知识图谱相关实体搜索

相关搜索(Relevance Search)是信息检索中的一个经典问题,相关搜索是指给定一个查询实体,返回与其相关度最高的实体(一个类似的问题Similarity Search,一般来说指相关搜索的一个特例,即只返回与查询实体同类型的相关实体)。相关搜索面临的一个主要问题是搜索中的歧义性,即不同的用户对于“相关性”有着不同的理解和偏好。当前的一些方法已经能够通过要求用户提供例子的方式在一些schema较为简单的图谱(如DBLP, linkedMDB等)上完成对相关搜索的消歧,然而当处理一些更复杂的图谱时(如DBpedia, YAGO等),因为效率问题,这些方法很难被直接应用。本文提出了一种基于启发式搜索的算法RelSUE,能够有效地在schema-rich的知识图谱上进行搜索,实验表明RelSUE在我们构建的benchmark数据集上能够比其他state-of-art的方法取得更好的效果。
Background
知识图谱是由实体和边(实体间的二元关系)构成的高度结构化的数据,这样的数据中蕴含了大量可以被机器所“理解”的语义信息。两个实体间相关性的语义信息通常可以通过不同元路径(meta path,即顶点均为type,边为property的路径)的加权组合来刻画,不同的组合即体现了不同的语义。例如下图中,
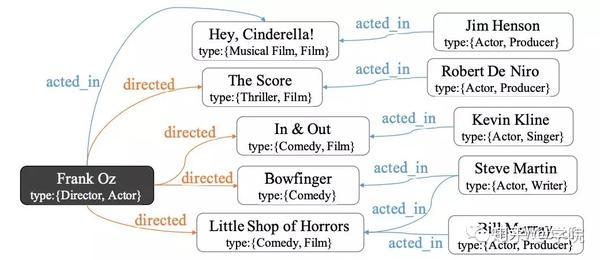

连接实体Frank Oz以及Kevin Kline的元路径包括
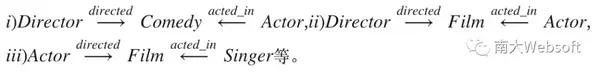

不同的元路径组合可以体现不同的偏好,例如如果我们只以一条元路径iii)作为相关性的语义,那么上图中以Frank Oz作为查询实体,符合这种相关性的目标实体只有Kevin Kline一个。可以预见,不同的用户对于相关性都会有一定不同的理解(或者某一特定场景下的偏好),所以我们需要一种有效的方式来捕捉到不同用户(或搜索用例)的主观偏好,目前一种主流的框架是要求用户除了输入查询实体以外再提供几个预期结果的例子,然后系统根据这些例子自动地生成一种能够准确刻画例子与查询实体间相关性的加权的元路径组合。加权元路径组合通常有两步组成,第一步首先定位出一些promising的元路径,第二步基于某些统计或学习的方法自动地为这些路径赋予权重。RelSUE同样沿用了这一技术路线。
Approach
在过去的方法中,第一步元路径的定位可以简单地通过穷举或者用户指定等方式完成,然而,这些方法往往只能应用于一些仅包含几种不同type以及几种不同property的schema-simple图谱中,对于DBpedia(645 property,453 type)或者YAGO(37 property, 536,648 type)这种包含大量type即property的图谱则不再适用——人工挑选元路径或者穷举连接实体间的所有元路径都是不现实的(一方面本身元路径的数量是个问题,另一方面进一步对所有选出来的元路径分配权重也是一个问题)。所以我们需要一种更有效地方式来对元路径进行选择,RelSUE正是为了解决如何在schema-rich的图谱中准确并快速地识别出能够刻画查询实体与例子实体间相关性的元路径。
本文共提出了两种不同的算法,RelSUE及RelSUE-e。
RelSUE-e首先基于双向BFS穷举所有的连接查询实体与例子的元路径(给定直径内),然后根据我们设计的significance函数为每一个元路径进行打分排序,选出打分最高的K条元路径作为目标元路径集合。可以发现RelSUE-e仍然需要先穷举所有元路径再进行选择,虽然选择最优的K条元路径可以保证后续的权重分配能够有效进行,但是穷举所有路径的代价仍然非常巨大,且设定最大路径长度的方式也十分不灵活具有很大的局限性(例如对于YAGO,只能够做到穷举所有两步的元路径,3步的速度就已经无法接受,意味着所有3步即以上的相关性语义都会被忽视)。
为了应对以上这些缺陷,本文进一步提出了基于启发式搜索的方法RelSUE。在RelSUE的启发式搜索框架中,搜索从查询实体展开,一步步扩展至所有例子实体都被某K条元路径连接。搜索空间树结构扩展的优先级基于两点考虑:
1)当前结点所处的潜在的元路径的长度(可以通过当前结点与查询实体的距离,以及当前结点与例子实体间的距离来估算,因为搜索是从查询实体出发,所以当前结点与查询实体的距离是已知的,而与例子实体的距离,我们通过distance oracle来计算)
2)当前结点的度数(度数越大的点往往意味着包含的信息较少,通过度数来作为衡量信息量的指标也是一种常见的做法);此外,为了避免启发式搜索找到一些过长的路径,我们再对1)中估计的路径长度加上一个衰减因子β∈[0,1],即在原有打分的基础上再乘上β^L,其中L为估计的元路径长度。βL,其中L为估计的元路径长度此外,对于RelSUE即RelSUE-e,本文的搜索都做了一些针对避免选出冗余元路径的优化(如果两条元路径对应的具体路径相同,则视为冗余)
有了这些路径以后,那么就可以进行到background中所介绍的算法的第二步了。两种不同版本的RelSUE都通过线性SVM学习各个元路径的权重(每个元路径都对应一个特征),至于为什么用SVM,没什么特别的理由,也不是本文的贡献所在。
Benchmark
为了进行对比实验,本文在两个数据集上(DBpedia, YAGO)分别人工标注了4组查询(基于对应语义的元路径数量、长度等纬度区分)。
Evaluation
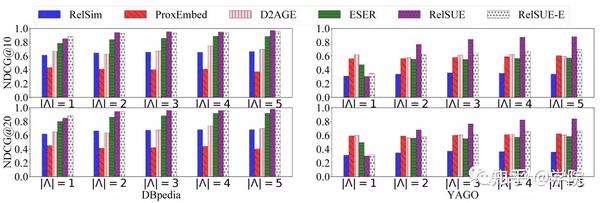
实验结果表明RelSUE在两个不同数据集上都显著好于现有的方法。

RelSUE的源码及用到的查询可以访问