强化学习在自动驾驶上有哪些应用?

这问题很有意思,但说来话长,这次邀请到达摩院自动驾驶实验室的小姐姐 @秋笑 来作答,希望能助您在强化学习领域谈笑风生。
1.概览
1.1 强化学习能做什么?
要回答“强化学习在自动驾驶里能做什么?”,首先要回答:“强化学习能做什么?”
2015年,Google DeepMind 提出的深度强化学习DQN算法,在 Atari游戏的得分上,以绝对优势领先人类选手。该算法发表于Nature,其强硬的表现,无异于向平静的湖面砸入一颗重石,瞬间波澜四起,大量学者们涌向强化学习领域。
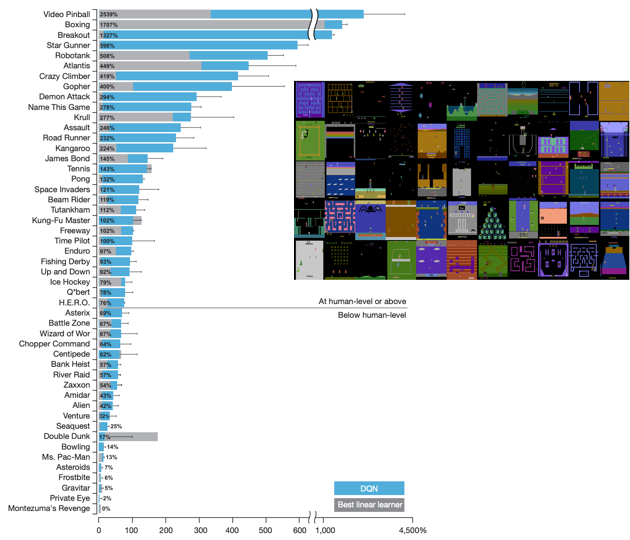

2016年, AlphaGo 在围棋上战胜职业九段棋手李世乭,次年升级架构后更战胜中国围棋现役第一人柯洁。随后, AlphaGo Zero 摆脱人类,只靠围棋规则和自我训练,便推演出了高明的走法,战胜了 AlphaGo。


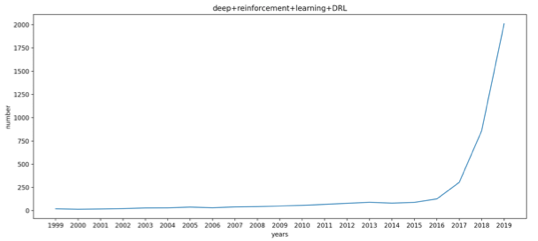
一场场的硬战打下来后,强化学习名声大噪,该领域的文章数量也呈现了指数式的增长。

从上面的故事里,我们可以得出结论:强化学习可以打游戏和下围棋。众所周知,在游戏和围棋里,玩家可以进行的操作 (Action)都是有限的,是离散的,比如,游戏里的上下左右,围棋里的交叉点。难道强化学习只能处理离散的 Action 吗?答案当然是否定的。
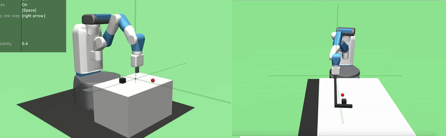
强化学习还被广泛用于机器人行走(Locomotion)和机械臂操作上。在机器人行走的任务上,强化学习会直接输出连续的控制量。


机械臂操作类似机器人行走,其 Action 空间也是连续的。此外,该类任务通常是 Goal-Oriented,比如要将抓取的物品移动到指定的位置(Goal)上。

1.2 强化学习在自动驾驶里的Demo
既然强化学习能用于机器人,那它当然也能用到自动驾驶上。MIT 和 CityU 等实验室,均有尝试用强化学习解决自动驾驶-末端物流里密集人流的场景。


- 点击查看 MIT Demo


- 点击查看CityU Demo
业界也提供了非常 powerful 的仿真工具,比如 DeepDrive 和 Carla 等


1.3 为什么要用强化学习
在我们搞清楚了“强化学习在自动驾驶能做什么后”,大家一定会想问“为什么要用强化学习来做?监督学习不可以吗?”
监督学习当然可以,只要我们能采集到人类专家的操作数据,就可以监督训练一个决策模型,约束其输出的行为和专家一样(Behavior Cloning)。但这样的方式,显然寻在以下两个问题:
- 当场景非常复杂,变化非常多时,需要采集的数据量会非常大,而专家数量有限,可想而知,采集成本会非常高。
- DQN 在 Atari 游戏上,大半都超越了人类水准,AlphaGo 战胜了围棋第一人,所以人的操作不一定是最好的,人的上限便是有监督学习的上限。
强化学习摆脱了人的限制,在计算机的仿真环境中,像人一样的试错,然后从错误中学习和成长。由于计算机的计算效率很高,因此强化学习的训练时间远超人类,理应学习出超越人类的模型。
2. 怎么使用强化学习?
在搞清楚了“为什么要用强化学习”后,大家一定蠢蠢欲动,想要了解“怎么用强化学习”了吧。接下来我会由浅入深,将强化学习的技术框架剖析给大家。
我们先从宏观上了解一下强化学习的思想。举个例子,如果我们养了一只猫猫,我们希望让猫猫走路,我们该怎么办呢?我们可以在猫猫走动时,给猫猫奖励小鱼干,在猫猫不走动时,就不给它小鱼干,通过小鱼干这种正向奖励,引导猫猫的行为满足我们的期望。
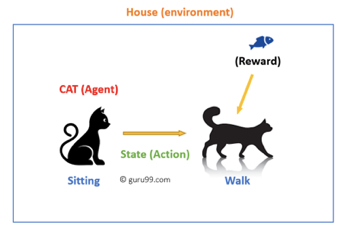

这种通过奖励/惩罚机制,引导 Agent (例子中的猫猫)作出符合我们期望的行为,便是强化学习的核心思想。该思想可以抽象为下图:Agent (被训练的模型)决策出 Action 后,Env(交互环境) 接收到 Action,然后转移到新的 Status(状态),同时对该 Action 给予 Reward(奖励/惩罚),agent 收到 Reward 后,修正决策(模型训练),并对新的 Status 继续决策。
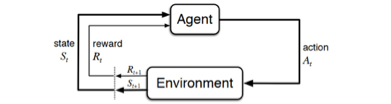

2.1 利用环境给予的 reward 修正决策模型 —— Q-learning Example
显然,强化学习思想的核心是“利用环境给予的 reward 修正决策模型”,接下来我们使用强化学习里比较简单的 Q-Learning 算法,一步步的讲清楚,这个修正要怎么修。
我们有一个简单的小游戏
- 它有五个连续的格子和一个蓝色的小球;
- 最左边的格子是起点,最右边的格子是终点;
- 蓝色的小球可以选择往前走一个格子,或往后退到起点;
- 环境有一定的概率,反向执行小球的选择(将前进执行为后退,将后退执行为前进)。
- 如果小球选择后退,可以得到 1 分作为 reward,如果选择前进,只有在进入终点时,才会得到 10 分的reward,否则 reward 为 0。
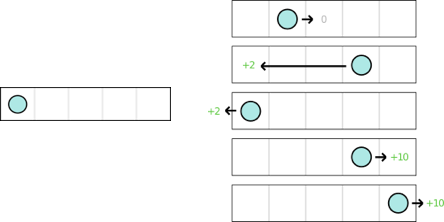

蓝色的小球和人一样,它喜欢 reward,希望能收获最多的 reward。我们给它一张 action-status 的表,来记录它收到过奖惩,这样它便可以选择具有最大奖励值的 Action;在这个例子中,我们有 2 个 Action(前进/后退),和 5 个 Status(Agent所在的格子),因此我们可以用一张 2*5 的表格来做记录。
我们先尝试记录每次选择 Action 后所得到的 reward,随着小球在环境中不断的探索,这张表会收敛成类似下图的形式:
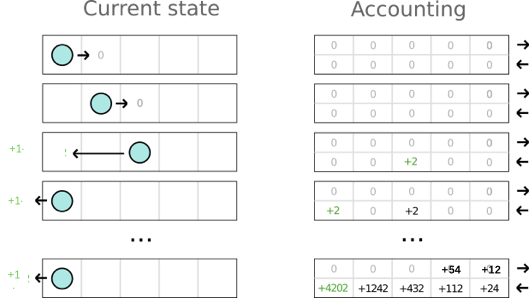

显然,小球被短期的利益蒙蔽了双眼,它为了得到短期的 1 分的 reward,贪婪的选择后退,而忽视了能得到 10 分的 reward 的 Action。为此,我们希望小球把目光放长远一些,比如,将连续 n 步 reward 以 discouting 的方式相加值的期望,其中 gamma 是折扣因子:
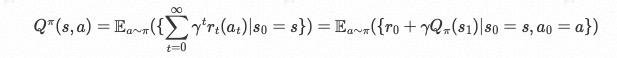

这种方式固然合理,但其中涉及了 n 步 reward 的和的期望,如果通过采样的方式去做估计(MC思想),效率会非常低;如果不想采样,还想计算期望,那就只能用概率进行计算(DP思想),然而我们很难得知环境的转移及转移概率,因此我们只能通过近似的方式(TD思想),去逼近期望,以避免采样或学习环境。
在TD 思想下,Q值的计算公式如下:


通过上述公式,对action-status 表中的 Q 值进行更新。等收敛后,在每一个状态下,前进的 Action 的值都会高于后退,此时小球的决策具有了长远的目光,这便是 Q-Learning 利用 Reward 修正决策模型的方式。
2.2 强化学习框架再介绍
上述介绍的强化学习,主要涉及下图中绿色的部分,即选 Action 的策略(比如选 Q 值最大的 Action) 和用环境给予的 reward 计算长线 Return (比如 V值/ Q值),这两个部分呢是 Model Free 所关注的。这里的 Model 大家可以理解为环境模型。Model Rree 的意思是,将环境作为黑盒,不依赖(Free)环境的变化规律,与其相对的,依赖于环境变化规律的算法,就是 Model Based了。
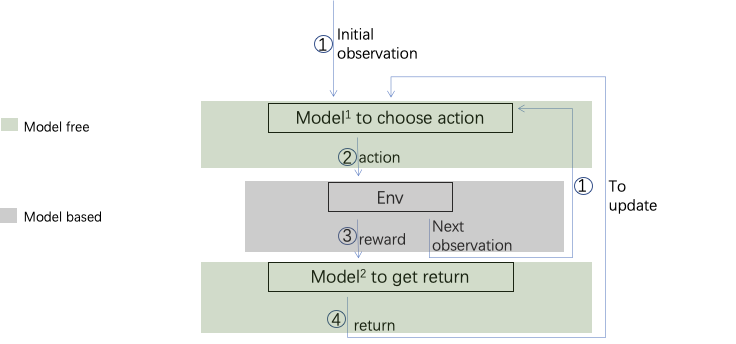

我们在这里主要向大家介绍 Model Free的方法。 Model Free 类的方法,主要就在做两件事情:利用经验,和有效探索。
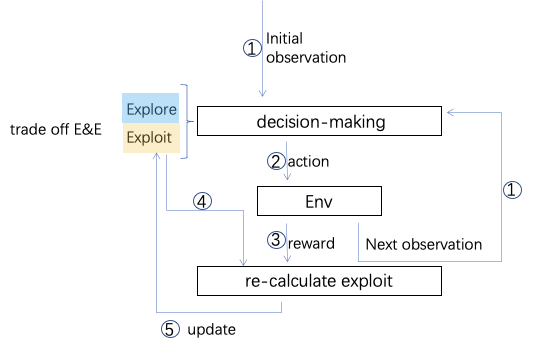

举个例子,如果我们搬到一个新园区,我们想要吃好吃的,我们怎么办呢?我们会随机的先选几家尝尝,然后在里面选出味道最好吃的一家后,那么以后吃饭时,可以就吃最好吃的这家(利用经验),但万一没吃过的店里,有更好吃的呢?所以我们需要做探索。在探索时呢,我们可以忽略一些店面脏乱的,这样可以提升探索的效率(有效探索)。
3. 强化学习在自动驾驶的应用
3.1 自动驾驶的规划/决策模块
自动驾驶的算法流程如下图所示,感知和定位模块将传感器信息转换为带物理性质的结构化信息(e.g.障碍物的位置,尺寸,自车位置等),这些信息和地图及预测信息一起传入决策规划模块后,生成了自动驾驶车辆的驾驶轨迹,最后轨迹被控制模块驱动车辆执行;
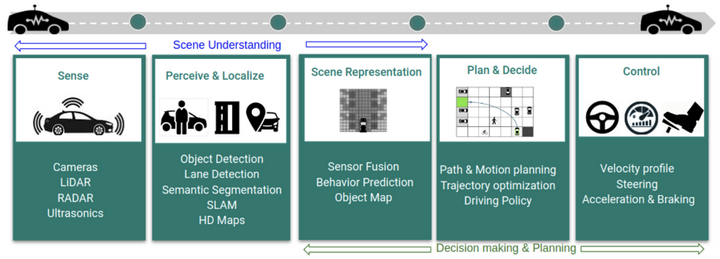

感知和定位模块类似人类驾驶员的“双眼”,决策/规划模块则类似“大脑”。业界主流的“大脑”通常是人类专家编写的规则代码,也被称为专家系统。其可以应对很多常见的驾驶场景,但在无人驾驶需要处理的重点和难题corner cases中遇到了麻烦。
由于corner cases中的交互对象的行为通常是非确定性的,甚至是博弈性的,所以专家系统很难很好地应对此类场景。Learning-based强化学习技术在此类场景中展现了极高的潜力,被探索以应用到决策/规划模块中,以增强自动驾驶车辆的智能性,解决其corner cases。
3.2 智能仿真平台
自动驾驶算法在仿真平台进行线上测试,其相比于线下人工测试,有更低的成本和更高的效率。仿真场景中动态障碍物越丰富和智能,测试效果越好。然而,其面对着与自动驾驶相似的问题:如何提升障碍物在强交互场景中的智能性。因此,强化学习算法也被应用到仿真场景的智能交互上,而这也是我们的研发方向之一。
 达摩院自动驾驶混合仿真测试平台https://www.zhihu.com/video/1423969158828138496
达摩院自动驾驶混合仿真测试平台https://www.zhihu.com/video/14239691588281384963.3 优化专家系统参数
除了使用强化学习算法直接提升智能性外,还可以使用逆强化学习来优化专家系统中的超参,以通过数据驱动的方式来提升专家系统的表现,不少自动驾驶公司也有探索过此方向。
4. 自动驾驶领域的强化学习算法
自动驾驶系统一般是层次化的复杂系统,强化学习在自动驾驶中可以和不同层次的模块结合,来完成决策规划。例如,强化学习可以使用原始相机和Lidar信息,输出behaviour层面的决策;也可以采用预处理过的感知信息,比如鸟瞰图,输出规划的轨迹信息,等等;
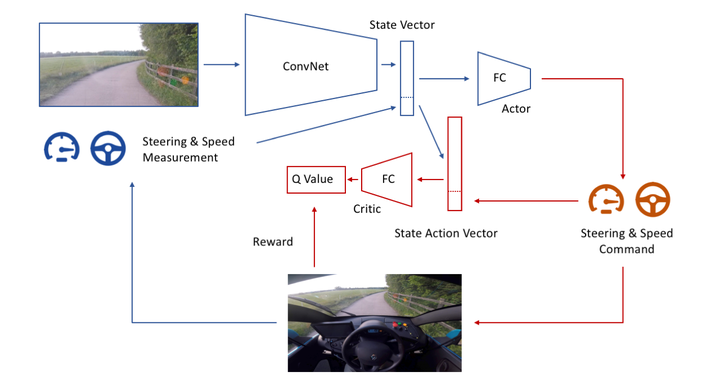

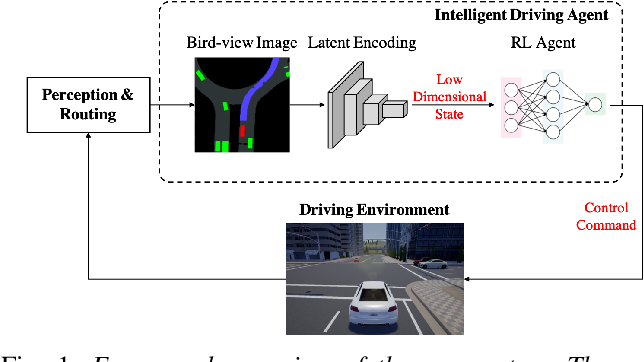

4.1 不同类型的输入
强化学习算法有不同类型和不同格式的输入,比如自车的位置和速度等物理信息、感知模块处理后的鸟瞰图或处理前原始相机信息等,具体分类见下表;
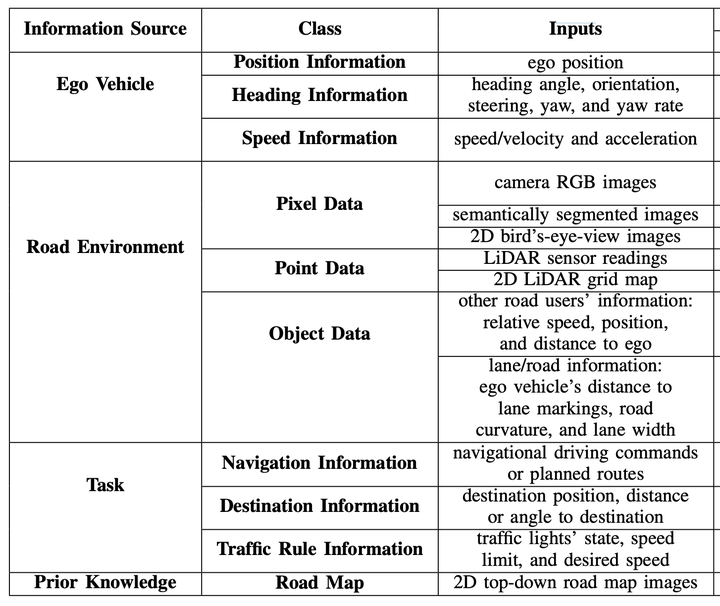

4.2 不同类型的输出
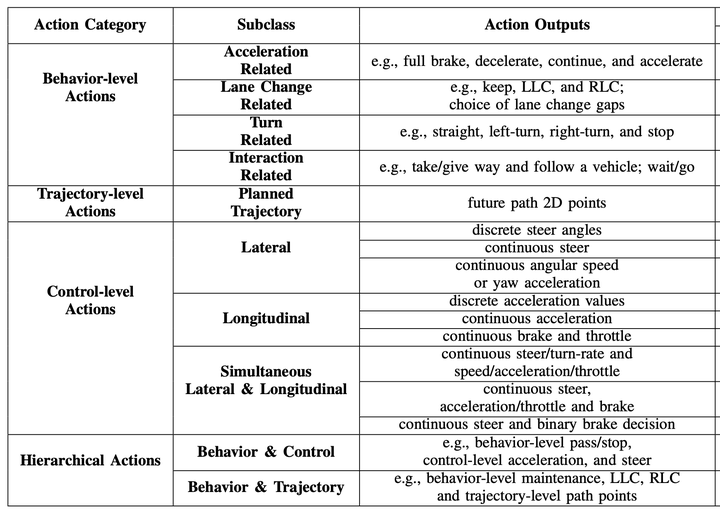
针对不同应用层次,强化学习算法有不同类型输出,比如决策、轨迹、控制量和目标点等,具体分类见下表;

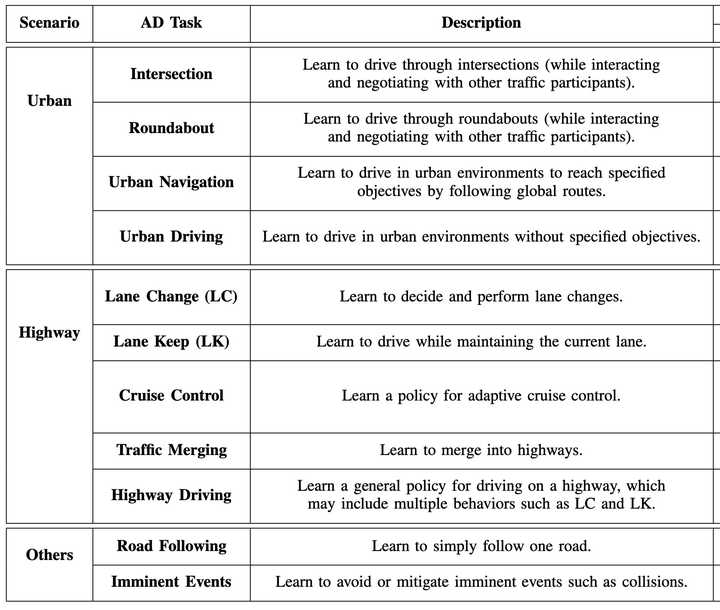
4.3 不同类型的场景
针对不同的自动驾驶的任务,强化学习可以在下列不同的场景中训练;

5. 挑战
5.1 复杂交互场景下的智能性
强化学习在自动驾驶的决策规划中的一个重要任务就是在复杂交互场景中做出安全且合理的决策规划,常见的复杂交互场景例如窄路会车,分道合道,无保护左转,环岛等,很难用传统的规划决策算法来很好的解决。强化学习与仿真交互产生学习到的连续决策能力将会是有效的解决方案。
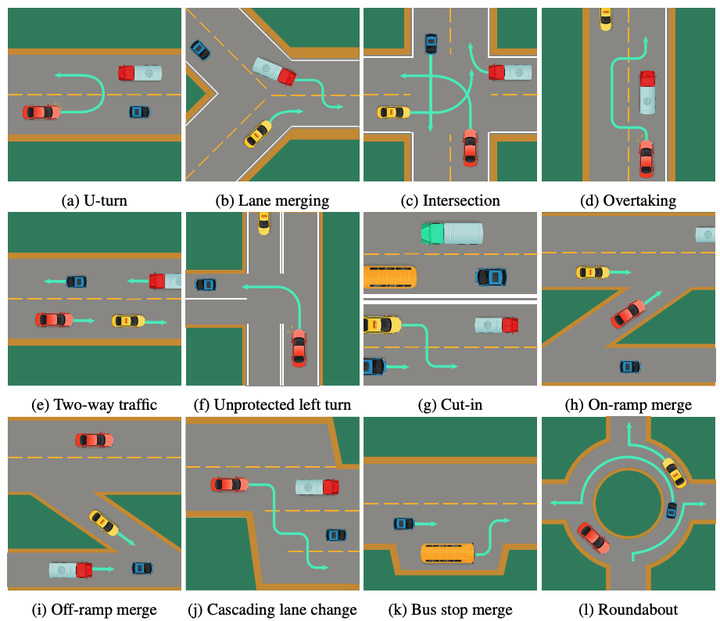

5.2 多样化的智能性
一般来说,自动驾驶车辆的智能性目标为高效&安全。但是,对于仿真场景的智能体来说,它们需要更丰富的行为模式,来保证对真实世界里驾驶员的行为模式有很好的表现和覆盖,以达到更好的模拟真实世界驾驶场景的目标,增强仿真场景的行为模式的真实性。比如,智能体需要表现出不安全的高效,或者保守的低效行为模式,以此模拟出真实世界内不同性格的人类驾驶员;


5.3 提高泛化性 & 安全性
Learning-based 类算法几乎都绕不开泛化性这一难题,在自动驾驶任务里,需要泛化各种不同的道路环境、交互障碍物尺寸、数量、位置、行为等等;此外,Learning-based 类算法的黑盒属性令其难以保证绝对安全,因此如何提高安全性也是关键任务;
5.4 落地实车
从仿真训练测试到实车落地是一个典型的Sim-to-Real问题,强化学习从仿真到现实世界往往会遇到数据偏移和模型偏差。在自动驾驶的问题下,Sim-to-Real需要解决这几个方面的问题:
一是感知方面,真实世界和仿真环境的感知信号存在着数据偏移;
二是环境交互模型方面,真实世界和仿真环境的物理学模型会存在一点的偏差;
三是行为模式方面,真实世界里的车辆和行人的行为模式很可能与仿真环境不一致,一些细粒度的交互(例如眼神,手势)无法在仿真环境里面有效建模。Sim-to-Real的gap通常可以通过domain adaptation,domain randomization(例如感知)和system learning/identification(例如环境模型)来一定程度上减轻,但完全消除Sim-to-Real的gap仍然具有挑战。
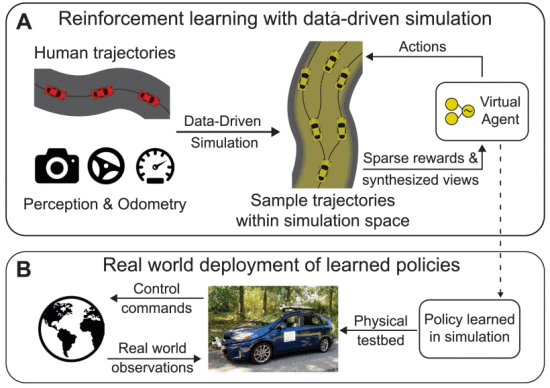

像我们实验室在研发末端物流无人车“小蛮驴”时,就会遇到大量的非结构化的挑战,比如井盖、减速带、路桩,还有各种意想不到的障碍物…


以上,如果有说的不对or不清楚的地方,欢迎指正。
--------
文中图片及论述部分参考:
https://zh.wikipedia.org/wiki/%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0
https://arxiv.org/pdf/2002.00444.pdf
https://github.com/huawei-noah/SMARTS
https://arxiv.org/pdf/1808.04913.pdf
https://arxiv.org/pdf/2101.01993.pdf
https://lilianweng.github.io/lil-log/2019/05/05/domain-randomization.html
https://arxiv.org/pdf/1703.06907.pdf
https://leaderboard.carla.org/scenarios/
ps 达摩院自动驾驶实验室正在招聘研究型实习生,欢迎感兴趣的同学加入我们