拜读TNNLS论文——关于Transductive ZSL
给自己立了一个flag,每周精度一篇TNNLS的论文。但当我终于在众多文章里选好一篇相关的论文,一看到满篇的公式和文字。。。嗯,加油!今天是对下面这篇文章的理解,有不对的地方,还望大家指出、讨论~
Yu Y, Ji Z, Guo J, et al. Transductive zero-shot learning with adaptive structural embedding[J]. IEEE transactions on neural networks and learning systems, 2018, 29(9): 4116-4127.
言归正传,这一篇还是与Zero-shot Learning相关的论文,一个基于自适应结构嵌入(Adaptive Structural Embedding)的直推式ZSL(Transductive Zero-Shot Learning, 后面简称TZSL)的论文。这里先补充几个关于ZSL的概念问题。
1)ZSL:Recognize the unseen categories that no labeled data are available for training, i.e., the categories in training and testing are disjoint. 即识别一些在训练集没有见过的类,拿CUB的数据集举例,我训练的都是乌鸦、喜鹊等鸟类,测试的时候要去识别啄木鸟,训练集和测试集的物体类是没有交集的。
2)TZSL:Transductive ZSL,可以翻译为直推式ZSL,简单来说,就是会把有标签的训练集和没有标签的测试集数据都用于训练,这样可以得到测试集类别的先验知识。同样用上面的例子说明,我训练的时候,可以把啄木鸟的图片和对应的属性都拿来训练,但是没有标签的监督信息指导我。就好比我带你去动物园,让你看见各种动物,并且给你描述他的模样,但不告诉你,这是什么动物。
3)Inductive ZSL: 归纳式ZSL,则是只用有标签的训练集用于训练。
================Abstract===================
该篇论文,则是致力于解决TZSL的问题。
摘要里提到,ZSL赋予了计算机视觉系统的推理能力,其面临的最基本的两个挑战是:visual-semantic embedding,和在跨模态学习以及unseen类的预测步骤中存在的问题——domain adaptation。为了分别应对这两个挑战,作者提出了两个对应的方法和一个训练方法:
1)Adaptive STructural Embedding (ASTE) ,在一个latent structural 的SVM结构中建立视觉和语义的交互关系(visual-semantic interactions),自适应的调整松弛变量(slack variables),以体现训练实例之间的不同可靠性(reliableness)。这样一来,对可靠的实例处以较小的惩罚,而对不太可靠的实例处以更严厉的惩罚。因此,ASTE可以确保更有辨别性的嵌入。
2)Self-PAsed Selective Strategy (SPASS),它提供了一个框架来缓解ZSL中的域转移(domain shift)问题,它用一种容易实现的方式处理unseen 类的数据。特别地,SPASS借用了self-paced learning的思想,通过迭代地从可靠到不太可靠地选择unseen实例,以逐渐地将知识从seen域转移到unseen域。
3)通过结合SPASS和ASTE,作者还提出了一种self-paced Transductive ASTE (TASTE)方法,以逐步增强分类能力。在三个基准数据集(即AwA、CUB和aPY)上的大量实验证明了ASTE和TASTE的优越性。此外,作者还提出了一种快速训练(Fast Training, FT)策略来提高大多数现有ZSL方法的效率。FT策略出乎意料地简单且足够通用,可以在保持先前性能的同时将大多数现有方法的训练时间加快4-300倍。
================Introduction===================
看完摘要,感觉干货满满,下面就来认真了解一下前面提到的这些方法的本质吧~
引用的常规操作,先讲ZSL的重要性和挑战,然后指出 semantic vectors 对于ZSL的重要性,即一个语义空间的建立是为了联系seen类和unseen类之间的语义关系,从而,the knowledge可以从seen类的空间转移到unseen类的语义空间。常见的语义向量semantic vectors有Attributes和word vectors。
利用semantic vectors,图像视觉特征和语义向量之间的跨模态关系就可以通过从视觉空间到语义空间的视觉语义嵌入得到,反之亦然,或者是一个共享的公共空间。很多有效的方法就是构建一个visual-semantic embedding,从这个角度可以分为:linear-based 、nonlinear-based 、bilinear-based 和max margin-based 四种方法。其中,max margin-based 方法(这也是我入坑ZSL时最先了解的方法),提出了一个ranking函数,用来衡量图像和class semantic vectors之间的相似度,也叫兼容性分数(compatibility scores),通过强制匹配对的分数高于不匹配的图像和semantic vector对来得到一个兼容性矩阵(compatibility matrix)。但是,这种方法存在这样的问题:即在训练过程中,可见类的实例的处理不会考虑它们的不同可靠性,即seen 类的数据的结构信息可能被破坏。为了应对这个问题,作者提出了ASTE方法,在一个latent structural 的SVM结构中建立视觉和语义的交互关系,自适应的调整松弛变量,以体现训练实例之间的不同可靠性。这样一来,对可靠的实例处以较小的惩罚,而对不太可靠的实例处以更严厉的惩罚。通过这种方式,通过评估seen data的可靠性和可区分性,可以有效构建seen data的结构信息。
在embedding之后,也就是测试的时候,一个unseen类的实例的标签则通过在那个embedding space空间中进行最近邻居(nearest neighbor, NN)搜索得到,即距离该图片特征向量最近的语义特征向量的标签就是该unseen图片的预测结果。但是,由于seen类和unseen类是不同的,甚至可能不相关,因此当直接将seen类的embedding space应用于unseen 数据时,是会出现偏置(bias)问题的。这也就是ZSL中的另一个研究热点——domain shift problem(领域漂移问题)。为了减缓这种偏置问题,很多TZSL方法被提出,即用unseen和seen的数据一起训练,为学习到更general的visual-semantic embedding,从而提高分类性能。但作者认为这种方法会忽略或者低估潜在的标签信息(这里不太明白)。作者提出了一个简单的方法来获得unseen 数据的潜在标签,该方法分为两步:1)学习seen 数据的visual-semantic embedding; 2)以迭代的方式,逐步细化seen数据和unseen数据的visual-semantic embedding。在每次迭代中,首先用当前visual-semantic embedding对unseen数据进行预测,然后用自定步长选择策略(self-paced selective strategy)选择可靠的unseen实例作为伪标签数据,然后将伪标记数据添加到有标签的数据集中,对视觉语义嵌入进行细化。通过这种方式,就可以实现知识的自适应转移。同时,以有信心的方式利用unseen数据的潜在标签信息,从而可以容易地解决域移位问题
该论文的贡献点可以总结为三点,也正是摘要里提到过的,这里就不赘述了。
================Related Work===================
作者根据要解决的两大问题:Visual-semantic embedding 和 Domain shift展开了调研。
首先是Visual-semantic embedding,这是ZSL的关键技术,决定了knowledge能否成功的从seen domain转移到unseen domain。作者主要讲了四类比较出名的方法:1)最基本的两个visual-attributes嵌入范例——Direct Attribute Prediction (DAP) 和 Indirect Attribute Prediction (IAP)[1],研究ZSL的应该都知道,就不多讲了,这里提他主要是关注它的semantic是attitude的。2)第一个提出用word vector作为semantic的,并提出nonlinear方法的[2]。3)相比第二类,该类方法则是训练了linear mapping,来将image和word vector联系起来,经典的模型是DeViSE[3],他用文本和图像特征向量的内积(dot-product,两个向量的内积为一个常量哟)来表示他们的相似度,并让匹配对的相似分数高于其他所有不匹配的对的分数。4)类似DeViSE模型,还有bilinear的方法被提出,经典的有SJE模型[12],前面Introduction有提到。(个人觉得,这一段写得很漂亮,既涵盖了很多与Visual-semantic embedding相关的研究工作,又环环相扣、逻辑清晰的列出这些工作的关系与差别,一气呵成。)
与作者提出的ASTE类似的工作,一是ESZSL[5],它利用双线性模型构造了一个通用的框架,用于对视觉特征、类属性和类标签之间的关系进行建模,并且通过封闭式的求解使其有效。ASTE除了考虑这三者之间的关系,还通过max-margin model来惩罚不正确的预测,以此来捕获discriminantive的类间inter-class信息。另一个工作是[6]中提到方法,即将ZSL当作一个在seen data上的标准的半监督学习(semi-supervised learning)问题,和在unseen data 上的非监督聚类(unsupervised clustering)问题,并将这两个问题集成到一个潜在的max-margin多分类框架中。作者在该max-margin多分类框架的基础上,通过latent 结构的SVM框架来训练数据的不同可靠性,从而学习到更有区分性的嵌入(discriminative embedding)。此外,在作者提出的transductive framework中,通过构造seen和unseen数据之间的相互作用来逐渐开发unseen数据的潜在标签信息,而不是使用无监督聚类方法开发unseen数据的结构信息。
然后是Domain shift问题,由于从seen数据中学习的嵌入函数直接应用于unseen数据时会有偏差,因此会出现域漂移问题,从而影响unseen数据的分类效果。而Domain shift产生的原因,主要是由于投影偏移(projection shift)而不是特征分布偏移(feature distribution shift)。当然,作为ZSL的一大问题,这里也有很多成功的尝试方案。一是采用带有更多类别和实例的大量附加数据来扩大所见数据[7],我理解的是用ImageNet的数据预训练图像特征提取网络。另一种方法是从迁移学习领域借用了重要性加权(importance weighting,)概率。其背后的思想是增强与unseen的数据相关的那些数据的影响,以期望更好的嵌入泛化能力。近年来,又开始研究精细的TZSL用于纠正Domain shift问题,涉及的一些细节就不讲了。区别于那些精细的TZSL,作者提出的TASTE先用在seen数据上训练好的visual-semantic embedding来预测unseen数据的标签,然后用迭代的方式去调整visual-semantic embedding,这个过程种可以通过高度可靠的实例逐步增强分类能力。
下面就来看看作者提出的ASTE、SPASS、TASTE究竟是怎么实现的,相比这些related work,是否真的存在这些提到的优点呢~
================proposed approach==================
A、ASTE
首先介绍一些后面会用到的符号:
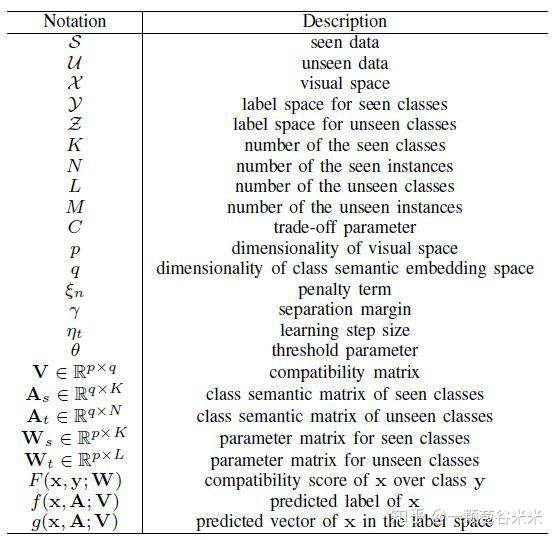

其中,包含K个类的seen数据集表示为 S = \{(x_n, y_n), n = 1, ...,N\} ,其中x为图像特征;y为label,是以one-hot的方式表示的;N是seen data的数量。ZSL的目的就在于通过最小化在seen data上的经验风险 \frac{1}{N}\sum_{n=1}^{N}{l(y_n,f(x_n))} ,来学习视觉空间 X 到结构标签空间 Y 的映射关系: f: X \rightarrow Y 。作者定义了一个compatibility 函数 F : X × Y \rightarrow R ,也就是匹配分数,来衡量一个图片特征向量和一个semantic之间的相似度,即计算两个向量的内积,如下公式所示:
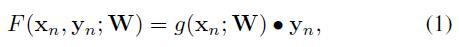

上面的公式也可以写成下面这种双线性格式(bilinear form):
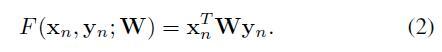

因此,测试的时候,就是给一张图片 x ,找到使得 F 分数最高的 y 就是预测的结果啦:
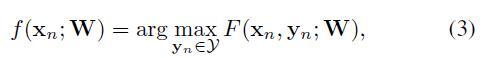

为了实现知识转移,作者假设每个类别的参数向量都可以从它的类语义向量中得到,因为它提供了相应的类的属性。即用类语义向量 a 来表示前面的参数向量 w ,因此上面的兼容性函数也可以写成下面这种格式:
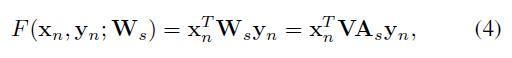

现在,关键问题就变成在seen data里学习兼容性矩阵 W 。与其他方法一样,ASTE也是通过强制匹配对的分数大于不匹配对的分来来学习,即:
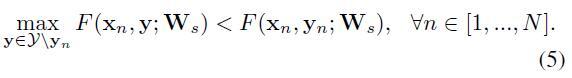

下面的内容就会涉及到SVM的一些知识,如松弛变量(slack variable)和惩罚项(penalty term),所以这里先穿插一些概念介绍,对理解后面的公式很有帮助。
============ 松弛变量 & 惩罚项==============
我们先大概理一下松弛变量和惩罚项这两个概念(参考的是CSDN的一篇博客,感兴趣的可以去了解一下:SVM学习(五):松弛变量与惩罚因子 - Liam Q的专栏 - CSDN博客 。
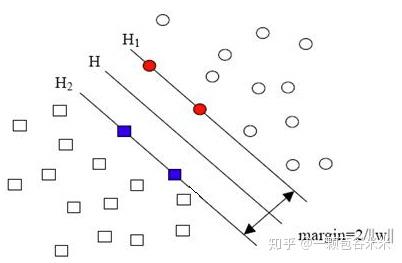
SVM是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,其学习策略是间隔最大化,最终可转化为一个凸二次规划问题的求解。(对SVM不了解可以看看【理论】支持向量机通俗导论(理解SVM的三层境界) - zhazhiqiang2010的专栏 - CSDN博客这个博客,干货满满)一个本来线性不可分的分类问题,通过SVM可以映射到高维空间而变成了线性可分的,S如下图所示(其中方形和圆形就分别代表两类数据):
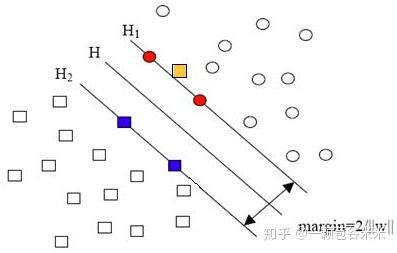
但是有可能出现这种一个单独的样本就使得原本线性可分的问题变成了线性不可分的。如下图所示,这类仅有少数点线性不可分的也叫近似线性可分。
为了解决这样的问题,我们可以允许这些可能是错误的或者噪声点在分类平面的距离不满足原先的要求。由于不同的训练集各点的间距尺度不太一样,因此用函数间隔Functional margin(而不是几何间隔Geometrical margin)来衡量有利于表达形式的简洁。而函数间隔就是标签值乘上预测结果 yf(x) 。即在原来样本要求的基础上,我们给阈值1加上一个松弛变量 \xi ,即允许:
y_i[(wx_i)+b]\geq1-\xi_i (where, i=1,2,...,N; \xi_i\geq0)
因为松弛变量是非负的,因此最终的结果是要求间隔可以比1小。但是当某些点出现这种间隔比1小的情况时(这些点也叫离群点),意味着我们放弃了对这些点的精确分类,但使分类面不必向这些点的方向移动,因而可以得到更大的几何间隔(在低维空间看来,分类边界也更平滑)。然后再考虑原始的几何间隔分类对应的优化问题:


||w||^2 就是我们的目标函数,即在满足分类正确的前提下,让函数间隔越大越好,也就对应||w||^2越小越好。回到刚刚的问题,对于那种情况,我们会给它加上一个非负的损失,一般有两种形式: \sum_{i=1}^{N}{\xi_i^2} 或 \sum_{i=1}^{N}{\xi_i} ,其中N就是样本的个数。除了损失,还需要一个惩罚因子 C ,所以,最后的优化问题就变成了下面这样:
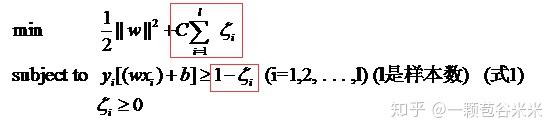

有几个值得注意的点,对理解这个公式以及文章中提到的都很有帮助(这几个点都是上面提到的SVM学习博客总结的):
(1)实际上只有“离群点”样本才有一个松弛变量与其对应。
(2)松弛变量的值实际上标示出了对应的点到底离群有多远,值越大,点就越远。
(3)惩罚因子C决定了你有多重视离群点带来的损失,显然当所有离群点的松弛变量的和一定时,你定的C越大,对目标函数的损失也越大。
(4)惩罚因子C不是一个变量,而是事先指定的定值。
==============回到正文===================
回到主题,如果只让让匹配对的分数比不匹配的大还不够,还要大到一定的值。根据SVM中的maximum-margin 原则,作者提出一个兼容性矩阵 V 让separation margin \gamma (这个值是排名第一即匹配对的分数与排名第二的分数之间差异的最小值,即 \gamma = F(x_n, y_n;W_s)−max_{y\in Y /y_n} F(x_n, y;W_s))最大。限制类参数向量 w_l(x_n) 的 l_2 二范就可以把问题转换为下面的优化问题:
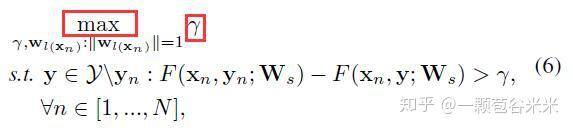

该问题也可以等价地表示为标准形式的凸二次问题(convex quadratic problem),和前面的几何间隔分类对应的优化问题是不是很像:
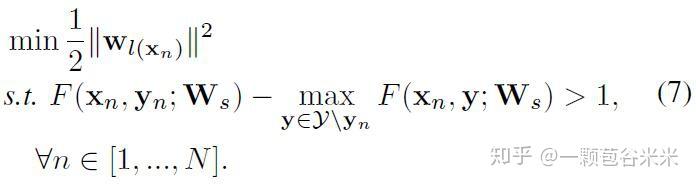

为了允许所见数据中的误差,作者在目标函数添加惩罚项并放松约束:
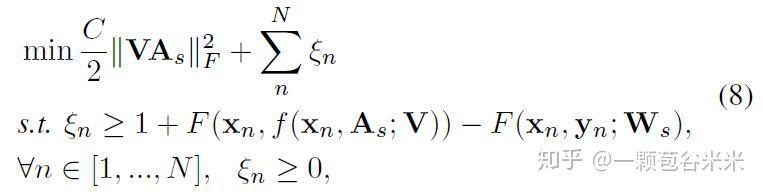

其中, C > 0 是一个控制训练误差最小化(training error minimization)和边际最大化项(margin maximization term)之间的折衷的常数, \xi_n 是当实例 x_n 违反公式(5)的约束时的松弛变量。当 x_n 预测对的时候,则误差为常熟1,反之,则为


我们可以观察到,两个不同的正确预测的实例将受到同样的惩罚。同时,如果 F(x_n, f(x_n, A_s;V))-F(x_n, y_n;W_s) 的值较小,则错误预测实例与正确预测实例处于相同的惩罚级别。显然,这是不公平的,不能反映实例的差异。直觉上,正确预测的具有较高兼容性分数的实例应该受到比具有较小兼容性分数的实例更小的惩罚。同样,对于预测不正确的情况,应该比预测正确的情况受到更严厉的惩罚。因此,基于这个假设,作者提出了一个自适应函数 \Delta: Y \times Y \rightarrow R 来区分不同可靠性的预测。而该自适应的函数由该实例预测的结果向量与对应的ground truth的标签向量之间的欧式距离求得:
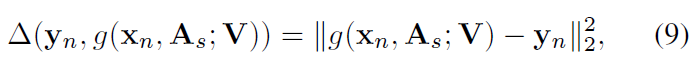

即,预测的越正确,与 y_n 的距离越小,受到的惩罚就越小,下图就给出了一个例子,更好的理解:
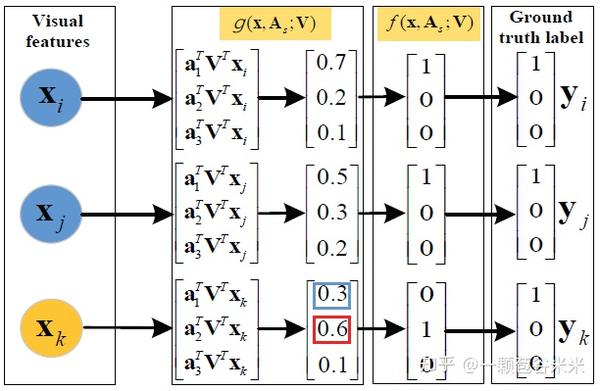

假设三个属于同一类的实例 X_i, X_j, X_k ,对应的语义向量分别是 a_i,a_j,a_k ,在这个例子中,X_i, X_j 预测对了,且X_i 的可信度高于X_j ,按照前面的公式,X_i 对应的惩罚是0.14,是小于同样预测对但是可行度不高的X_j的惩罚0.38的。而 X_k 则预测错了,他的误差则来源于两部分,一部分是 F(x_n,f(x_n,A_s;V))-F(x_n,y_n;W_s)=x_n^TVA_sf-x_n^TVA_sg=0.6-0.3=0.3 ,另一个则是他们之间的欧式距离即 \Delta = 0.86 ,加起来则为1.16.是三个惩罚项中最大的值了。通过这样的方法,就能让预测正确的和预测错误的惩罚不在一个等级上,而预测正确之间,置信度高的受的惩罚更小一点。因此上面的公式(8)可以写成下面的最终的ASTE的目标函数的格式了:
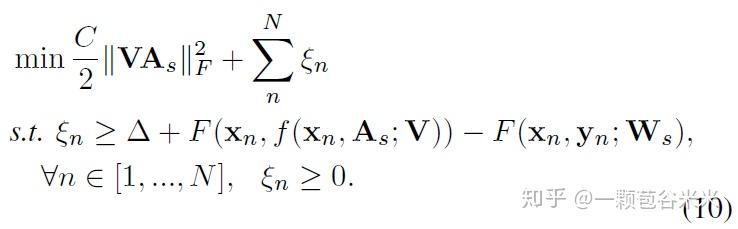

这个问题可以等效的用一个标准的凹凸(concave-convex)函数表示:


这就又和latent structural SVM很类似,即最小化一个凸函数和凹函数的和。其已被证明可以收敛到局部最优或鞍点解。通过凹凸过程(concave-convex procedure, CCCP),可获得最佳兼容性矩阵 compatibility matrix V^* 。CCCP是一个迭代的过程,每一步迭代过程,对于每一对(x_n,y_n) ,找到得分最高的(即the highest compatibility score)的预测结果 f(x_n,A_s;V) ,如果预测结果与标签一致,即 f(x_n,A_s;V) = y_n ,说明预测正确,则误差为,其中 ||VA_s||_F^2 是正则项:
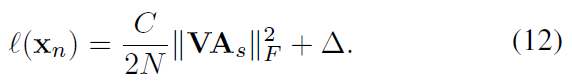

反之,如果,得分最高的预测都不正确,则误差为:
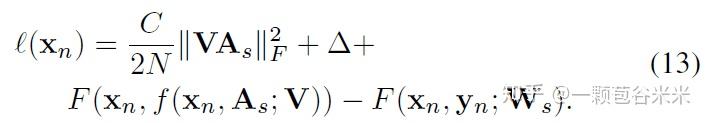

兼容性矩阵 V 的优化通过SGD方法,如下所示:
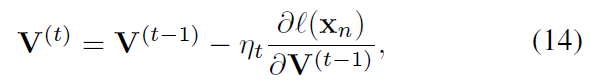

讲了这么多,下面就看看他的算法,可以更清晰的看到计算的思路:


一旦最优兼容性函数 V^* 找到了,代码里的判断条件是当公式(11)的值小于一个容忍值 \epsilon 时,即停止训练,则unseen类的预测结果则可以通过找最大兼容性函数对应的标签获得了:
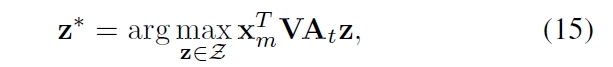

通过下面的流程图,我们再来回顾一下ASTE。然后开始本文提到的第二个贡献点SPASS。
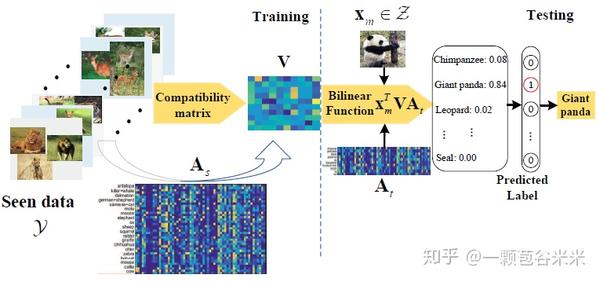

B、The Self-PAced Selective Strategy(SPASS)
大多数归纳式(inductive ZSL)的方法就是直接把从seen data中学到的模型应用于unseen data。但是seen data和unseen data之间分布的不同,会导致学到的嵌入模型在unseen data上出现偏置。为了解决这种领域漂移(domain shift)的问题,我们把ZSL看作transductive learning的一种特例。考虑到ZSL中域移位问题的主要原因在于unseen data的标签缺失,自然的想法是从未知数据中选择一些伪标签实例,并以一种transductive learning的方式来解决这个问题。因此,现在的挑战就是如何选择那些可靠的伪标签数据。作者提出了一种选择策略,从简单到苦难的方式(an easy to hard fashion)逐步选择。这种逐渐增加训练实例的过程被称为curriculum。设计curriculum的一个简单方法是根据确定的、带有启发性的、“简单的”度量方式来选择实例。在curriculum中,选择简单的实例进行培训。基于这一思想,根据兼容性得分对先前预测的未知数据进行排序。兼容性得分越高,正确预测实例的可靠性就越高。文章将一个实例的易用性定义为:如果一个实例的预测是可靠的,那么它是容易预测的。
为此,作者提出了一种自步调选择策略(SPAS),用于迭代地选择可靠的伪标记的unseen实例。在自学习的启发下,引入了一个二元变量 u_m 来指示 第m个实例是否简单。然后定义选择过程为:
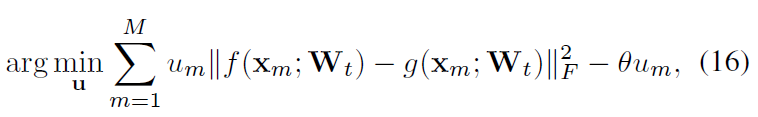

其中, M 是unseen data里的实例个数, f 是预测预测结果(可以看成是one-hot形式的), g 则是embedding结果, u=[u_1,u_2,...,u_M]\in[0,1]^M是指式向量,其值是 [0,1,1,0,...,1] 这个样子的。 \theta 则是一个阈值,用于限制每次选择的实例个数。 p = ||f(x_m;W_t)-g(x_m;W_t)||_F^2 的值越小,说明该实例的置信度越高。具个例子 g_1 = [0.5, 0.3, 0.2] , g_2 = [0.7, 0.2, 0.1] , f=[1,0,0] ,g1和g2的预测结果都为f,但是g1和f之间的p值是大于g2和f之间的p值的,说明他的置信度是较低的。从他们各自的结果很明显就能看出g2认为该类被分为第一类的概率为0.7,远大于0.5的。而 \theta 的值越小,该实例要被选择,即其 u_m=1 ,则其p值要小于\theta,才能被留下,因此只有真的“easy”实例会被选择,而随着\theta的值增大,约束减小,会有更多的不那么easy的实例也会被选择。该选择过程会一直持续到所有的实例都被选择为止。
下面再讲讲选择的unseen数据的实例怎么进行训练。
C. Transductive ASTE (TESTE)
现在,有label的seen 数据和没label的unseen数据都是现成的了,一个transductive ZSL就可以将SPASS和ASTE结合起来。我们称为TASTE。其结构为: