有哪些「神奇」的数据获取方式?

Chrome扩展web scraper ,不用写代码抓取数据,这里以抓取豆瓣电影排行榜为例。
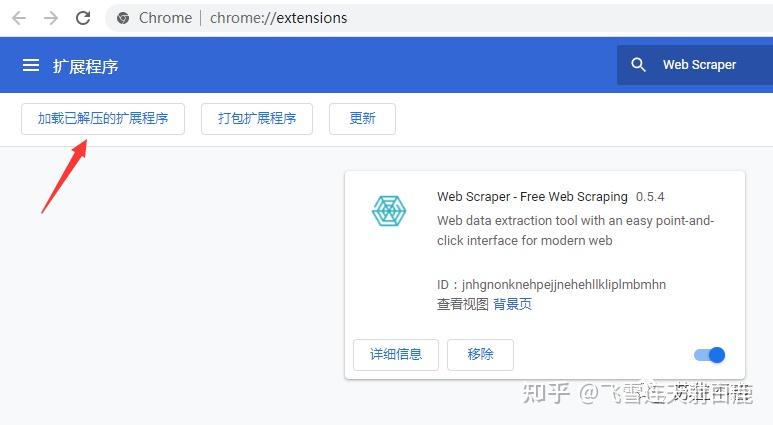
只要建立sitemap即可抓取相应的数据,无需写代码即可抓取95%以上的网站数据(比如博客列表,知乎回答,微博评论等), Chrome扩展地址 https://chrome.google.com/webstore/detail/web-scraper-free-web-scra/jnhgnonknehpejjnehehllkliplmbmhn ,先安装好扩展。

使用web scraper抓取数据步骤为: 创建 sitemap,新建 selector (抓取规则),启动抓取程序,导出为 csv文件 。
下面开始,先打开谷歌浏览器控制台,可以看到个web scraper 标签,下面有sitemaps,sitemap,create new sitemap ,点击create新建一个爬虫抓取任务。
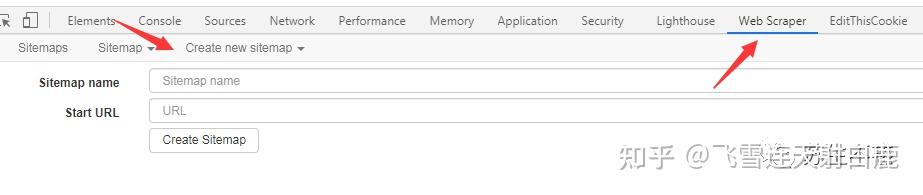

豆瓣电影的分页链接为 https://movie.douban.com/top250?start=0&filter=,共10页,所以URL填入 https://movie.douban.com/top250?start=[0-250:25]&filter= ,name随意填一个。


然后点击add new selector 添加新的选择器。
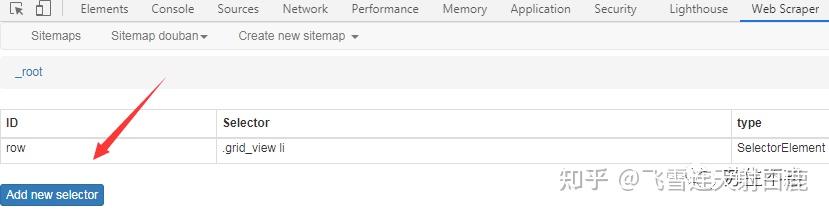

给id起个名,type为 element ,点击 select 选中第一部电影《肖申克的救赎》,可以看到网页标红了。
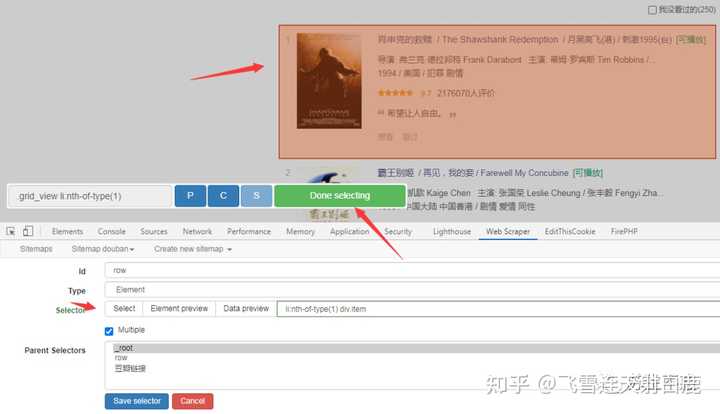

然后再选择第二条,可以看到下面的电影都选中了,点击 done selecting 就好了。
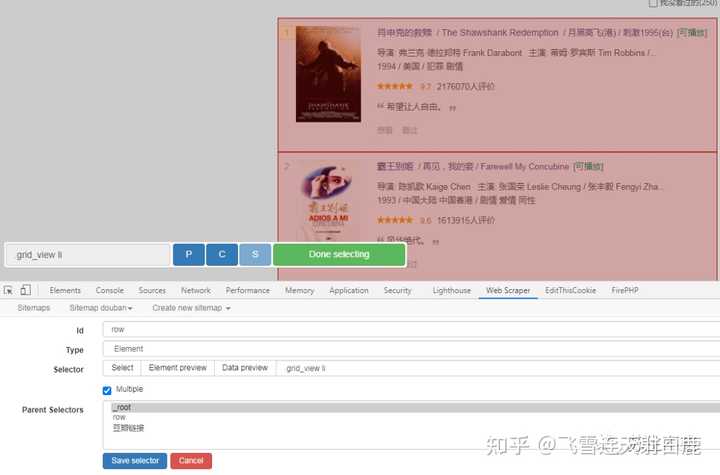

接着点击 element preview 预览下可以看到电影元素都抓取到了,因为一页有多部电影还要选中 Multiple 。
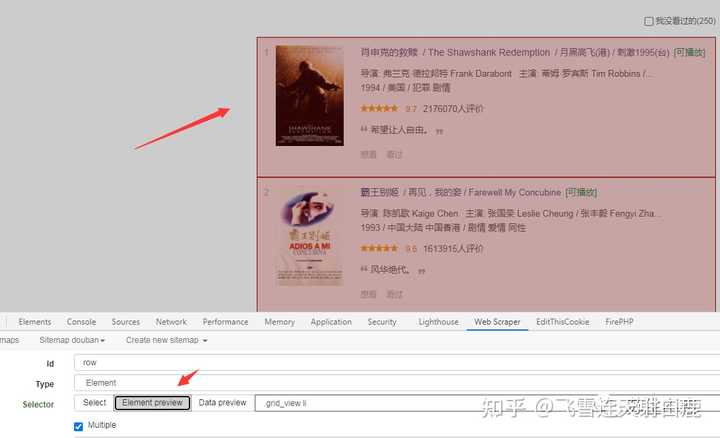

然后进入刚才建的 element 里新加选择器。


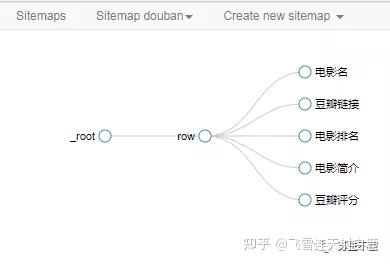
共有5个选择器,分别为电影名,豆瓣链接,电影排名,电影简介,豆瓣评分。


可以预览下新建的电影名选择器看看效果。


点击selector graph 可以看到抓取的选择器关系图。

选择器都建好后点击 scrape 开始抓取数据了。
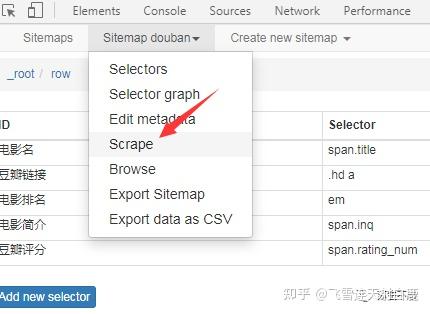

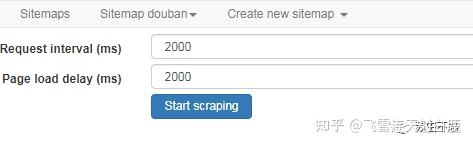

这时候浏览器会自动弹出窗口抓取数据,不用管它,抓取完后它会自动关闭。

很快抓取完了。

再预览下抓取的数据是否正常。
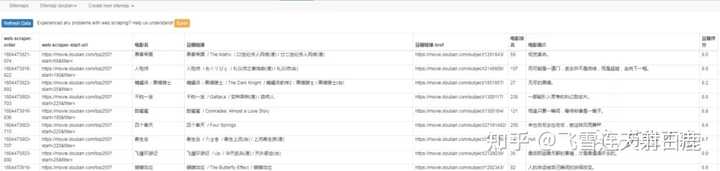

确认没问题后点击 export data as CSV 导出为CSV文件。
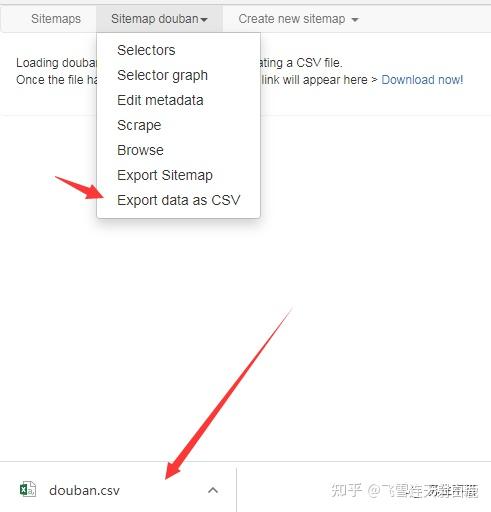

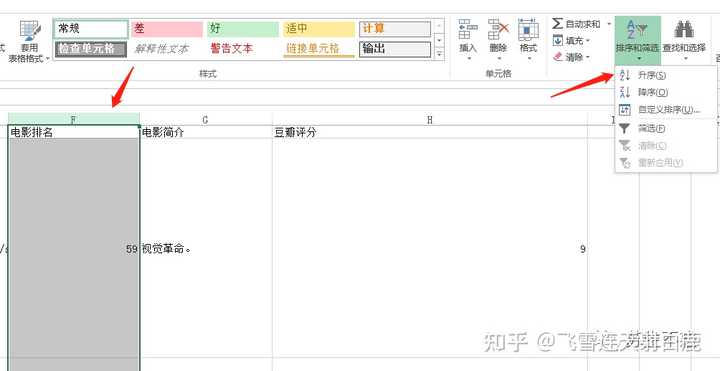
用Excel打开CSV文件,看到抓取的电影排序乱了。


没关系,选中电影排名这列,选择升序排列。

最后抓取的250条豆瓣电影数据结果就是这样了,搞定。


更多详情见文章: