
神经架构搜索(NAS)简要介绍

简介
Deep Learning自从2016年发展到现在,越来越多的网络结构被研究出来解决不同领域的问题。每年的计算机几大Top会议的投稿量更是逐年攀升,研究热度和研究话题更是高速迭代。这些研究成果在产业界和我们生活中也逐渐成熟,我们身边可以用到的AI服务和产品也越来越多。但是,随着研究越来越复杂,深度网络的模型参数经常需要大量的调试,这并不是我们想要的结果,因此2017年的一篇文章引起的广大研究者的注意。他们用强化学习来优化神经网络的结构和参数,并从此开启了一个新的研究方向--神经架构搜索。
神经架构搜索(Neural Architecture Search,NAS)是人工智能领域近几年非常热的研究话题之一,在arxiv上和各大计算机顶会上的论文更是层出不穷。甚至短短几年时间综述文章和网上的解读文章也如雨后春笋一般涌现,似乎NAS一时间变得炙手可热。现有的文章都梳理的比较清晰,而且总结的也都很不错,各位可以去看看参考文献中列出的原文。既然现在文章这么多,资料也很丰富,这里就不去重复现有文章的观点了。这篇文章主要综合了一下现有的文献,并加上一些自己的理解,同时增加一些最新的研究内容。
(封面图来源:Neural Architecture Search: A Survey)
1. NAS的来龙去脉
NAS的意义在于解决深度学习模型的调参问题,是结合了优化和机器学习的交叉研究。在深度学习之前,传统的机器学模型习也会遇到模型的调参问题,因为浅层模型结构相对简单,因此多数研究都将模型的结构统一为超参数来进行搜索,比如三层神经网络中隐层神经元的个数。优化这些超参数的方法主要是黑箱优化方法,比如分别为进化优化,贝叶斯优化和强化学习等。
但是在模型规模扩大之后,超参数增多,这给优化问题带来了新的挑战。传统的方法遇到的问题主要有:结构编码方式无法代表复杂的网络结构搜索空间,编码空间过大导致这些搜索算法无法收敛,深度学习模型训练时间太长导致黑箱优化方法的计算效率降低等。总而言之,这个问题和研究思路早在90年代已经被很多学者研究过,但是新的时代使这个问题面临新的挑战,当然就需要重新研究一些方法来解决。
为了解决这些新的问题,NAS首次在2017年的ICML上被提出[1],并用强化学习的方法巧妙地解决的这个新问题。这里对NAS做一个简单的介绍,首先从回顾经典的超参算法说起。
2 传统神经网络的超参和结构优化
神经网络的超参调整一直是神经网络的一个重要问题,比如单隐层的前馈神经网络最重要的超参数为隐层神经元数量,不需要用优化算法,人为根据经验和试凑也是可以找到一个合适的超参数。
但是浅层神经网络的结构并不是只有单隐层的前馈神经网络一种,理论上任何链接结构都可以成为具有一定功能的神经网络,比如跨层链接和循环连接,比较典型的网络如循环神经网络(RNN),回声状态网络(ESN)等。因此,如果不局限于前馈网络,那么神经网络的结构也是一种超参数。
如果将结构同样考虑进来 ,那么就要涉及到将神经网络的结构映射到搜索空间的编码问题。在早期结构优化的研究中,结构编码作为构建搜索空间的重要步骤,也是一个主要的研究议题,只是其结构编码重点在于神经元之间,和神经元个数等。编码方式主要分为直接编码(即用相同维度的搜索代表网络结构,没有维度的压缩,映射关系简单 ),间接编码(用较低纬度的搜索空间间接代表更多维度的结构信息,映射关系较为复杂),生成编码(按照一定的规则通过较少的参数生成网络结构)等,更多具体的资料可以参考一篇 1999年的综述文章[2]。
传统网络结构优化最经典的算法应该是2002年的文章NEAT[3],它通过生长的变长基因编码的方式来编码网络结构。基因主要分为两个基因型,一个代表神经元的链接,一个代表了他们之间的权重,属于直接编码。文章用进化算法进行优化,定义了交叉和变异操作。
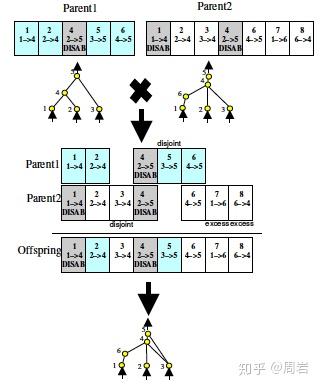
当神经元个数比较大时(一般来说超过50),NEAT的优化就比较吃力了。在NEAT的基础上,HyperNEAT通过引入CPPN来实现间接编码,从而将更大规模的网络结构编码到搜索空间中。
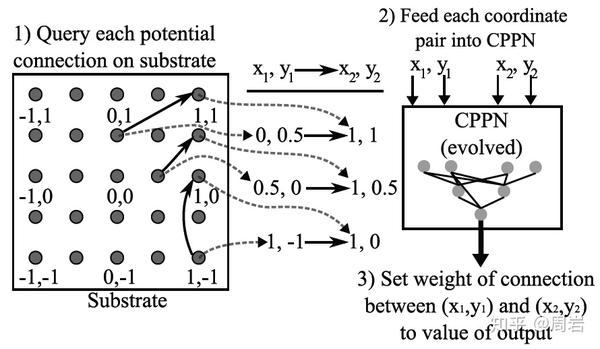

早期结构搜索的研究还有很多,感兴趣可以参考综述和一些相关的文章。
3 深度学习中的网络结构搜索
深度学习的结构搜索是近4年来重新被人们注意起来的方向。最出名的工作2017年用强化学习来优化网络结构的文章[1],从此开始了NAS研究的热潮。这几年NAS的发展很快,从arxiv上搜索就可以找到700+篇相关的文献,甚至单单是综述文章就已经有了4篇(可能还有更多)。比如2018[4, 7]年和2019[5]年发表的综述文章对NAS做了比较详细的概括,最新的一篇综述[6]发表于2019年底,概括的更加全面,墙裂建议想要详细了解的小伙伴去读一读原文。

另外这里有两个NAS的文章的汇总GitHub项目,各位也可以实时关注一下最新的研究成果:
https://github.com/D-X-Y/Awesome-NAS
https://github.com/hibayesian/awesome-automl-papers
NAS的主要研究问题可以总体上分为3个部分:构建搜索空间,优化算法以及模型评估。
对比传统网络的超参搜索,NAS主要的区别是深度网络结构搜索的重点在于如何拼接不同的结构模块和操作,以及如何降低模型评估的计算消耗。同时,近些年的研究趋势也集中在了将one-shot learning的思想引入进来减少模型评估的消耗,这个方法也被称为weight sharing[9]。在2019年,分层(Hierarchical)的思想[8]也逐渐成为了NAS的研究主流。
3.1 搜索空间
NAS的搜索空间被认为是一个神经网络搜索空间的一个带有约束子空间。NAS的搜索空间直接影响的优化的难度,NAS的研究重点之一就在于如何构造一个高效的搜索空间。由于深度学习的结构比较复杂,层次化的结构已经被证实十分有效,因此一开始的搜索空间的构造仍然以链式结构为主。链式搜索空间(chain-structured search space)首先被提出,主要的思想是将不同的操作单元组合在一起,这样的搜索空间也被称为全局搜索空间(Global search space)。Global search spaces 限制了神经网络的整体架构和链接方向,NAS需要调整的知识每一层所做的操作和对应的参数。每一层的操作有不同的选择,例如可以是卷积,池化,线性变换等。Global search spaces 相对来讲比较灵活,可以允许神经网络变换出各种结构(只要设计时允许跨层连接或者层间连接),但是问题也很明显,那就是巨大的搜索空间使得很多优化算法都没办法快速解决它。Global search spaces 带来了十分昂贵的计算代价。
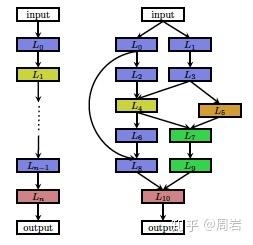


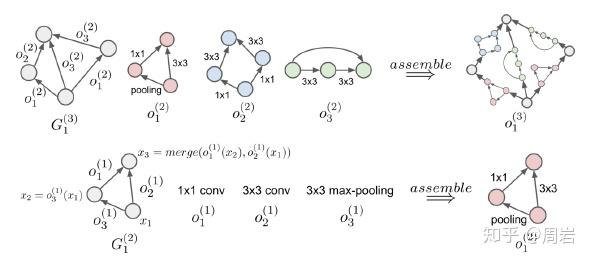
为了尽量减少计算消耗,不得不想办法减小搜索空间。后来主流的研究方法集中在了模块化网络结构并进行拼装(cell-based search space),这个思想主要来源于很多人工设计的结构具有很好效果,这样就可以整块的将网络结构进行组合,每一块具备一项功能,由NAS来决定每一块的位置和参数,这样一来搜索空间就降低了很多。这些cell都是一个小型的有向无环图(DAG),用来抽取和传递特征。
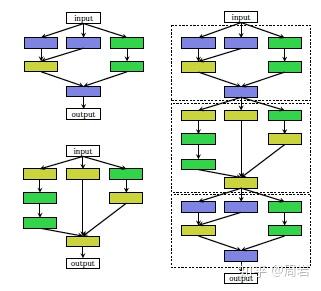


基于cell的方法虽然可以有效的缩减搜索空间,但是人们还是想到了另一种容易实现的方法来解决这个问题。如果cell作为一个层次,那么组合cell的结构也可以被看做一个层次,因此有研究人员就此提出了基于分层(Hierarchical)的思想。

虽然有了上述方法来减少搜索空间,但是迭代一次网络都需要从头开始训练,这样在训练每个模块参数上又会花费很多时间。因此有研究人员想到可以借助模型迁移的思想,减少每次迭代开始的时候的训练次数。在每次训练开始后,只用少量样本训练网络,也因此被称为one-short leanring(注意这里和transfer learning还是有区别的,transfer learning一般需要有一个source domain和一个target domain)。 比较出名的策略就是权重共享(weight sharing),这里每一个待评估的结构都会被当做一个整体网络的子网络,因此这些子网络中的权重可以通过整体网络来实现共享。那么只需要对整体网络的权重进行预训练就可以了。(这部分一般也被看作是一种模型评估的策略)
3.2 优化算法
NAS的优化对象是神经结构,比较适用的优化方法就是黑箱优化,它不需要具体的表达式,只需要知道优化目标和约束就可以了。黑箱优化中的base-line就是网格搜索(Grid search)和随机搜索(random search)。但是对于非常耗时的NAS来说,需要更高效的方法来减少搜索次数。
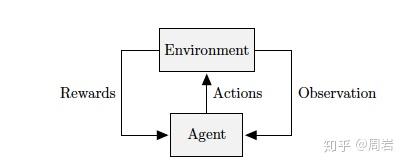
最早被用于NAS的搜索方法是强化学习(Reinforcement Learning)。强化学习将每一代的网络结构作为一个action,这个action的rewards就用这个模型的评估结果来表示。NAS中不同的强化学习算法表示的差别是如何设计agent的搜索策略。Zoph大神最初的文章是用RNN作为策略网络来序列化采集一个编码的网络结构。这里面比较常用的方法有REINFORCE、Q-Learning以及Monte Carlo Tree Search。
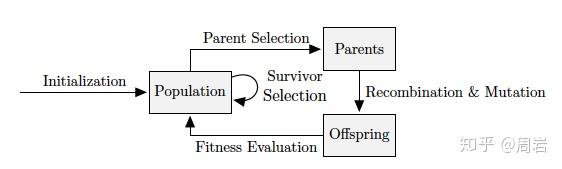
进化算法(Evolutionary Algorithms)是另一大类用于NAS的优化算法。不同于强化学习算法,进化算法是一种群体优化算法,算法的每一次迭代需要产生一定数量的子代个体,然后从这些个体中选出好的个体来产生一次迭代的个体。进化算法的操作算子主要包括:选择,交叉,变异。设计这些算子同样决定了算法的效率。

贝叶斯优化(Bayesian Optimization)是比较经典的超参优化方法,他通过建立一个超参的评估模型来预测最优值,在下一次迭代后评估最优值并更新预测模型。常用的预测模型有高斯过程(Gaussian Process)随机森林(Random forest)等。
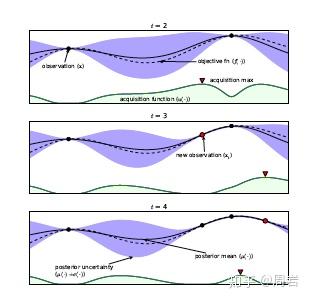
基于梯度(gradient-based)的方法是机器学习领域最经典的方法。相比于黑箱优化方法,梯度法的搜索速度更快,因此近期的NAS发展方向又重新回到了梯度法的怀抱。最经典的算法是2018年提出的DARTS[11],算法基于cell构建搜索空间,并将其连续化,这样就可以结合weight等超参数共同进行优化。优化的方法初次采用了双层优化的思路,将结构优化和weight的优化分离开来。
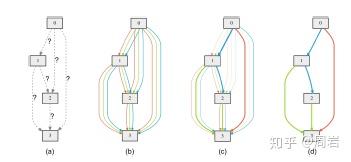
3.3 模型评估
模型评估占了NAS大部分的时间消耗,因此一些方法被用来优化这部分过程。首先被使用的方法是lower fidelity。这类方法包括缩短训练时间,用数据集的子集来训练,或者用低像素的数据等。然而这类方法的问题是对于结构的排序差异会随着数据的差异而扩大。
另外一种方法就是使用代理模型(Surrogate)。由于原模型的评估比较耗时,那么我们可以建立一个模型对个体进行估计,从而降低评估消耗。贝叶斯优化的中的模型评估就是一种代理模型,而且代理模型同样可以用在RL或者EA中。但是代理模型的一个问题就是模型管理[10]。模型越精确,那么就会更耗时,反之模型不精确则无法准确的估计子代的好坏,这是一个trade-off问题。另外,模型当然不是越精确越好,只要代理模型可以跟踪原模型的趋势,那么就可以准确的对个体进行排序,从而选择出好的个体。
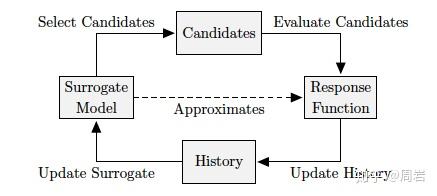

另外,之前介绍的one-short learning也是算是一种策略,由于只进行一次整体的pre-train,所以相当于对模型评估进行了优化。
3.4 算法对比
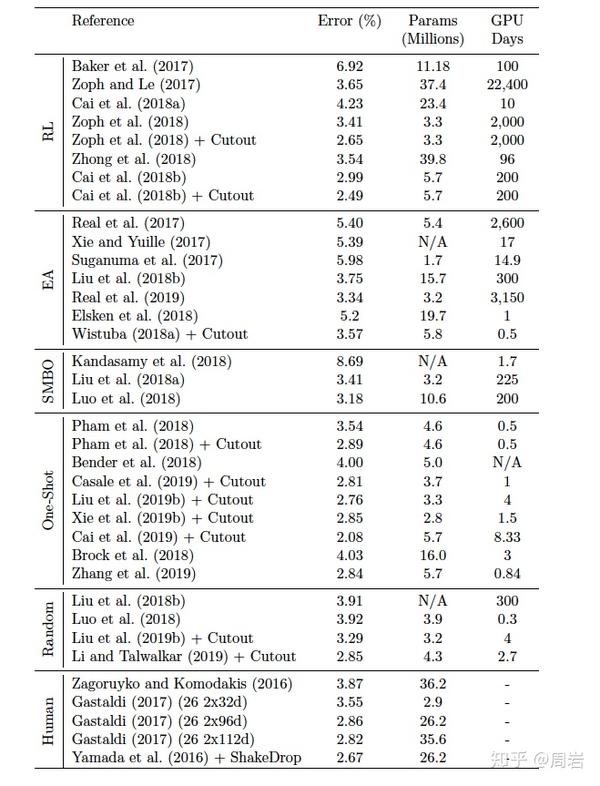
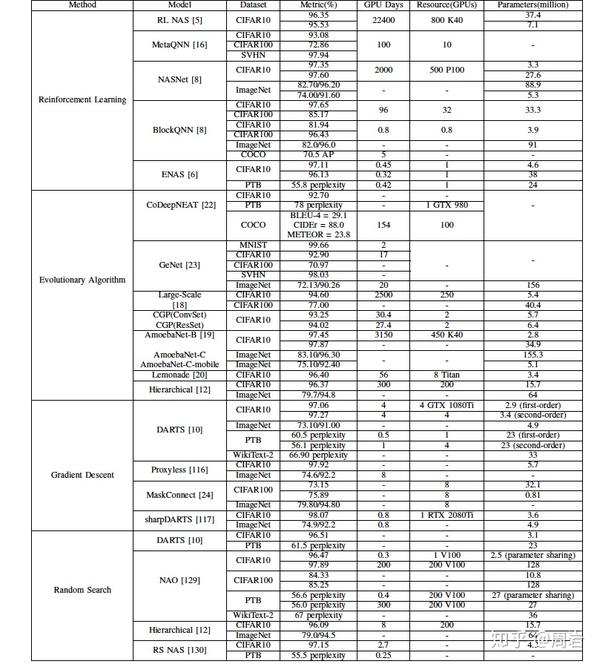
这里贴出了综述论文中总结的算法效果对比。


4. 结构搜索的最新研究
2020年已经过去了几个月,这段时间又有一些好的文章涌现,那么我们就找几篇比较好的来简单介绍一下。在大部分文章都在关注如何更快更省的进行NAS训练的时候,有一部分人从其他的角度在进行NAS研究。
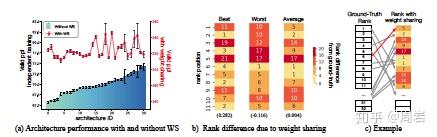
- 比如 ,文章(EVALUATING THE SEARCH PHASE OF NEURAL ARCHITECTURE SEARCH)对比了随机搜索和现有的NAS算法的效果,发现现有NAS研究的评估方法没用多个随机种子评估,同时指出这些方法并不能很好的超过随机搜索。另外研究中还发现weight share会导致候选者的排序会在评估中降低,并不能真正得到实际的排序。

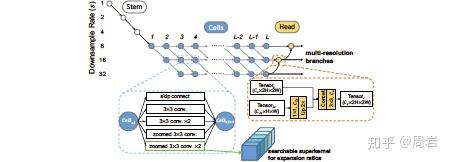
- 又比如这篇文章(FasterSeg: Searching for Faster Real-time Semantic Segmentation)关注了NAS再语义分割中的应用。文章介绍了用多分辨率分支的方法构建搜索空间,每个分辨率层都是最多由两种分辨率的结果作为输入,同时在每个分辨率有一个头部,中间的cell部分有对应了5中操作。文章的方法还包含了优化latency,还创新的应用了知识蒸馏将supernet的知识从复杂的teacher网络迁移到简单student网络。

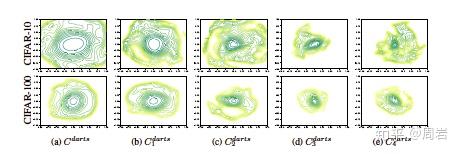
- 既然出了一些对NAS的质疑,那么就有人将NAS算在更多的数据集上做测试(Understanding and Robustifying Differentiable Architecture Search)。文章是基于DARTS算法来做的,由于DARTS在很多任务上表现不好,因此这篇文章在多个数据集上做了重新的测试。
- 还有人发现主流的算法都会发现一些好结构的共性(Understanding Architectures Learnt by Cell-based Neural Architecture Search),并根据这些共性来研究NAS收敛的规律和影响因素。文章定义了一个基本结构(在主流算法中出现的最大宽度的最小结构),以及描述结构的深度(最长链路)和宽度(与input相连的结构)。分析了共性链接结构和最快收敛速度的结构的收敛性。进一步通过分析loss landscape(lipschitz smoothness)、gradient variance来实验性的分析影响收敛性的因素。同时文中还给出了一些影响收敛性因素的理论分析。

5. 总结
目前的NAS研究依然比较火热,而且好的综述文章更是层出不穷,并且每一篇都有自己的角度来解读NAS的内容。作为一个业余研究NAS的人员,希望这篇文章能对想要了解这部分工作的同学有一个快速的帮助。
参考文献:
学术文章:
- ZOPH B, VASUDEVAN V, SHLENS J, et al. Learning Transferable Architectures for Scalable Image Recognition [J]. arXiv preprint arXiv:170707012, 2017,
- XIN Y. Evolving artificial neural networks [J]. Proceedings of the IEEE, 1999, 87(9): 1423-47.
- STANLEY K O, MIIKKULAINEN R. Evolving neural networks through augmenting topologies [J]. Evolutionary computation, 2002, 10(2): 99-127.
- ELSKEN T, METZEN J H, HUTTER F. Neural architecture search: A survey [J]. arXiv preprint arXiv:180805377, 2018,
- WISTUBA M, RAWAT A, PEDAPATI T. A Survey on Neural Architecture Search [J/OL] 2019, https://ui.adsabs.harvard.edu/abs/2019arXiv190501392W.
- He X, Zhao K, Chu X. AutoML: A Survey of the State-of-the-Art[J]. arXiv preprint arXiv:1908.00709, 2019.
- Yao Q, Wang M, Chen Y, et al. Taking human out of learning applications: A survey on automated machine learning[J]. arXiv preprint arXiv:1810.13306, 2018.
- Liu H, Simonyan K, Vinyals O, et al. Hierarchical representations for efficient architecture search[J]. arXiv preprint arXiv:1711.00436, 2017.
- Pham H, Guan M Y, Zoph B, et al. Efficient neural architecture search via parameter sharing[J]. arXiv preprint arXiv:1802.03268, 2018.
- Jin Y. Surrogate-assisted evolutionary computation: Recent advances and future challenges[J]. Swarm and Evolutionary Computation, 2011, 1(2): 61-70.
- Liu H, Simonyan K, Yang Y. Darts: Differentiable architecture search[J]. arXiv preprint arXiv:1806.09055, 2018.
其他公号/知乎/博客文章:
