
Ensemble Learning
Ensemble Learning是机器学习里最常见的建模方法,RandomForest 和 GBDT 采用了Ensemble Learning模式,只是具体方法不同。
下面简单翻译下一 https://www.analyticsvidhya.com/blog/2015/09/questions-ensemble-modeling/ 这篇文章,再来理解一下Ensemble Learning模式。
与Ensemble Learning相关的常见问题
1、什么是Ensemble Learning?
2、什么是bagging, boosting, stacking?
3、同一个ML算法怎么做集成(ensemble)?
4、不同的模型如何确定权重?
5、ensemble模型有什么优势?
下面一个一个来回答。
1、什么是Ensemble Learning?
文中举了一个垃圾邮件检测的例子,简单来说就是,仅凭单个规则很难准确识别垃圾邮件,但是使用多条规则会提高识别的准确率。这个例子是为了说明,ensemble learning是一个“多合一”的方法。“多”指的是多个个体模型(individual models),注意,并非是多个独立模型;“合一”指的是多个模型共同形成一个识别/回归结果。Ensemble的一般特点是,多个模型间的相关性越低,合成之后的识别/回归效果越好。
具体的合成方法有多种,其中最典型的ensemble算法是随机森林(Random Forest)。引用文中的话是:
It (Random Forest)performs better compared to individual CART model by classifying a new object where each tree gives “votes” for that class and the forest chooses the classification having the most votes (over all the trees in the forest). In case of regression, it takes the average of outputs of different trees.
2、什么是bagging, boosting, stacking?
Bagging是对样本进行采样,构造出若干个新数据集,然后对应训练出若干个模型,再把这些模型合而为一,得到输出结果。其本质是降低了模型的方差(Variance)。
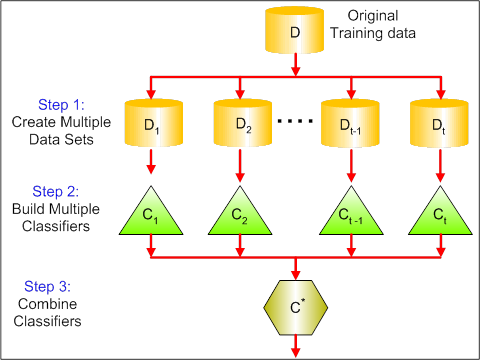
Boosting是一种模型迭代方法,初始化时,有一个简单的模型、各样本权重相等,由此得到识别结果,根据识别结果调整样本权重,判错的样本权重变大,据此得到新的模型,把新模型迭代到老模型上,再得到识别结果,如此循环迭代下去,最终若干个模型叠加在一起,得到最终的输出模型。
Boosting一般精确率比Bagging更高,但是容易过拟合(over-fit)。
常见的两种Boosting算法是 AdaBoost 和 Gradient Boosting。
[原文中的图没看懂,就不附图了]
Stacking就是简单的模型合成,先从原数据中训练得到若干个模型,然后用一个函数把若干个模型合成,输出最终的识别/回归结果。这里并没有介绍如何做合成,日后遇到具体案例再来细聊。
3、同一个ML算法怎么做集成(ensemble)?
可以把相同的模型集成起来,但是这样做的效果通常不会太好,更提倡的做法是把不同类型的模型集成起来,比如 把Random Forest , KNN 和 Naive Beyes集成起来,模型之间越是不同,集成后的效果往往越好。
文中举了个反直觉的例子,三个模型(A, B, C),识别的精确率分别是85%,80%和50%,A和B相关性很强,C和A, B的相关性很低,此时把A和B做集成是错误的,应该把A和C或者B和C做集成。
4、不同的模型如何确定权重?
不用动脑子的权重设置方法是等权重,动动脑子的方法有以下几个:
1. 计算多个base model的collinearity,基于得到的collinearity矩阵做model筛选,然后根据筛选出的model的cross validation score来确定model 的weight。 [这段话没有真正理解,需要实践来验证]
2. 利用单独的算法来确定权重,文中推荐了一篇文章 Finding Optimal Weights of Ensemble Learner using Neural Network 。
3. 可以借鉴其他算法,例如 Forward Selection of learners Selection with Replacement Bagging of ensemble methods 。
还可以到Kaggle上查找优秀的解决方案,学习那些方案中的ensemble方法。
5、ensemble模型有什么优势?
ensemble的优势在于两点:一是判别的精确率更高,二是模型更稳定,换一种说法是,ensemble可以减小偏差,减小方差,最终减小模型的泛化误差。
后记:ensemble learning方法本身不难理解,难在如何应用,待后续工作中有了应用案例再来写续篇。

