
Switch-based Active DDQ: 对任务型对话策略学习更有效的自适应规划

题目:Switch-based Active Deep Dyna-Q: Efficient Adaptive Planning for Task-Completion Dialogue Policy LearningLearning
作者:Yuexin Wu, Xiujun Li, Jingjing Liu, Jianfeng Gao, Yiming Yang
来源:AAAI 2019
链接:https://arxiv.org/pdf/1811.07550.pdf
Introduction
Problem
基于强化学习的任务型对话agent在训练时通常需要大量真实的user experience. Dyna-Q算法扩展了Q-learning,引入world model的概念,尝试用 world model 产生的simulated experience来有效促进agent的训练。但是Dyna-Q的质量取决于world model的质量,或者进一步说,取决于在学习过程中使用的real experience和simulated experience的比例。
本文引入一个switcher 去动态的决定在不同的训练阶段是用真实的还是模拟的experience.同时本文不同于以往的随机生成模拟经验,而采用了 active sampling策略,生成状态动作空间中未被agent完全探索的模拟经验。本文也是首次将active learning应用到任务型对话上。
Background
Dyna算法:Dyna算法框架并不是一个具体的强化学习算法,而是一类算法框架的总称。Dyna将基于模型的强化学习和不基于模型的强化学习集合起来,既从模型中学习,也从和环境交互的经历去学习,从而更新价值函数和(或)策略函数。
Dyna learns a model from real experience, learn and plan value function (policy) from real and simulated experience.(model-based)
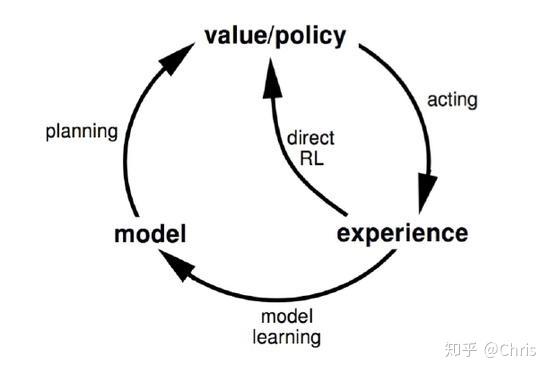

该方向的思路历程:
- Deep Dyna-Q: Integrating Planning for Task-Completion Dialogue Policy Learning
优点:只使用少量的真实用户交互数据,基于集成规划的方法针对任务完成型对话对对话策略进行学习。
缺点:在使用大量的模拟数据时,因为在开始阶段agent对低质量的experience不敏感,但在后期则会有很大影响,因为agent对噪声更敏感了(之前的解决方法是设置参数K,来控制planning的次数)。并且生成模拟经验时是通过均匀的抽样user goal,就存在有没被探索的状态动作空间。
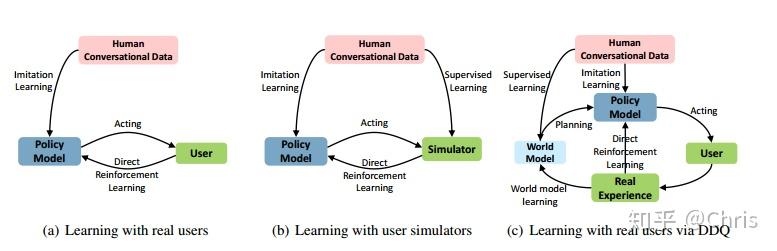

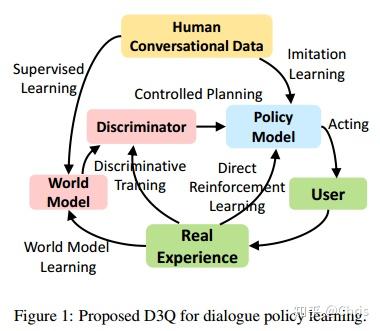
2. Discriminative Deep Dyna-Q: Robust Planning for Dialogue Policy Learning
3. Switch-based Active Deep Dyna-Q: Efficient Adaptive Planning for Task-Completion Dialogue Policy LearningLearning.
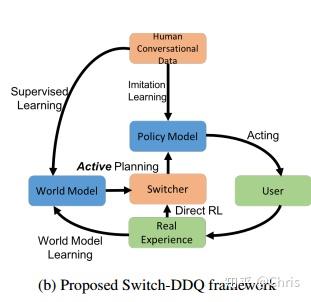
Model
基于Switch-DDQ的对话系统分为6个模块:
- 基于LSTM的NLU模块,识别对话意图,提取相关的slot
- state tracker, 用于追踪对话状态
- dialogue policy, 基于当前的对话状态选取下一个对话动作
- 基于模型的NLG模块,将对话动作转为自然语言
- World model, 用于生成模拟的user action和奖励基于动态选择的user goal
- 一个基于RNN的 Switcher
具体Switch-DDQ模型分为四个步骤:
(1) Direct Reinforcement Learning,即agent与真实用户交互,收集真实对话经验,完善对话策略;
(2) Active planning, agent与simulator进行交互,利用模拟经验改进策略
(2) World model learning,应用收集的真实对话经验进行world model的学习
(4) Switcher training: switcher是通过真实和模拟的经验来学习和改进的
进一步解释:


- Direct Reinforcement Learning
在这个步骤中基于真实对话经验,应用DQN来学习对话策略。
在每一步中,agent通过当前的对话状态 s , 通过最大化价值函数 Q(s,a; θ_Q) ,选择要执行的动作 a 。然后agent会接收到奖励 r ,以及用户的反馈 a_u,更新当前状态到 s' .存储经验 (s, a, r, a_u, s') 到经验池 B^u 。(line 12 in Algorithm 1)
Planning的过程也是基于相同的Q-learning算法,只是planning使用的是模拟的对话经验。
2. Active Planning based on World Model
Active user goal sampling module
在planning的阶段,world model可以选择性的生成模拟经验--在agent未被完全探索的状态动作空间。
假设我们已经从human-human的对话数据中收集了大量的user goal, 然后把user goal分成不同类别,有不同的限制条件和难度。在训练过程中,当监控验证集上agent的表现时,我们可以通过对话的成功率来收集每一类user goal对agent性能改进的影响,通过这样的信息来指导world model如何来选择user goal。


1.基于当前agent的表现,对话失败率 f_i 越高更意味着于注入了更难的情况(包含了更多需要学习的有用的信息)
2. 被估计为不稳定的类别(因为它被抽样的数量 n_i 小)可能有较高的失败率,因此值得分配更多的训练实例去降低不确定性。
关于user goal的选择概率 p_i 符合高斯分布,假设有 k 类user goal,每个类别在验证集的失败率为 f_i , 其取样的数量为 n_i ,总体的取样数量为 N=\sum_{i}^{}{n_i} , 设方差为 \sqrt{\frac{klnN}{n_i}} 作为 f_i 不确定性的度量, 上式则表示每一个user goal i 被选中的概率 p_i ,选择具有最大的p_i 作为选择的user goal。
Response generation module
用真实的对话数据来训练world model M(s,a; θ_M) ,使其能够产生模拟的对话经验。
在每个对话回合中,在world model输入当前对话状态 s 和上一轮的 agent action a ,从而生成用户的回复动作 a_u 、奖励 r 和一个表示对话是否结束的信号 t 。网络结构如图所示:两个 shared layer,三个 task specific layer用来完成分类任务。
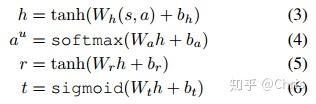
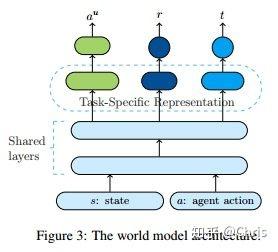
4. Switcher
Switcher基于一个二分类器,使用LSTM模型。假定一组对话是由一个序列的对话轮次构成的:
{(s_i; a_i; r_i)}, i = 1,...,N
N 是对话的轮次数,Q-learning中采用 (s, a, r, s^{'}) 作为一个训练样本,可以从一个对话中的两个连续对话轮次中提取。设计Switcher可以turn-based或者dialogue-based,因为基于轮次比基于对话数据量更大,所以本文选择turn-based,则对于给定的一组对话,对它的每一轮的质量进行打分,然后将每一轮的分数取平均来衡量这组对话的质量,如果对话层次的得分低于阈值,agent则转换成和real user来交流。
每一轮次的打分,需要把前面的轮次都考虑进去。给定一个对话轮次 (s_t, a_t, r_t) ,它的历史信息为 h = ((s_1, a_1, r_1), (s2, a2, r2), ..., (s_{t−1}, a_{t−1},r_{t−1})) ,用LSTM在隐藏层去编码历史信息 h ,最后通过一个sigmoid层输出基于轮次层次的质量分数。
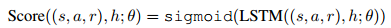
将交叉熵作为Score(.)训练的损失函数,其中 B^u 和 B^s 是分别存放真实经验和模拟经验的经验池。

由于B^u 和 B^s 中存储的经验会在对话训练过程中发生变化,所以switcher的分数函数也会随之更新,从而自动调整在不同训练阶段的planning的执行情况。
Experiment
Dataset
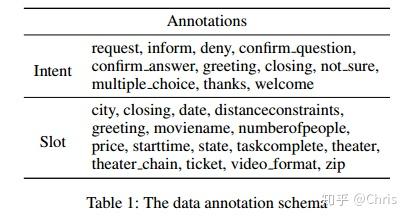
本文用到的数据集是电影订票场景中的原始会话数据,如表1所示,表1由11个对话动作和16个slot组成。数据集总共包含280个注释对话,每个对话的平均长度约为11轮。
Comparison
在电影票预订领域,对Switch-DDQ进行了两种评估:模拟和人工评估,在模拟评估中使用了开源的面向任务的用户模拟器(Li et al. 2016)。为了测试Switch-DDQ的性能,文中使用了不同版本的任务完成型对话agent。
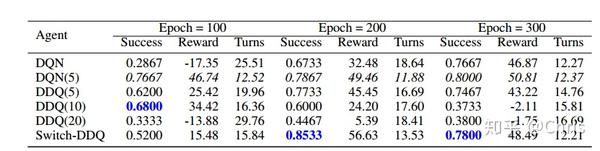

对于每个agent,文中以成功率、平均奖励和平均轮数展示实验的效果。如图所示,Switch- DDQ在前100个epoch后,在交互轮数较少的情况下,始终能够获得较高的成功率。
从实验结果也可以看出DDQ(5)所采用的策略,虽然在训练的早期帮助更快的更新策略网络,但是在后期由于使用了低质量的训练实例影响了性能,所以DDQ(5)无法获得与DQN类似的性能。然而,在Switch-DDQ中并不会出现这种情况,它没有参数K,因为实际和模拟的经验比例是由switcher模块自动控制。
Conclusion
本文主要在上一篇论文DDQ的基础上引入了 一个Switcher, Switch-DDQ能够自适应地从真实用户或world model 中选择要使用的数据源,提高了对话策略学习的效率和鲁棒性。Switch-DDQ也可以看作是一种基于模型的通用RL方法,并且很容易扩展到其他RL问题。
Reference
[1] Su, S.-Y.; Li, X.; Gao, J.; Liu, J.; andChen, Y.-N. 2018. Discriminative deep dyna-q: Robust planning for dialogue policy learning. arXiv preprint arXiv:1808.09442.
[2]Peng, B.; Li, X.; Gao, J.; Liu, J.; Wong, K.-F.; and Su, S.-Y. 2018. Deep Dyna-Q: Integrating planning for task-completion dialogue policy learning. In ACL
[3]Li, X.; Chen, Y.-N.; Li, L.; Gao, J.; and Celikyilmaz, A. 2017. End-to-end task-completion neural dialogue systems. arXiv preprint arXiv:1703.01008.
[4]Schatzmann, J.; Thomson, B.;Weilhammer, K.; Ye, H.; and Young, S. 2007. Agenda based user simulation for bootstrapping a pomdp dialogue system. In Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Companion Volume, Short Papers, 149–152. Association for Computational Linguistics.
[5] Chris:Deep Dyna-Q: 任务型对话策略学习的集成规划
