「被刷脸」的例子,则是一个软件系统问题,被称作AI业务的「流程鲁棒性」。这两个问题被称为目前AI服务面临的六大安全挑战中的两个。
事实上,作为多学科发展共同驱动的领域,人工智能目前还处于早期发展阶段,对AI安全来说也需要更多研究投入,才能够解决相关安全问题,更好地保护AI的使用者,我想这也是蚂蚁集团举办A-tech科技精英赛[2],并制作首档程序员真人秀《燃烧吧!天才程序员》的原因之一。
目前,在AI安全领域,大家主要关注的方面可以这样总结:
1.如何保证软硬件本身的安全性?
2.如何保证模型对用户和攻击者是机密的(confidential)?
3.如何确保模型对恶意样本足够鲁棒?
4.如何确保用户数据隐私?1.软硬件本身的安全性--AI业务架构是否是安全的?
现代人工智能的一大应用是车联网,但是对于车辆驾驶这种应用场景来说,AI黑箱往往会对系统安全性分析带来困难。比如如果AI系统对刹车,转弯,加速等关键操作的判断失误时,可能会对用户或者社会造成比较大的危害。这时候,我们通常用来保证车辆行驶安全的安全性测试往往也面临难题,因为我们往往很难找到一个在任何时候都能给出100%正确答案的AI系统。
又或者,在医疗领域很多病症并没有确切答案,这时候各种方案都潜在风险,这时候相比直接给出一个精确的、但是可能存在伤害的用量,让AI系统直接回答「请去医院咨询医师」是更好的选择。
上述两个案例就是AI在算法之外的架构安全问题,这个问题其实可以讲的更加浅显易懂一些:参与人工智能算法的整个业务架构(包括软件和硬件)是否都是安全的?---要知道现实里通常都不会存在非常完美的网络安全。
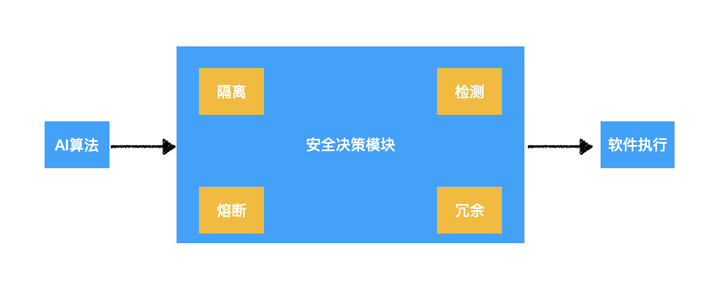

为了保护用户利益,我们一般需要在设计AI业务架构的时候更多考虑系统的隔离度、对攻击的检测速度、是否存在熔断机制和数据之间是否存在冗余关联性。在这些设计结构里,1)对关键决策系统的隔离设置,可以一定程度上减少对AI推理的攻击危害;在主业务系统中部署持续监控和攻击检测模型,并且追踪和分析网络系统安全状态,这种方式可以提前预知潜在风险并修复;2)采用多级架构的熔断系统,更能够在关键时刻对模块流程和操作性进行修改,这样就能够在确定性低于阈值时,把规则判断为准的常规技术直接交回人工处理;3)此外,一个存在冗余备份的系统可以保证关键任务切换,关键时刻也是十分必要的。
所以,软件架构通常是AI算法的重中之重,甚至可以直接决定AI算法是不是能够落地。
2.模型本身的机密性—AI模型安全如何保证?
大家都知道,在数据和模型层面,软件和系统设计者总是希望能够隐去中间推理层,只提供最终的推理结果,这样既不暴露模型本身,也能实现AI所需完成的工作。
但攻击者仍有可能通过分析系统的输入和输出还原出原本输入的信息。
鉴于目前大多数AI模型都部署在云端,系统通过远程调用的形式来完成相应的图像、语音识别任务。这种架构其实存在一些问题,比如攻击者可以通过多次远程调用接口,则有可能把AI模型从数据接口中「窃取」出来。这而相应模型的泄露不仅会造成知识产权和经济损失,也可能帮助攻击者生成相应的攻击样本。
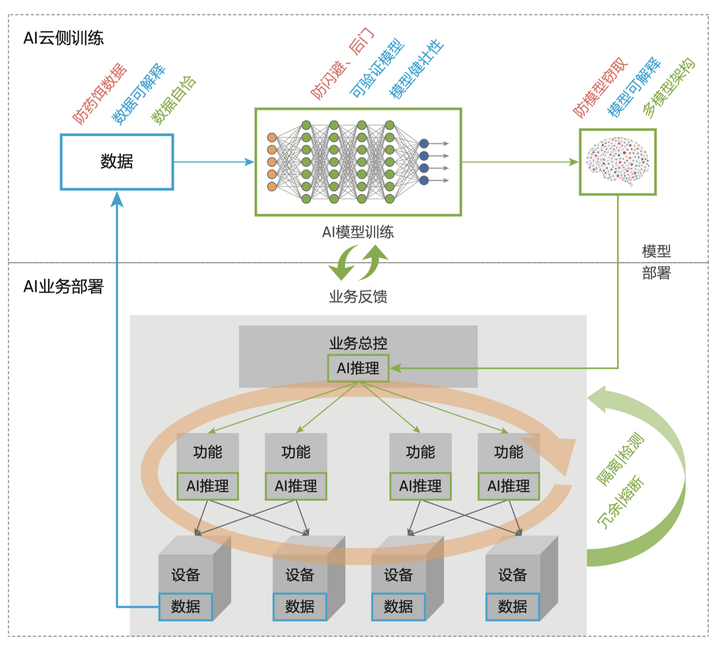

因此从防御角度出发,我们通常会采用两种技术以避免模型被窃取,一种是输入重构技术,另一种是模型验证技术。前者在使用模型过程中,把输入样本进行变形、转化,从而避免直接的窃取工作,而后者可以通过设定一些最优化求解器,验证模型本身的各种属性,这样可以保证AI模型的正确性。
这里还有一种比较神奇的方法,是采用特殊的激活单元或者网络结构来人为添加「水印」到神经网络中,这样可以用于非常明显的鉴别模型是否被盗走后使用,这种方法被称为「模型水印」。
当然,我们也必须提到的是,这几种方法只是特定场景下的安全增强,并不能抵抗所有对抗样本。如果我们能够在模型功能性一致的情况下提高算法的安全性,则可以更好的解决技术应用安全问题。
3.模型对恶意样本的鲁棒性---AI模型是否能处理各种异常?
在AI安全领域,有一个非常经典的概念叫做闪避攻击(Evasion),也就是通过修改输入,让AI模型无法其正确识别。这就像「完美」避开了守门员,把球踢进门中去,这是目前学术界在AI攻防领域研究最多的一类攻击,或许没有之一。比如在现实生活中,图像识别可能会遇到各种各样的涂改[3],比如把禁止通行修改为限速45,这样比较简单就可以欺骗AI算法。


在A-tech科技精英赛的赛题设计中,有一个突出的创新亮点。大赛针对野生动物识别的AI赛题融入了“被污染”的数据样本,首次将AI安全引入网络攻防大赛。组委会在为选手们准备的数据中存在两种干扰设计:一种是肉眼看得见的干扰,如部分照片中存在雨雪,是自然噪声,模拟的是野外真实条件下的拍摄场景;另一种是肉眼不见的干扰,即对抗样本,目的是为了欺骗AI,让AI做出错误的判断。






从理论上来说,这些「被污染的数据」是对原始图片添加一个微小扰动,正因为这种扰动的存在,所以让模型出现了识别错误。一种解决方式是通过增加外部检测模型或者原模型的检测组件,来判断输入图像到底是否经过修改,这种方式叫做对抗样本检测;另外一种方式是把多个DNN单元串联,前一个DNN的输出作为后一个DNN的输入,这种网络蒸馏[4]方法可以降低模型本身对于微弱扰动的敏感程度,提高系统的鲁棒性和泛化能力。
事实上,不论是添加对抗样本检测单元,还是采用网络蒸馏方式,都可以增强模型的鲁棒性,从而达到对抗异常输入的目的。但是这些方式都存在或多或少的不足,而且效果难以定量分析,这是这部分研究和产业都正在面临的一大难题。
4.数据隐私问题---联邦学习的发展可以让数据更多在本地处理。
作为一项数据驱动的技术活,人工智能自从问世以来就面临相当大的隐私和安全问题,虽然说很多人认为,数据的跨域流动提高了生产力、并且提升了创新,但是这里的「跨域」往往会伴随着一些隐私灰色地带。
世界上最大的咨询机构之一德勤曾经认为,数据隐私问题有望从立法方面得到解决。前几年,欧洲出台了「史上最严」的隐私保护法GDPR,国内数据隐私保护办法也即将问世。虽然立法工作整个流程比较顺利,但是各国政府确实有在思考另外一个问题,也就是过于严格的行政禁令可能会严重阻碍创新出现,所以亟需除政治以外的、技术上的解决方案。
「联邦学习」在这种情况下问世,并在目前得到了非常大的繁荣。
从理论上讲,如果传统情况下,多个数据拥有方需要一起训练某一个模型,传统的方法是把数据本身整体传输,在汇总后再进行训练。这样就产生了一个问题,我们无法保证数据本身的隐私,也无法保证它传输过程中是否安全性。
相比经典的机器学习,联邦学习首先需要在终端做到数据隔离,这也适合最理想的隐私保护场景---数据在各个终端不共享,不均衡,互通也会尽量少。在各个终端数据隔离的情况下,联邦学习通过在节点之间共享参数来完成多个节点网络的同时训练,也正因为共享的是参数,所以用户数据本身依旧留存在本地,也就完成了相应的隐私保护。
手机下载模型→在本地训练汇总为一个小更新→通过加密通信发给云服务→更新各个参与计算的终端,最终汇集。
这是目前非常典型的联邦学习流程。
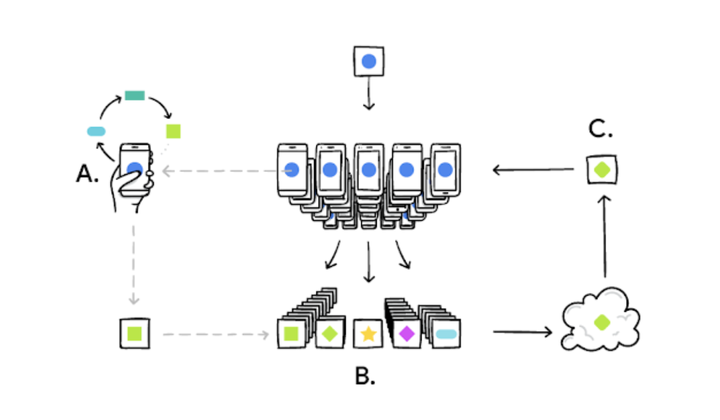

事实上,我们一般也认为,联邦学习可以在保护隐私的同时提供更加智能的模型,提供更低的延迟和功耗,而且还能在线改进权重加速迭代。
总结:
现代社会人类已经完全离不开科技本身,也离不开互联网带来的信息世界。过去飞鸽传书跑马千里,一个简单的讯息就需要传递十天半个月,现在社交软件让我们咫尺天涯,也可以借助飞机朝夕万里。
数字化和互联网也极大地丰富了人类的生存方式、生活方式,正如我们十几年前完全想不到手机已经可以帮我们解决几乎所有日常事物。但不可否认的是,对于AI而言,或者说在新生事物诞生之初总会有各种各种各样的不成熟,但是也正是因为这些不成熟、这些安全领域学者和业界默默无闻、孜孜不倦做出的努力,整个人工智能产业才会滚滚向前。
正是这些努力,才不会让我们对「AI」的担忧成为现实。
站在技术开端,我们其实都不能完整想象未来可能会如何,也不能想象我们到底是否会在未来面临怎样的安全问题,这样就使得类似A-tech科技精英赛这类技术挑战赛更为重要。因为如果一个人的想象力有限,那一批天才在一起的想象力集合还会更加宽广,这样的预测可以让科技发展和未来走上正途,我想这或许是产业界巨头利用自己的影响力,来共同推动领域科技创新、体现科技愿景、实现社会责任的一条康庄大道。
参考
- ^在外滩大会上,选手团队在支付宝首席AI科学家漆远、清华大学计算机系教授朱军等导师的指导下出战48小时极限攻防挑战,向世界展现新的时代下年轻人的力量
- ^“Inclusion | A-tech科技精英赛”(A-tech)由A-tech大赛组委会主办,蚂蚁集团、桃花源生态保护基金会、中国猫科动物保护联盟联合发起 ,并由上海交通大学、清华大学和世界工程组织联合会创新专委会共同协办,面向全球的网络安全与AI科技精英发起的挑战赛。创造“AI+安全”全新赛制的A-tech科技精英赛,是极客圈里的「铁人三项综合赛」, 获胜团队赢取100万现金奖励,还有更多与蚂蚁集团合作的机会。
- ^K. Eykholt, I. Evtimov, E. Fernandes, B. Li, A. Rahmati, C.Xiao, A. Prakash, T. Kohno and D. Song, "Robust physicalworld attacks on deep learning models," in Conference on Computer Vision and Pattern Recognition (CVPR) , 2018.
- ^N. Papernot, P. McDaniel, X. Wu, S. Jha and A. Swami, "Distillation as a defense to adversarial perturbations against deep neural networks,," in IEEE Symposium on Security and Privacy (S&P) , 2016.