
论文笔记12: adaptiveTutoring Model

论文笔记12:《Building Adaptive Tutoring Model using Artificial Neural Networks and Reinforcement Learning》
参考文献:Building Adaptive Tutoring Model Using Artificial ..._百度学术
Abstract
随着新技术支持的学习环境出现(例如,mooc,移动edu游戏),高效的辅导机制仍然与传统的智能辅导系统相关。本文提出了一种利用人工神经网络和强化学习来构建辅导模型的方法。基本的想法是,辅导规则可以是,首先,通过观察人类导师的行为,然后在运行时,通过观察每个学习者在学习过程的不同状态下的学习环境中如何反应,从而学习。利用最优发展区基础理论来评价学习经验的有效性和效率。
Introduction
人工智能的方法和工具已经嵌入到传统的计算机辅助教学导师中,以增加智能决策能力。从本质上讲,在一个给定的学习环境,一个智能辅导系统(ITS)旨在通过监控学习者的互动来模拟人类的导师的行为。
ITS通过导航有序学习活动,识别情况反馈,提供适当的个性化的提示,以更好地支持个人学习需求[1]。这种系统可以实时改变其辅导行为,遵循个体学习者的策略和行为的差异。它的行为可以通过考虑外部循环和内部循环来描述。特别地,本文讨论的是外部循环,它为学习者提供了不同难度的动态序列(通常是解决问题的方法)。
默认的行为是,如果成功执行了下一个任务,那么下一个任务就会比前一个任务更大。然而,如果学习者的结果是负面的,那么它就可以提供一个难度更低的任务,或者提出一个具有相同难度的任务,但是是另一个学习内容。
通常,ITSs利用列夫维果斯基提出的最优发展区(ZPD)理论。ZPD可以从认知和情感的角度来描述。从认知的角度来看,提议的任务不应该太难或容易;从情感的角度来看,学习者应该避免极端的无聊和困惑和沮丧。无聊和困惑都可能导致分心、沮丧和缺乏动力。
当然,每个学习者的最佳条件是不同的,在不同的学习环境和环境中,对于同一个学习者也是不同的。
通常,一个学习者的ZPD,与给定的学习环境相互作用,是由一个状态空间图来表示的,它说明了学生在任务难度的空间和学习者不断发展的技能水平之间的轨迹。沿着轨迹的进展不一定是线性的。
-----------------------------举例说明
例如,图1描述了两个不同学习者的ZPDs。ZPDs是图1(a)和图1(b)的两条虚线之间的区域。


因此,ZPD根据每个学习者对无聊和困惑的容忍程度不同。一个学习者在她自己的ZPD中展示了高效和有效的学习。随着新技术支持的学习环境的出现(如mooc、移动edu游戏、增强现实玩具、能力开发工具4),高效和有效的辅导机制仍然与传统的ITSs相关。这项工作提出了一种建立辅导模式的方法,特别是在与学习环境的互动过程中,选择下一个任务困难来保持学习者在她的ZPD中。本文提出了一种新颖的方法,既考虑了人类导师的能力/经验,又考虑了个体学生的ZPDs。
Overall approach,整体方法
提出的方法是基于人工神经网络(ANN)与强化学习算法(RL)的结合。这种方法的目的是为学习者提供一个智能助手,能够选择下一个任务难度等级,以使他们保持在特殊的ZPD中。建议的方法侧重于下一个任务选择(NTS)规则的生成和改编。这种方法(见图2中的示意图)由两个主要阶段组成,
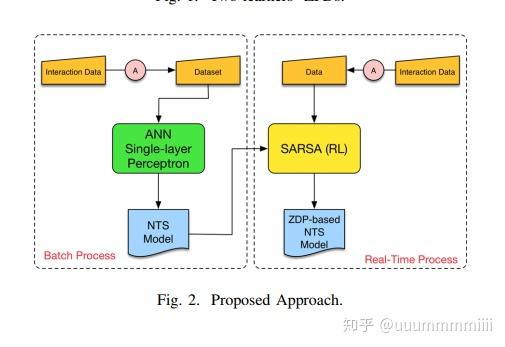

模型的目的是在每个任务结束时,决定下一个任务的适当难度水平。一个合适的选择是提供一个难度等级需要产生NTS(下一任务选择)规则,使学习者能够保持他们的ZPDs。
模型步骤:
第一阶段是通过批处理,ANN通过学习人类导师行为来决定下一个任务难度等级。(建立在导师的经验和能力基础上的模型,并不能直接解决与学习效率相关的问题,在第二阶段上得到改进,建立在一个特定的学习者行为上)
第二阶段是通过强化学习处理来自特定学习者的交互的实时数据。建立在一个特定的学习者的行为上,以便考虑到她的ZPD。因此,该系统学习如何在一个特定的学习者保持她的ZPD中
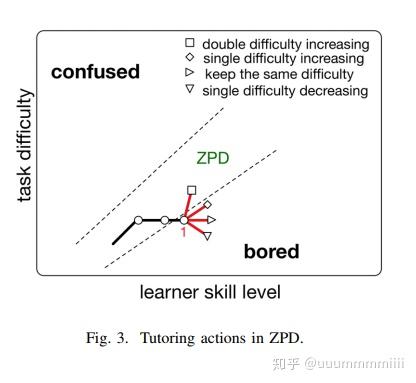
图3显示,在第1点,只有一个辅导动作(增加两个单位当前的难度)可以再次将学习者推入ZPD。所以适当的学习难度,即决定的动作行为,可以保持ZDP
Data gathering and preprocessing数据收集和预处理
数据集:
3个5-6年的学习者在平台上的互动行为
一个教育游戏应用程序(在Android平板上运行)
由专家(人类)老师为这些学习者提供的导师的行为。
观察是在多个会议上收集的,涉及到几个学习者和导师。
----------------------------------------------------------------------------
虽然在以前的工作8中使用了相同的方法来学习反馈和提示的规则,但是现在的工作重点是挖掘NTS规则。
游戏是在问题(任务)中组织的,每个问题都可以通过正确执行一系列步骤来解决。
在每一步的最后,导师会通过提供反馈、提示或其他辅导措施来回应学习者的答案(如告知答案解题思路或题目解答正确与否);在每项任务结束时,导师会选择下一个任务,由学习者来挑战。因此,痕迹代表了学习者的观察和人类导师的行为。跟踪观察值已经被预处理,以便分析与任务相关的不同步骤的任务。
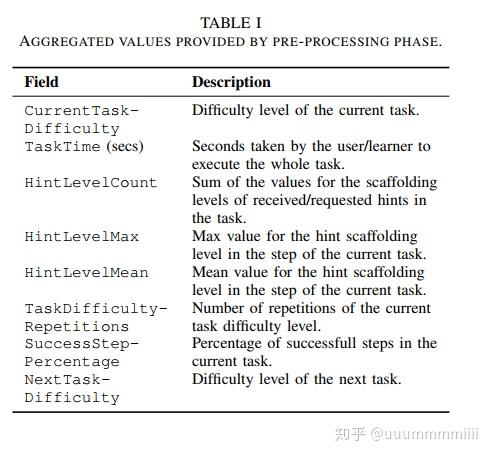

因此,预处理的数据集被格式化为表I中报告的格式,特别是,nexttaskdifficulty字段包含一个符号,表示由导师提供的NTS操作。
≡符号代表,下一个任务将有相同的困难的,
≻符号代表,下一任务有一个增量的难度(对当前任务),
≫符号表示,下一任务有增量2的难度水平(对当前任务),
≺符号表示,下一任务有一个减量的难度(对当前任务),
Learning tutoring rules by ANN(实验中ANN规则)
这个阶段是数据集是预处理获得数据。NTS规则重新定义为一个分类问题。
主要的想法是通过ANN学习人类导师行为(即处于某一个状态时,与学习者进行的交互行为)构建分类模型
下一个任务难易程度的可接受值成为问题的目标类。
输入层接收7个值,输入值对应于表I的前七个字段,激活函数relu
输出层生成5个值。输出由五个元素的向量编码,这些元素编码了5个难度字段,输出层的激活函数是softmax。
ANN在交叉熵的情况下接受训练,学习率为=0.01,用Adam算法对损失函数进行随机梯度下降优化。学习者与一个任务相互作用,反过来,它收集的交互数据成为NTS模型的输入,从而预测下一个任务的困难。
ADAPTATION APPROACH FOR TUTORING RULES 辅导规则的适应方法
人类导师的行为是高度适应的。
事实上对于tutor:
1)估计ZPD和学习者与学习环境互动的当前状态,
2)决定向学习者提出的下一个任务,
3)向她提交这样的任务。
NTS模型无法实现决策,可以采用强化学习(RL)。这个想法是在一个特定的任务中收集学习者的适应度表现,并将其与之前的辅导行动联系起来。在上一项任务结束时由自动导师执行的NTS动作。因此,我们的想法是使用RL,考虑一个自动代理,它学习如何在每个状态中选择最合适的动作(下一个任务难度级别),使学习者保持在ZPD中。为了说明代理是如何根据其经验改变其策略的,可以采用Sarsa算法,通过执行-贪婪选择来进行开发和开发。
experiment
执行三个实验(观察三个学习者),以证明从人类导师的经验(由ANN学习)中获得的辅导行为可以通过考虑学习者的反馈(RL算法获得和使用)来进行调整。
在每一个实验中,都选择了一个特定的状态。然后,汇总组从这种状态开始的学习者行为。通过这种方式,我们可以理解RL算法是如何通过考虑学习者的ZPD来适应辅导规则的。第二个实验上,ANN预测下一行为是保持当前难易程度,但是RL算法得到要保持舒适度应该增加一增量难度。特别地,在三次迭代之后,权重分别为-0.01和0.1。在6次迭代之后,保持难易动作没有选中,权重是-0.01和0.27。最后,在9次迭代之后,会有更多的选择,因此权重是-0.05和0.35。因此,该系统在几个步骤中实现了对NTS规则的稳定适应。
conclusion
该方法将单层感知器与Sarsa算法集成在一起,以学习和适应ITSs的下一个任务选择规则。这种方法的主要优点是将人类导师的能力与同样的导师在观察和分析学习者行为、预测她的ZPD并调整他们的辅导策略时所做的适应相结合。
个人理解:ANN与RL分开进行