自编码器入门 Auto-encoder

自然语言处理
自编码器入门 Auto-encoder
原视频地址:ML Lecture 16: Unsupervised Learning - Auto-encoder - YouTube
自编码器是无监督学习算法。首先编码器对输入进行编码,获得某种紧凑的有效的输入目标的表示;然后解码器对该编码进行解码,对原有对象进行重构。
因为是无监督算法,实际上编码器和解码器并不能分别进行训练,但二者可以在一个模型中一并训练。
从主成分分析开始
这一过程类似于主成分分析。PCA 的目标是降维前对象和降维后对象之间的差别尽量小。 隐藏层称为 bottleneck layer 的原因是,编码的维度相对来说很小。
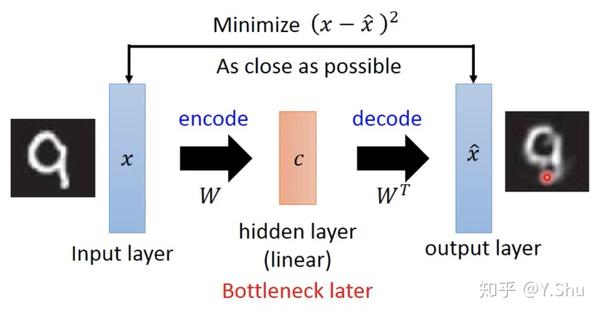

深度自编码器
如果隐藏层数比较多,就构建为一个深度自编码器。
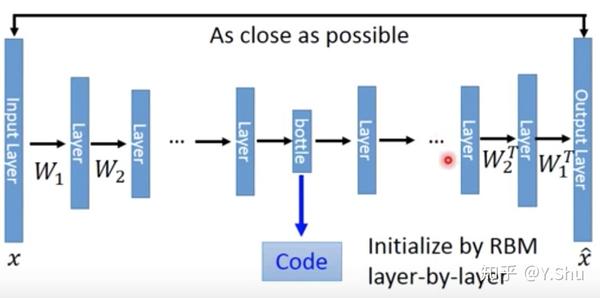

相比于主成分分析,深度自编码器表现出了惊人的性能。
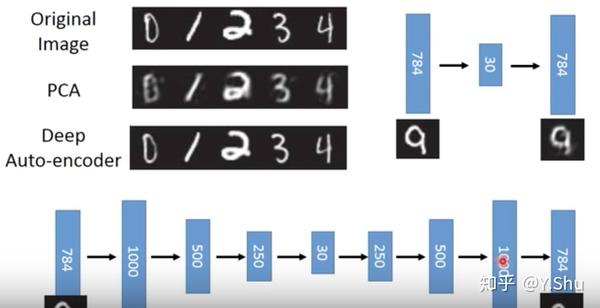

文本检索
将每篇文档(document)都表示为向量空间中的一个点,将查询词(query)也表示为向量,与每一篇文档向量计算点积(dot-product)或余弦相似度等。
使用词袋模型,输出降低到二维,可在图中分析出不同的文档特征。 相对而言,LSA 模型无法输出这样清晰的结果。

相似图片搜索
使用自编码器,比较图片之间的编码的方法,相比于按像素比较图片的方法,能更好地找到相似图片。


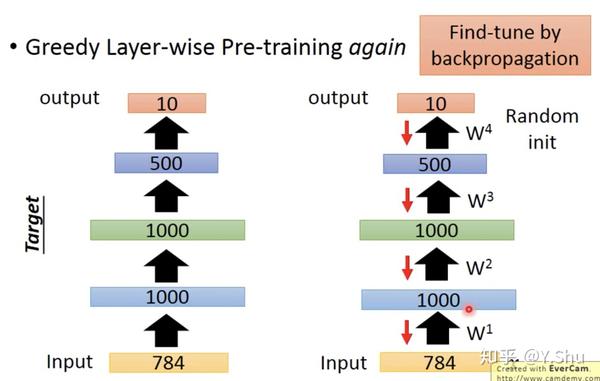
预训练深度神经网络
预训练目前主要适用于有大量未标记数据时。如图可以先预训练 W1、W2、W3,然后在微调中再学习 W4。

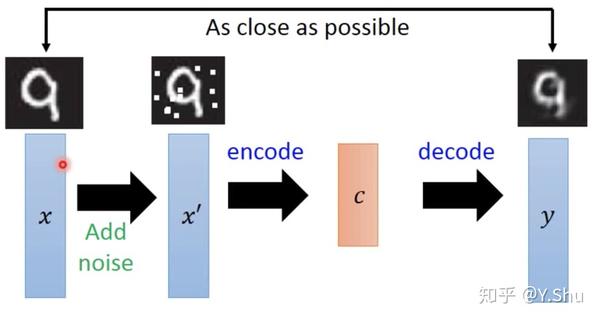
降噪自编码器
将原始输入加上噪音,然后编码、解码。学习的目标是使解码后结果与加噪音之前的原始输入之间差距最小。这可以使模型的健壮性更强,模型有一定对噪音过滤的能力。

了解更多: - 受限玻尔兹曼机 - 深度信念网络 这二者并不是神经网络方法。
CNN 自动编码
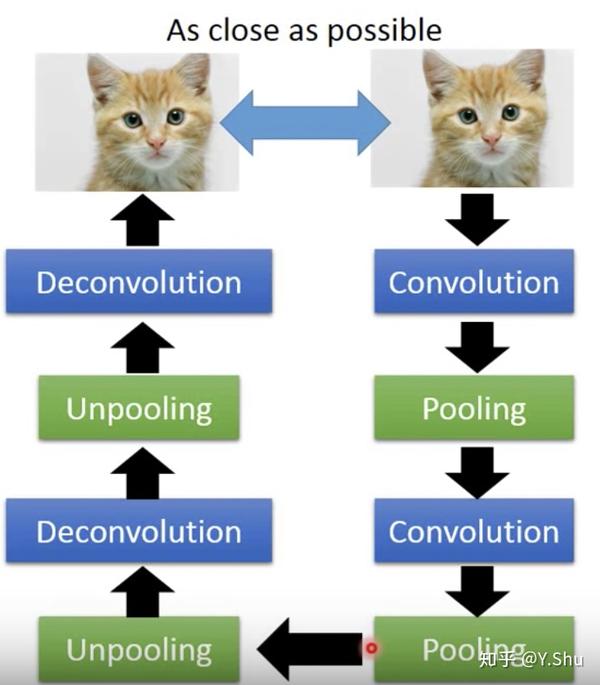

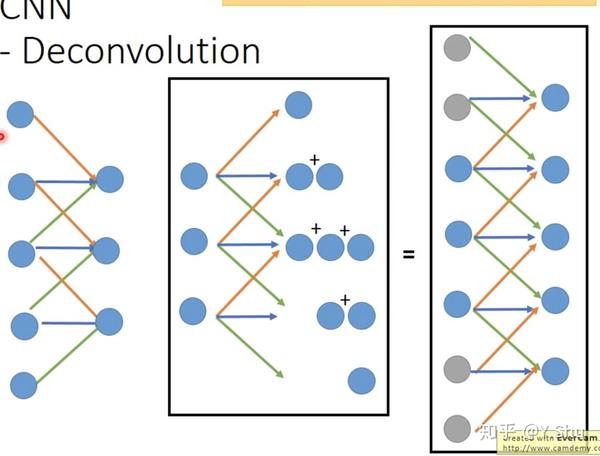
CNN-反池化
池化过程中,记忆被提取特征的位置,用于反池化。不是被提取特征的位置填 0,或填充与被提取值相同的值。
实际上,反池化的本质就是池化,如图所示。填充后的池化就是所称的反池化。

发布于 2019-10-26 22:37