译文(IRCNN) Learning Deep CNN Denoiser Prior for Image Restoration


学习深度CNN降噪先验用于图像重建(IRCNN)
Kai Zhang, Wangmeng Zuo, Shuhang Gu, Lei Zhang
School of Computer Science and Technology, Harbin Institute of Technology, Harbin, China
Dept. of Computing, The Hong Kong Polytechnic University, Hong Kong, China
cskaizhang@gmail.com, wmzuo@hit.edu.cn, shuhanggu@gmail.com, cslzhang@comp.polyu.edu.hk
摘要
基于模型的优化方法和判别式学习方法一直是解决低级视觉中各种反问题的两种主要策略。典型地,这两种方法各有其优缺点,例如,基于模型的优化方法对于处理不同的逆问题是灵活的,但为了良好性能的目的,对于复杂的先验通常是耗时的;同时,判别式学习方法的检测速度较快,但其应用范围受到专门任务的极大限制。最近的研究表明,借助可变分裂技术,可以将降噪器优先插入作为基于模型的优化方法的模块化部分以解决其他反问题(例如,去模糊)。当通过判别式学习获得降噪器时,这种整合引起相当大的优势。然而,与快速鉴别降噪器之前的整合研究仍然缺乏。为此,本文旨在训练一组快速有效的CNN(卷积神经网络)降噪,并将其集成到基于模型的优化方法中以解决其他反问题。实验结果表明,所学习的一套降噪器不仅可以实现有希望的高斯降噪结果,而且可以用作为各种低级视觉应用提供良好性能的先验信息。
1 引言
图像重建(IR)在各种low-level视觉应用中具有高度实用价值一直是一个长期存在的问题[1,9,47]。一般而言,图像重建的目的是从其退化的观察值y = Hx + v中恢复潜在的干净图像x,其中H是退化矩阵,v是标准偏差σ的加性高斯白噪声。通过指定不同的降级矩阵,可以相应地获得不同的IR任务。当H是单位矩阵时,三个经典的IR任务是图像降噪,H是模糊算子时的图像去模糊,H是模糊和降采样的合成算子时的图像超分辨率。
由于IR是一个不适定的逆问题,因此需要采用也称为正则化的先验来约束解空间[50,66]。从贝叶斯的角度来看,可以通过求解最大后验概率(MAP)问题来获得解x,
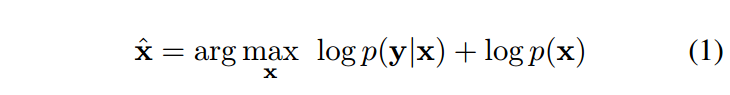

其中log p(y|x)表示观测值y的对数似然性,log p(x)表示x的先验概率,独立于y。更正式地说,公式1可以被重新表述为
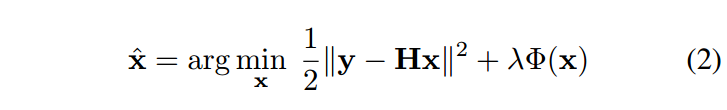

解最小化由保真项 \(\frac{1}{2}||y-Hx||^2\) ,正则项Φ(x)和折衷参数λ组成的能量函数。保真项保证解决方案符合退化过程,而正则化强制输出的期望性能。
一般来说,解决方程2的方法可以分为两大类,即基于模型的优化方法和判别式学习方法。基于模型的优化方法旨在直接求解公式2,一些优化算法通常涉及耗时的迭代推理。相反,判别式学习方法试图通过优化包含退化干净图像对[2,13,51,55,57]的训练集上的损失函数来学习先验参数Θ和紧凑推理。目标由下面给出:
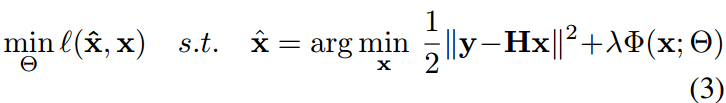

因为推理是由MAP估计指导的,所以我们将这种方法称为MAP推理引导的判别式学习方法。通过用预定义的非线性函数x = f(y,H;Θ)替换MAP推理,人们可以将普通的判别式学习方法看作是公式3的一般情况。可以看出,基于模型的优化方法和判别式学习方法之间的一个明显区别是,前者通过指定退化矩阵H来处理各种IR任务是灵活的,而后者需要使用具有某些退化矩阵的训练数据来学习模型。因此,与可以灵活地处理不同的IR任务的基于模型的优化方法不同,判别式学习方法通常受专门任务的限制。例如,NCSR [22]等基于模型的优化方法可灵活处理降噪,超分辨率和去模糊,而判别式学习方法MLP [8],SRCNN [21],DCNN [62]分别针对这三项任务。即使对于诸如降噪的特定任务,基于模型的优化方法(例如,BM3D [17]和WNNM [29])可以处理不同的噪声级别,而[34]的判别式学习方法分别训练每个级别的不同模型。
然而,牺牲灵活性,判别式学习方法不仅可以享受快速的测试速度,而且由于联合优化和端到端训练而倾向于提供有前途的性能。相反,基于模型的优化方法通常需要耗费时间以及性能良好的复杂先验[27]。因此,这两种方法各有优缺点,因此研究它们的综合利用各自的优点是有吸引力的。幸运的是,借助变量切分技术,如交替方向乘法器(ADMM)方法[5]和半二次切分方法[28]),可以分别处理保真度项和正则项[44] ,特别是正则化项只对应一个降噪问题[18,31,61]。因此,这可以将任何判别式降噪集成到基于模型的优化方法中。然而,据我们所知,与判别式降噪整合的研究仍然缺乏。
本文旨在训练一组快速有效的判别式降噪,并将其集成到基于模型的优化方法中,以解决其他逆问题。我们不是学习MAP推理引导的判别模型,而是采用纯卷积神经网络(CNN)来学习降噪,以便利用CNN的最新进展以及GPU计算的优点。特别是在网络设计或训练中采用了几种CNN技术,包括整流器线性单元(ReLU)[37],批量归一化[32],Adam [36],扩张卷积[63]。除了为图像降噪提供良好性能之外,学习过的一套降噪器被插入基于模型的优化方法中以解决各种逆问题。
这项工作的贡献总结如下:
•我们训练了一套快速有效的CNN降噪器。利用变量切分技术,强大的降噪器可以将很强的图像先验带入基于模型的优化方法。
•将已学习的一套CNN降噪器作为基于模型的优化方法的模块化部分进行插入,以处理其他逆问题。对经典IR问题(包括去模糊和超分辨率)进行的大量实验证明了集成灵活的基于模型的优化方法和基于CNN的快速识别学习方法的优点。
2 背景
2.1 使用降噪先验进行图像重建
已经有几次尝试将降噪声器先验纳入基于模型的优化方法来解决其他反问题。在文献[19]中,作者使用纳什均衡法推导了一种迭代去耦BM3D(IDDBM3D)方法用于图像去模糊。在[24]中,提出了一种配备CBM3D降噪先验的类似方法用于单图像超分辨率(SISR)。通过迭代更新反向投影步骤和CBM3D降噪步骤,该方法大大提高了SRCNN的PSNR[21]。在[18]中,增强拉格朗日方法被用来将BM3D降噪器融合进图像去模糊方案。采用与[19]类似的迭代方案,[61]中提出了一种基于ADMM方法的即插即用先验式框架。在这里我们注意到,在[61]之前,在[66]中也提到了类似的即插即用思想,其中提出了用于图像降噪,去模糊和修补的半二次切分(HQS)方法。在文献[31]中,作者使用ADMM和HQS的替代方案,即primaldual算法[11]来解耦保真项和正则项。其他一些相关工作可以在[6,12,48,49,54,58]中找到。上述所有方法都表明,保真项和正则化项的解耦可以使各种现有的去噪模型解决不同的图像恢复任务。
我们可以看到,先前的降噪器可以通过各种方式插入迭代方案中。这些方法背后的共同想法是将保真项和正则化项分开。出于这个原因,他们的迭代方案通常涉及与保真项相关的子问题和去噪子问题。在下一小节中,我们将使用HQS方法作为例子,因为它很简单。应该指出的是,尽管HQS可以被看作是处理不同图像恢复任务的一般方法,但也可以将去噪先验纳入其他适用于特定应用的方便适用的优化方法中。
2.2 半二次切分(HQS)方法
基本上,要将降噪器事先插入公式2的优化过程中,通常采用变量切分技术来解耦保真项和正则项。在半二次切分方法中,通过引入一个辅助变量z,方程2可以重新表述为一个约束优化问题,由下式给出:
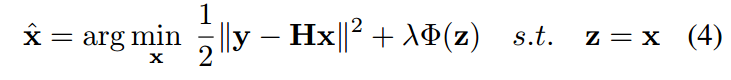

然后,HQS方法试图解决以下问题


其中μ是一个以非递减顺序迭代变化的惩罚参数。公式5可以通过下面的迭代方案解决
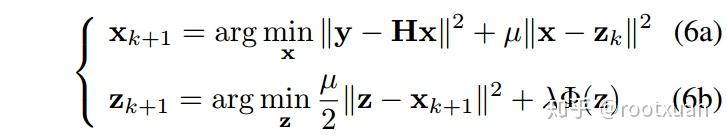

正如人们所看到的,保真项和正则项被分解成两个单独的子问题。具体而言,保真项与二次正则化最小二乘问题(即公式(6a))相关,该问题对于不同的退化矩阵具有各种快速解决方案。一个直接的解决方案是
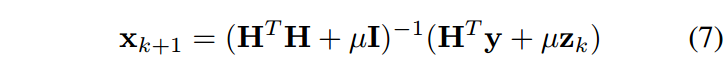

由正则项与公式6相关,可以改写为:
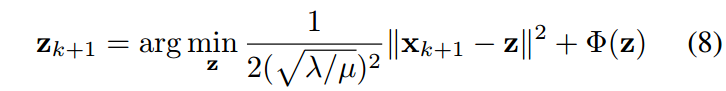

根据贝叶斯概率,公式(8)对应于噪声水平为 \(\sqrt{λ/μ}\) 的高斯降噪器对图像 \(x_{k+1}\) 进行降噪。因此,任何高斯降噪器都可以作为解决方程式2的一个模块化部分。为了解决这个问题,我们重写公式8为:
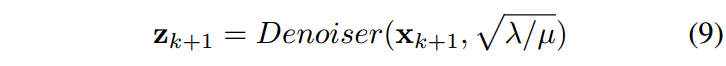

值得注意的是,根据公式8和9,图像先验Φ(·)可以隐式地被降噪先验替代。这种有希望的性质实际上有几个优点。首先,它可以使用任何灰色或彩色降噪器来解决各种逆问题。其次,显式图像先验Φ(·)在求解方程2时可能是未知的。第三,可以利用不同图像先验的若干互补降噪器来解决一个具体问题。请注意,只要涉及去噪问题,这个性质也可用于其他优化方法(例如,迭代收缩/阈值算法ISTA [4,14]和FISTA [3])。
3 学习CNN降噪先验
3.1 为什么选择CNN降噪?
由于公式2中的正则化项在重建性能中起着至关重要的作用,因此在公式9中选择降噪的前提将是非常重要的。现有的用于解决其他逆问题的基于模型的优化方法的降噪先验包括总变差(TV)[10,43],高斯混合模型(GMM)[66],K-SVD [25],非局部均值[7]和BM3D [17]。这种降噪先验有它们各自的缺点。例如,总变差(TV)会导致水彩效应;K-SVD降噪先验承受高计算负担;如果图像没有表现出自相似性,则非局部均值和BM3D降噪先验可能会使不规则结构过度平滑。因此,可以有效实现的强降噪先验是非常需要的。
无论速度和性能如何,彩色图像先验或降噪也是需要考虑的关键因素。这是因为现代相机采集的或在互联网上传输的大多数图像都是RGB格式。由于不同颜色通道之间的相关性,已经认识到联合处理颜色通道往往比独立处理每个颜色通道产生更好的性能[26]。然而,现有的方法主要集中在对灰度图像先验进行建模,并且只有少数工作集中在对彩色图像先验进行建模(参见 [16,41,46])。也许最成功的彩色图像先验建模方法是CBM3D [16]。它首先通过手工设计的线性变换将图像解相关为亮度色差色彩空间,然后在每个变换的色彩通道中应用灰色BM3D方法。CBM3D有望用于彩色图像去噪,该方法已经指出,由此产生的变换后的亮度-色度彩色通道仍然保持一定的相关性[42],最好共同处理RGB通道。因此,不使用手动设计,而是使用判别式学习方法自动学习底层彩色图像先验,将是一个不错的选择。
考虑速度,性能和有差别的彩色图像先验的建模,我们选择深度CNN来学习判别式降噪。使用CNN的原因有四个。首先,由于GPU的并行计算能力,CNN的推理非常有效。其次,CNN通过很深的结构展现出强大的先验建模能力。第三,CNN可以利用外部先验,这是许多现有的诸如BM3D之类的降噪方法的内部先验的补充。换句话说,与BM3D的组合有望改善性能。第四,过去几年在CNN的训练和设计方面取得了很大的进展,我们可以利用这些进展来促进判别式学习。
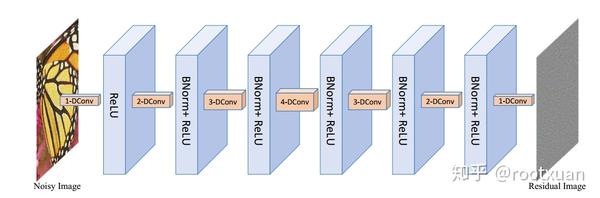

3.2 提出CNN降噪器
CNN降噪器的架构如图1所示。它由七层组成,包含三个不同的模块,即第一层中的"扩张卷积+ ReLU"模块,五个"扩张卷积+BN+ ReLU"中间层的块,以及最后一层中的"扩张卷积"块。从第一层到最后一层的(3×3)扩张卷积的扩张因子分别被设置为1,2,3,4,3,2和1。每个中间层的特征映射数量设置为64.下面我们将在网络设计和训练中给出一些重要细节。
使用扩张过滤器放大接收区域 已经广泛认识到,上下文信息促进了图像去噪中损坏的像素的重构。在CNN中,为了捕获上下文信息,它通过前向卷积操作逐步扩大感受野。一般来说,有两种基本的方法来扩大CNN的感受野,即增加过滤器尺寸和增加深度。但是,增加滤波器的大小不仅会引入更多的参数,还会增加计算负担[53]。因此,在现有的CNN网络设计中流行使用深度较深的3×3滤波器[30,35,56]。在本文中,我们改为使用最近提出的扩张卷积来在感受野大小和网络深度之间进行权衡。扩张卷积以其扩大感受野的能力而闻名,同时保持传统3×3卷积的优点。具有膨胀因子s的扩张滤波器可简单地解释为大小为(2s + 1)×(2s + 1)的稀疏滤波器,其中只有9个固定位置可以是非零。因此,每层的等效感受野是3,5,7,9,7,5和3。因此,可以容易地获得所提出的网络的感受野是33×33。如果使用传统的3×3卷积滤波器,网络将具有相同网络深度(如7)的大小为15×15的感受野或者具有相同感受野但深度为16(如 33× 33)。为了展示我们的设计在上述两种情况下的优点,我们已经在相同的训练设置下训练了噪声水平为25的三种不同模型。事实证明,我们设计的模型在BSD68数据集上的平均PSNR可以达到29.15dB [50],比传统的3×3卷积滤波器的7层网络的28.94dB好得多,并且非常接近16层网络的29.20dB 。
使用批量归一化和残差学习来加速训练 虽然先进的梯度优化算法可以加速训练并提高性能,但架构设计也是一个重要因素。在最近的CNN架构设计中,批量规一化和残留学习是最具影响力的两种架构设计技术。特别指出,批量归一化和残差学习相结合对高斯去噪特别有用,因为它们相互有利。具体而言,它不仅可以实现快速稳定的训练,而且还可以带来更好的去噪效果[65]。在本文中,采用这种策略,我们凭经验发现它也可以使不同噪声级别的模型快速转换到另一模型。
使用小尺寸的训练样本来帮助避免边界效应 由于卷积的特点,CNN的去噪图像可能会导致令人讨厌的边界效应而没有适当的处理。有两种常见的解决方法,即对称填充和零填充。我们采用零填充策略,希望设计的CNN具有模拟图像边界的能力。请注意,第四层扩张因子4的膨胀卷积在每个特征图的边界填充4个零。我们凭经验发现,使用小尺寸的训练样本可以帮助避免边界效应。主要原因在于,不使用大尺寸的训练块,将它们裁剪成小块可以使CNN看到更多的边界信息。例如,通过将尺寸为70×70的图像块裁剪成尺寸为35×35的四个小的非重叠块,边界信息将大大增加。我们还使用大尺寸的图像块测试了性能,我们凭经验发现这并不能改善性能。但是,如果训练图像块的大小小于接受场,则性能会下降。
学习具有小间隔噪声水平的特定降噪模型 由于迭代优化框架需要具有不同噪声级别的各种降噪器模型,因此应该考虑如何训练辨别模型的实际问题。各种研究表明,如果子问题(即公式(6a)和公式(6b))的确切解决方案对于优化是困难或耗时的,那么使用不精确但快速的子问题解决方案可能会加速收敛[39, 66], 在这方面,他们不需要为每个噪声水平学习许多有区别的降噪模型。另一方面,虽然公式9是一个降噪器,它与传统的高斯去噪具有不同的目标。传统的高斯去噪的目标是恢复潜在的干净的图像,然而,这里的去噪器只是起到自己的作用,而不管要去噪的图像的噪声类型和噪声水平如何。因此,公式(9)中的理想判别式降噪器应按当前的噪声水平进行训练。结果是,设定去噪的数量是有折衷的。在本文中,我们的噪声水平范围为[0,50],以步幅2训练了一组降噪器,从而为每个灰色和彩色图像先验模型产生25个降噪器。由于迭代方案,[0,50]的噪声水平范围足以处理各种图像重建问题。尤其值得注意的是,降噪器的数量要远远少于那种为不同退化学习不同模型的方法。
4 实验
4.1 图像去噪
众所周知,卷积神经网络通常受益于大量训练数据。因此,我们收集包含400个BSD图像,400个从ImageNet验证集[20]中选择的图像和4744幅Waterloo Exploration数据库[40]的大型数据集,而不是在由400个大小为180×180的Berkeley分割数据集(BSD)[13]图像组成的小数据集上进行训练。我们凭经验发现使用大数据集并不能改善BSD68数据集的PSNR结果[50],但可以稍微改善其他测试图像的性能。我们将图像裁剪成大小为35×35的小块,并选择N = 256×4000块进行训练。至于相应噪声patchs的生成,我们通过在训练期间向干净patchs添加加性高斯噪声来实现这一点。由于采用了残差学习策略,我们使用下面的损失函数
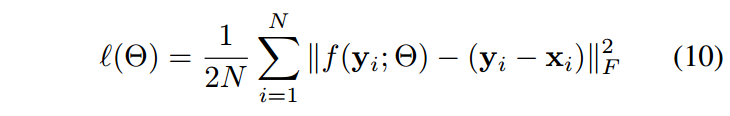

其中 \({\{(y_i,x_i)\}}\ ^{N}_{i=1}\) 表示N个noisy-clean小块对。为了优化网络参数Θ,采用了Adam优化[36]。,学习率一开始为1e-3,当训练损失停止下降时固定为1e-4。如果训练损失五个连续的epoch不变时,则训练终止。对于Adam的其他超参数,我们使用它们的默认设置。mini-batch大小设置为256.在mini-batch学习期间使用基于旋转或/和翻转的数据增强。去噪模型在Matlab(R2015b)环境中使用MatConvNet软件包[60]和Nvidia Titan X GPU进行训练。为了减少整个训练时间,一旦获得模型,我们用这个模型初始化相邻的降噪器。培训一套降噪模型需要大约三天的时间。




我们将提出的denioser与几种最先进的去噪方法进行了比较,其中包括两种基于模型的优化方法(即BM3D [17]和WNNM [29]),两种判别式的学习方法(MLP [8]和TNRD [ 13])。表1显示了不同方法对BSD68数据集的灰度图像去噪结果。可以看出,WNNM,MLP和TNRD的PSNR比BM3D高出0.3dB。然而,所提出的CNN降噪器在这三种方法中可以具有约0.2dB的PSNR增益。表2显示了基准CBM3D和我们提出的CNN降噪器的彩色图像去噪结果,可以看出,提出的降噪器一直大大优于CBM3D。这样一个有前途的结果可以归因于CNN对彩色图像先验的强大建模能力。
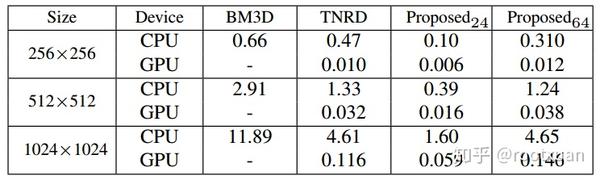
对于运行时间,我们将其与BM3D和TNRD进行了比较,因为它们在实际应用中具有潜在价值。由于提议的降噪器和TNRD支持GPU上的并行计算,因此我们也提供GPU运行时间。为了与类似的PSNR性能下的TNRD做进一步的比较,我们另外提供了提议的降噪器的运行时间,其中每个中间层具有24个特征图。我们使用Nvidia cuDNN-v5深度学习库来加速GPU计算,并且不考虑CPU和GPU之间的内存传输时间。表3给出了噪声水平为25的256×256,512×512和1024×1024图像去噪的不同方法的运行时间。我们可以看到,提出的去噪器在CPU和GPU实现上都具有很强的竞争力。值得强调的是,所提出的每层具有24个特征图的去噪器具有与TNRD相当的28.94dB的PSNR,但提供了更快的速度。 TNRD的速度和性能之间的这种良好折中恰当地归因于以下三个原因。首先,采用的3×3卷积和ReLU非线性简单而有效。其次,与TNRD的阶段式架构相比,这种架构本质上在每个直接输出层都有瓶颈,我们鼓励不同层次之间流畅的信息流动,因此具有更大的模型容量。第三,采用有利于高斯去噪的分批归一化。根据上述讨论,我们可以得出结论,提议的降噪器是对BM3D和TNRD的强有力竞争者。

4.2 图像去模糊
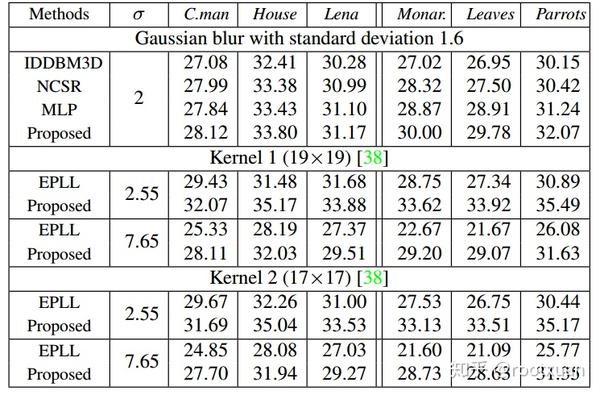
作为一种常见设置,首先应用模糊核,然后添加噪声级别为σ的加性高斯噪声,合成模糊图像。另外,我们假设卷积是在圆形边界条件下进行的。因此,公式(7)的一个有效实现是通过使用快速傅立叶变换(FFT)。为了做一个彻底的评估,我们考虑三个模糊核,包括标准偏差为1.6的常用高斯核和来自[38]的八个真实模糊核中的前两个。如表4所示,我们还考虑了具有不同噪声水平的高斯噪声。作为对比,我们选择一种名为MLP [52]的判别方法和三种基于模型的优化方法,包括IDDBM3D [19],NCSR [22]和EPLL。在测试图像中,除了如图2所示的三个经典灰度图像之外,还包括三个彩色图像,以便我们可以先测试学习颜色降噪器的性能。同时,我们注意到上述方法是针对灰度图像去模糊而设计的。特别地,NCSR首先将颜色输入转换为YCbCr空间,然后在亮度分量中执行主算法。在下面的实验中,我们简单地将颜色分解器插入HQS框架,而我们分别处理IDDBM3D和MLP的每个颜色通道。请注意,MLP训练了具有噪声级别2的高斯模糊核的特定模型。


一旦提供了降噪器,随后的关键问题就是参数设置。从方程(6)我们可以注意到有两个参数λ和μ可以调整。通常,对于某一种退化,λ与σ2相关并且在迭代期间保持固定,而μ控制降噪器的噪声水平。由于HQS框架是基于降噪的,因此我们在每次迭代中设置降噪器的噪声水平以隐式确定μ。请注意,降噪器 \(\sqrt{λ/μ}\) 的噪声级别应该从大到小设置。在我们的实验设置中,取决于噪声水平,它从49以指数方式衰减到[1,15]中的值。迭代次数设置为30,因为我们发现它足够大以获得令人满意的性能。
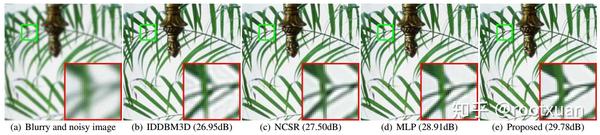
表4显示了不同方法的PSNR结果。可以看出,所提出的基于CNN降噪器的优化方法实现了非常有希望的PSNR结果。图3通过不同的方法说明了去模糊的叶子图像。我们可以看到IDDBM3D,NCSR和MLP倾向于平滑边缘并生成色彩伪像。相反,所提出的方法可以恢复图像的清晰度和自然度。


4.3 单幅图像超分辨率
通常,低分辨率(LR)图像可以通过对高分辨率图像进行模糊处理和随后的下采样操作进行建模。但是,现有的超分辨率模型主要侧重于对图像进行先验建模,并针对特定的退化过程进行训练。当训练中采用的模糊核与实际核模偏离时,这使得学习模型严重恶化[23,64]。相反,我们的模型可以处理任何模糊内核而无需重新训练。因此,为了彻底评估基于CNN降噪器优化方法的灵活性以及CNN降噪器的有效性,本文考虑了[45]中的三种典型的SISR图像退化设置,即比例因子2和3的双三次降采样(默认设置的Matlab函数imresize) [15,21]和7×7大小,标准偏差为1.6的高斯内核模糊,下采样比例因子为3 [22,45]。受到[24]中提出的方法的启发,该方法迭代地更新SISR的反向投影步骤和去噪步骤,我们使用下面的反向投影迭代来求解方程6a,
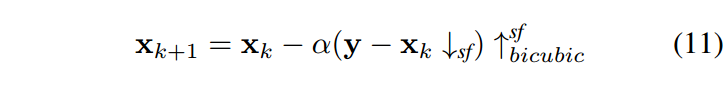

其中 \(↓_{sf}\) 表示具有降尺度因子sf的退化算子, \(↑^{sf}_{bicubic}\) 双三次代表具有放大因子sf的双三次插值算子,并且α是步长。值得指出的是,NCSR和WNNM等方法的迭代正则化步骤实际上对应于求解公式6a。从这个角度来看,这些方法在HQS框架下进行了优化。在这里,请注意,[24]中只考虑双立方下采样,而方程11被扩展来处理不同的模糊内核。为了获得快速收敛,我们重复公式11五次,然后应用降噪步骤。主迭代的数量设置为30,步长α固定为1.75,降噪器的噪声水平从12×sf指数衰减到sf。
提出的基于深度CNN降噪先验的SISR方法与五种最先进的方法进行了比较,包括两种基于CNN的判别式学习方法(即SRCNN [21]和VDSR [35]),一种基于统计预测模型的判别式学习方法[45],我们称之为SPMSR,一种基于模型的优化方法(即NCSR [22])和一种基于降噪先验的方法(即SRBM3D [24])。除了SRBM3D以外,所有现有的方法都是在转换的YCbCr空间的Y通道(即亮度)上进行主要算法。为了评估先前提出的彩色降噪器,我们还对原始RGB通道进行了实验,并给出了不同方法的超分辨RGB图像的PSNR结果。由于SRBM3D的源代码不可用,我们还比较了两种用BM3D / CBM3D降噪器代替CNN降噪器的方法。这两种方法分别由SRBM3DG和SRBM3DC表示。
表5显示了在Set5和Set14上SISR的不同方法的平均PSNR(dB)结果[59]。请注意,SRCNN和VDSR是用双三次模糊核进行训练的,因此使用它们的模型以高斯内核去超分低分辨率图像是不公平的。事实上,我们给他们的演示证明了这种区别学习方法的局限性。
从表5,我们可以看出几点。首先,虽然SRCNN和VDSR取得了很好的结果来解决双三次内核的情况,但当低分辨率图像不是由双三次内核产生时,其性能严重恶化(见图4)。另一方面,对于精确的模糊核,对于高斯模糊核,即使NCSR和SPMSR也优于SRCNN和VDSR。相反,所提出的方法(由ProposedG和ProposedC表示)可以很好地处理所有情况。其次,所提出的方法具有比SRBM3DC和SRBM3DG更好的PSNR结果,这表明良好的降噪器有利于解决超分辨率问题。第三,基于CNN降噪器的灰色和彩色优化方法都可以产生有前途的结果。作为测试速度比较的一个例子,我们的方法可以在0.5秒内在GPU上超分蝴蝶图片,在CPU上超过12秒,而NCSR在CPU上花费198秒。
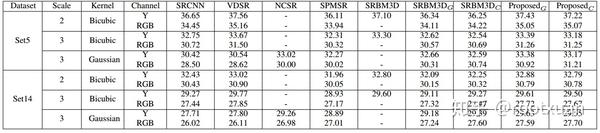



图4.来自Set5的蝴蝶图像的单个图像超分辨率性能比较(模糊内核是具有标准偏差1.6的7×7高斯内核,比例因子是3)。请注意,与SRCNN和VDSR的比较是不公平的。提出的基于深度CNN降噪器优化的方法可以通过调整模糊核和尺度因子而无需训练来超分辨LR图像,而SRCNN和VDSR需要额外的训练来处理这种情况。因此,这个图主要用来显示基于CNN降噪器优化方法的区分性学习方法的灵活性优势。
5 结论
在本文中,我们设计和训练了一套快速有效的CNN图像降噪器。特别是,借助变量切分技术,我们将学习过的降噪器事先插入HQS的基于模型的优化方法中,以解决图像去模糊和超分辨率问题。广泛的实验结果表明,基于模型的优化方法和区分性CNN降噪器的集成为各种图像恢复任务提供了灵活,快速和有效的框架。一方面,与传统的基于模型的优化方法不同,为了获得良好的结果,该方法需要复杂的图像先验,这通常是很耗时的,因为快速CNN降噪器的插件,所提出的深度CNN降噪器基于优先的方法可以有效实现。另一方面,与专门用于某些图像恢复任务的判别式学习方法不同,所提出的基于深度CNN降噪器先验的优化方法在处理各种任务时具有灵活性,同时可产生非常有利的结果。总之,这项工作突出了集成灵活的基于模型的优化方法和快速判别学习方法的潜在益处。此外,这项工作表明,学习有表现力的CNN降噪先验对建模图像先验是一个很好的替代。
虽然我们已经证明了将强大的CNN降噪器插入基于模型的优化方法的各种优点,但还有待进一步研究。一些研究方向如下。首先,研究如何减少判别式CNN降噪器的数量和整个迭代的次数将是有趣的。其次,将提出的基于CNN降噪器的HQS框架扩展到其他逆问题,如图像修补和盲去模糊也会很有趣。第三,利用多种先进技术来提高性能是一个有希望的方向。最后,也许最有趣的是,由于HQS框架可以被视为MAP推理,因此这项工作还提供了一些有关设计CNN架构以用于特定任务的判别式学习。同时,应该意识到CNN有其自己的设计灵活性,最好的CNN架构不一定受MAP推理的启发。
6 致谢
本研究得到香港研资局综合研究基金(PolyU 5313 / 13E)和国家自然科学基金(批准号:61672446,61671182)的支持。我们非常感谢NVIDIA公司为我们提供用于本研究的Titan X GPU的支持。
References
[1] H. C. Andrews and B. R. Hunt. Digital image restoration.
Prentice-Hall Signal Processing Series, Englewood Cliffs:
Prentice-Hall, 1977, 1, 1977. 1
[2] A. Barbu. Training an active random field for real-time image denoising. IEEE Transactions on Image Processing,
18(11):2451–2462, 2009. 1
[3] A. Beck and M. Teboulle. A fast iterative shrinkagethresholding algorithm for linear inverse problems. SIAM
journal on imaging sciences, 2(1):183–202, 2009. 3
[4] J. M. Bioucas-Dias and M. A. Figueiredo. A new TwIST:
Two-step iterative shrinkage/thresholding algorithms for image restoration. IEEE Transactions on Image Processing,
16(12):2992–3004, 2007. 3
[5] S. Boyd, N. Parikh, E. Chu, B. Peleato, and J. Eckstein. Distributed optimization and statistical learning via the alternating direction method of multipliers. Foundations and Trends
in Machine Learning, 3(1):1–122, 2011. 2
[6] A. Brifman, Y. Romano, and M. Elad. Turning a denoiser
into a super-resolver using plug and play priors. In IEEE
International Conference on Image Processing, pages 1404–
1408, 2016. 2
[7] A. Buades, B. Coll, and J.-M. Morel. A non-local algorithm
for image denoising. In IEEE Conference on Computer Vision and Pattern Recognition, volume 2, pages 60–65, 2005.
3
[8] H. C. Burger, C. J. Schuler, and S. Harmeling. Image denoising: Can plain neural networks compete with BM3D? In
IEEE Conference on Computer Vision and Pattern Recognition, pages 2392–2399, 2012. 2, 5
[9] P. Campisi and K. Egiazarian. Blind image deconvolution:
theory and applications. CRC press, 2016. 1
[10] A. Chambolle. An algorithm for total variation minimization and applications. Journal of Mathematical imaging and
vision, 20(1-2):89–97, 2004. 3
[11] A. Chambolle and T. Pock. A first-order primal-dual algorithm for convex problems with applications to imaging.
Journal of Mathematical Imaging and Vision, 40(1):120–
145, 2011. 2
[12] S. H. Chan, X. Wang, and O. A. Elgendy. Plug-and-Play
ADMM for image restoration: Fixed-point convergence and
applications. IEEE Transactions on Computational Imaging,
3(1):84–98, 2017. 2
[13] Y. Chen and T. Pock. Trainable nonlinear reaction diffusion:
A flexible framework for fast and effective image restoration.
IEEE transactions on Pattern Analysis and Machine Intelligence, 2016. 1, 5
[14] P. L. Combettes and V. R. Wajs. Signal recovery by proximal
forward-backward splitting. Multiscale Modeling & Simulation, 4(4):1168–1200, 2005. 3
[15] Z. Cui, H. Chang, S. Shan, B. Zhong, and X. Chen. Deep
network cascade for image super-resolution. In European
Conference on Computer Vision, pages 49–64, 2014. 7
[16] K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian. Color
image denoising via sparse 3D collaborative filtering with
grouping constraint in luminance-chrominance space. In
IEEE International Conference on Image Processing, volume 1, pages I–313, 2007. 3
[17] K. Dabov, A. Foi, V. Katkovnik, and K. Egiazarian. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Transactions on Image Processing,
16(8):2080–2095, 2007. 2, 3, 5
[18] A. Danielyan, V. Katkovnik, and K. Egiazarian. Image deblurring by augmented lagrangian with BM3D frame prior.
In Workshop on Information Theoretic Methods in Science
and Engineering, pages 16–18, 2010. 2
[19] A. Danielyan, V. Katkovnik, and K. Egiazarian. BM3D
frames and variational image deblurring. IEEE Transactions
on Image Processing, 21(4):1715–1728, 2012. 2, 6
[20] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. FeiFei. Imagenet: A large-scale hierarchical image database. In
IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009. 5
[21] C. Dong, C. C. Loy, K. He, and X. Tang. Image
super-resolution using deep convolutional networks. IEEE
transactions on Pattern Analysis and Machine Intelligence,
38(2):295–307, 2016. 2, 7
[22] W. Dong, L. Zhang, G. Shi, and X. Li. Nonlocally centralized sparse representation for image restoration. IEEE Transactions on Image Processing, 22(4):1620–1630, 2013. 2, 6,
7
[23] N. Efrat, D. Glasner, A. Apartsin, B. Nadler, and A. Levin.
Accurate blur models vs. image priors in single image superresolution. In IEEE International Conference on Computer
Vision, pages 2832–2839, 2013. 7
[24] K. Egiazarian and V. Katkovnik. Single image superresolution via BM3D sparse coding. In European Signal
Processing Conference, pages 2849–2853, 2015. 2, 7
[25] M. Elad and M. Aharon. Image denoising via sparse and
redundant representations over learned dictionaries. IEEE
Transactions on Image processing, 15(12):3736–3745, 2006.
3
[26] A. Foi, V. Katkovnik, and K. Egiazarian. Pointwise
shape adaptive DCT denoising with structure preservation
in luminance-chrominance space. In International Workshop
on Video Processing and Quality Metrics for Consumer Electronics, 2006. 3
[27] Q. Gao and S. Roth. How well do filter-based MRFs model
natural images? In Joint DAGM (German Association for
Pattern Recognition) and OAGM Symposium, pages 62–72,
2012. 2
[28] D. Geman and C. Yang. Nonlinear image recovery with halfquadratic regularization. IEEE Transactions on Image Processing, 4(7):932–946, 1995. 2
[29] S. Gu, L. Zhang, W. Zuo, and X. Feng. Weighted nuclear
norm minimization with application to image denoising. In
IEEE Conference on Computer Vision and Pattern Recognition, pages 2862–2869, 2014. 2, 5
[30] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning
for image recognition. In IEEE Conference on Computer
Vision and Pattern Recognition, pages 770–778, 2016. 4
[31] F. Heide, M. Steinberger, Y.-T. Tsai, M. Rouf, D. Pajak,
D. Reddy, O. Gallo, J. Liu, W. Heidrich, K. Egiazarian,
et al. Flexisp: A flexible camera image processing framework. ACM Transactions on Graphics, 33(6):231, 2014. 2
[32] S. Ioffe and C. Szegedy. Batch normalization: Accelerating
deep network training by reducing internal covariate shift. In
International Conference on Machine Learning, pages 448–456, 2015. 2, 4
[33] M. Irani and S. Peleg. Motion analysis for image enhancement: Resolution, occlusion, and transparency. Journal of
Visual Communication and Image Representation, 4(4):324–
335, 1993. 7
[34] V. Jain and S. Seung. Natural image denoising with convolutional networks. In Advances in Neural Information Processing Systems, pages 769–776, 2009. 2
[35] J. Kim, J. K. Lee, and K. M. Lee. Accurate image superresolution using very deep convolutional networks. In IEEE
Conference on Computer Vision and Pattern Recognition,
pages 1646–1654, 2016. 4, 7
[36] D. Kingma and J. Ba. Adam: A method for stochastic optimization. In International Conference for Learning Representations, 2015. 2, 5
[37] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet
classification with deep convolutional neural networks. In
Advances in Neural Information Processing Systems, pages
1097–1105, 2012. 2
[38] A. Levin, Y. Weiss, F. Durand, and W. T. Freeman. Understanding and evaluating blind deconvolution algorithms. In
IEEE Conference on Computer Vision and Pattern Recognition, pages 1964–1971, 2009. 6
[39] Z. Lin, M. Chen, and Y. Ma. The augmented lagrange multiplier method for exact recovery of corrupted low-rank matrices. arXiv preprint arXiv:1009.5055, 2010. 5
[40] K. Ma, Z. Duanmu, Q. Wu, Z. Wang, H. Yong, H. Li, and
L. Zhang. Waterloo exploration database: New challenges
for image quality assessment models. IEEE Transactions on
Image Processing, 26(2):1004–1016, 2017. 5
[41] J. Mairal, M. Elad, and G. Sapiro. Sparse representation for
color image restoration. IEEE Transactions on Image Processing, 17(1):53–69, 2008. 3
[42] T. Miyata. Inter-channel relation based vectorial total variation for color image recovery. In IEEE International Conference on Image Processing,, pages 2251–2255, 2015. 3
[43] S. Osher, M. Burger, D. Goldfarb, J. Xu, and W. Yin. An iterative regularization method for total variation-based image
restoration. Multiscale Modeling & Simulation, 4(2):460–
489, 2005. 3
[44] N. Parikh, S. P. Boyd, et al. Proximal algorithms. Foundations and Trends in optimization, 1(3):127–239, 2014. 2
[45] T. Peleg and M. Elad. A statistical prediction model based
on sparse representations for single image super-resolution.
IEEE Transactions on Image Processing, 23(6):2569–2582,
2014. 7
[46] A. Rajwade, A. Rangarajan, and A. Banerjee. Image denoising using the higher order singular value decomposition.
IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(4):849–862, 2013. 3
[47] W. H. Richardson. Bayesian-based iterative method of image
restoration. JOSA, 62(1):55–59, 1972. 1
[48] Y. Romano, M. Elad, and P. Milanfar. The little engine that
could regularization by denoising (RED). arXiv preprint
arXiv:1611.02862, 2016. 2
[49] A. Rond, R. Giryes, and M. Elad. Poisson inverse problems
by the plug-and-play scheme. Journal of Visual Communication and Image Representation, 41:96–108, 2016. 2
[50] S. Roth and M. J. Black. Fields of experts. International
Journal of Computer Vision, 82(2):205–229, 2009. 1, 4, 5
[51] U. Schmidt and S. Roth. Shrinkage fields for effective image
restoration. In IEEE Conference on Computer Vision and
Pattern Recognition, pages 2774–2781, 2014. 1
[52] C. J. Schuler, H. Christopher Burger, S. Harmeling, and
B. Scholkopf. A machine learning approach for non-blind
image deconvolution. In IEEE Conference on Computer Vision and Pattern Recognition, pages 1067–1074, 2013. 6
[53] K. Simonyan and A. Zisserman. Very deep convolutional
networks for large-scale image recognition. In International
Conference for Learning Representations, 2015. 4
[54] S. Sreehari, S. Venkatakrishnan, B. Wohlberg, L. F. Drummy, J. P. Simmons, and C. A. Bouman. Plug-and-play priors
for bright field electron tomography and sparse interpolation.
arXiv preprint arXiv:1512.07331, 2015. 2
[55] J. Sun and M. F. Tappen. Separable markov random field
model and its applications in low level vision. IEEE Transactions on Image Processing, 22(1):402–407, 2013. 1
[56] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed,
D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich.
Going deeper with convolutions. In IEEE Conference on
Computer Vision and Pattern Recognition, June 2015. 4
[57] M. F. Tappen. Utilizing variational optimization to learn
markov random fields. In IEEE Conference on Computer
Vision and Pattern Recognition, pages 1–8, 2007. 1
[58] A. M. Teodoro, J. M. Bioucas-Dias, and M. A. Figueiredo.
Image restoration and reconstruction using variable splitting
and class-adapted image priors. In IEEE International Conference on Image Processing, pages 3518–3522, 2016. 2
[59] R. Timofte, V. De Smet, and L. Van Gool. A+: Adjusted
anchored neighborhood regression for fast super-resolution.
In Asian Conference on Computer Vision, pages 111–126,
2014. 7
[60] A. Vedaldi and K. Lenc. MatConvNet: Convolutional neural networks for matlab. In ACM Conference on Multimedia
Conference, pages 689–692, 2015. 5
[61] S. V. Venkatakrishnan, C. A. Bouman, and B. Wohlberg.
Plug-and-play priors for model based reconstruction. In
IEEE Global Conference on Signal and Information Processing, pages 945–948, 2013. 2
[62] L. Xu, J. S. Ren, C. Liu, and J. Jia. Deep convolutional neural
network for image deconvolution. In Advances in Neural
Information Processing Systems, pages 1790–1798, 2014. 2
[63] F. Yu and V. Koltun. Multi-scale context aggregation by dilated convolutions. arXiv preprint arXiv:1511.07122, 2015.
2, 4
[64] K. Zhang, X. Zhou, H. Zhang, and W. Zuo. Revisiting single image super-resolution under internet environment: blur
kernels and reconstruction algorithms. In Pacific Rim Conference on Multimedia, pages 677–687, 2015. 7
[65] K. Zhang, W. Zuo, Y. Chen, D. Meng, and L. Zhang. Beyond a Gaussian denoiser: Residual learning of deep CNN
for image denoising. IEEE Transactions on Image Processing, 2017. 4
[66] D. Zoran and Y. Weiss. From learning models of natural image patches to whole image restoration. In IEEE International Conference on Computer Vision, pages 479–486, 2011. 1,
2, 3, 5
