AAAI 2020 有哪些值得关注的 Paper ?



本次AAAI会议是进入21世纪20年代(一个将真正属于人工智能的十年)中首个会议。但这次会议却因中国新冠疫情而出现别具一格的场面,许多国内近800名小伙伴因疫情影响无法到现场参加会议,导致许多会议的技术报告出现整场在播放视频。这也成为首个进行“云参会”的AI顶会,甚至有人建议以后会议应该允许作者不到现场进行报告。
在本届会议中,京东数科共有 6 篇论文入选,其中 1篇涉及语义分割,1篇为对抗生成,1 篇与图机器学习有关,3 篇为算法研究。
接下来就让我们康康这些优秀的paper各自有哪些亮点叭~
一、语义分割研究
1、基于空间语义网络调制的深度协同物体分割


论文链接:https://arxiv.org/pdf/1911.12950.pdf
协同目标分割是对多幅相关图像中的共同目标进行分割。在很多计算机视觉相关问题中,协同目标分割都有着广泛的应用。


本文提出了一个基于空间和语义调制的协同分割深度学习网络框架。
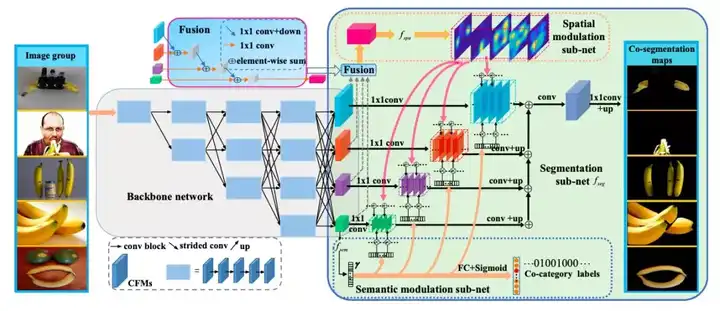

该方法首先用骨干网提取多分辨率图像特征。之后我们用图像的多分辨率深度特征作为输入,采用文中所设计的空间调制器来学习每个图像的掩模。
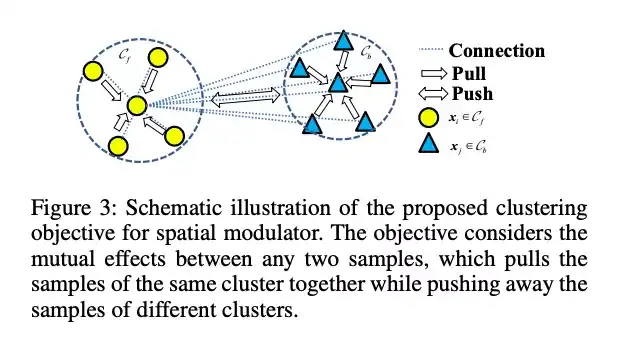

空间调制器通过无监督学习获取图像特征描述符的相关性,学习得到的掩模可以在抑制背景的同时定位目标物体。我们将语义调制器建模为一个有监督的图像分类任务。
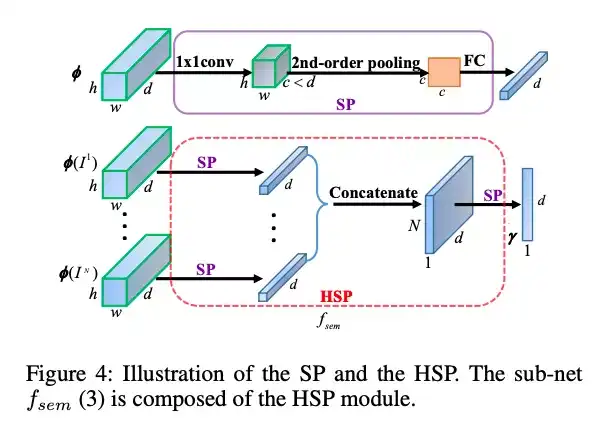

在语义调制器模块我们提出了一个多级的二阶池化模块对图像特征做变换以供分类使用。这两个调制器的引入能够指导网络提取更有针对性的图像特征。
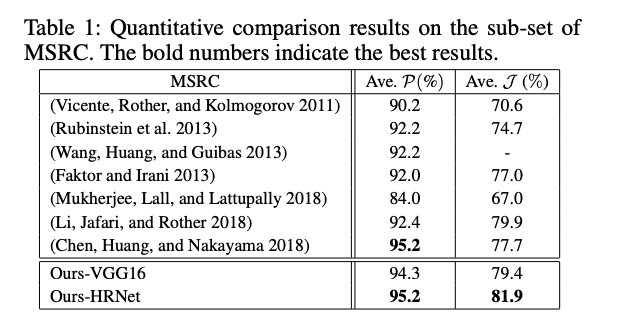

所提出的模型采用端到端训练。在四个图像协同分割基准数据集上的大量实验表明,与最新方法相比,我们的方法具有更高的精度。
二、对抗生成研究
2、基于成对比较样本标注的鲁棒条件生成对抗网络


论文链接:https://arxiv.org/pdf/1911.09298v1.pdf
条件对抗生成网络(conditional GAN, CGAN)在图片属性编辑等领域有成功的应用。但是,训练CGAN往往需要大量标注。
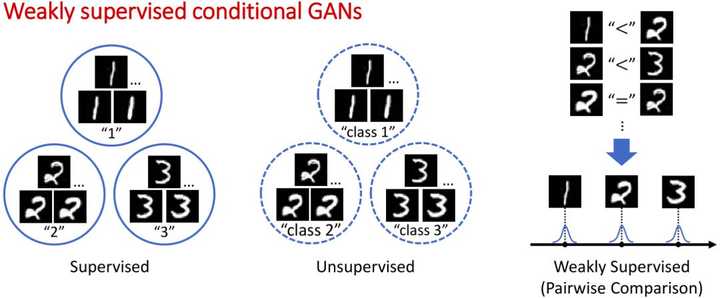

针对这一问题,现有方法大多基于无监督聚类,比如先用无监督学习方法得到伪标注,再用伪标注当作真标注训练CGAN。然而,当目标属性是连续值而非离散值,或者目标属性不能表征数据间的主要差异,那么这种基于无监督聚类的方法就难以取得理想效果。我们进而考虑用弱监督信息去训练CGAN,在文中我们考虑成对比较这种弱监督。成对比较相较于绝对标注具有以下优点:1.更容易标注;2.更准确;3.不易受主观影响。
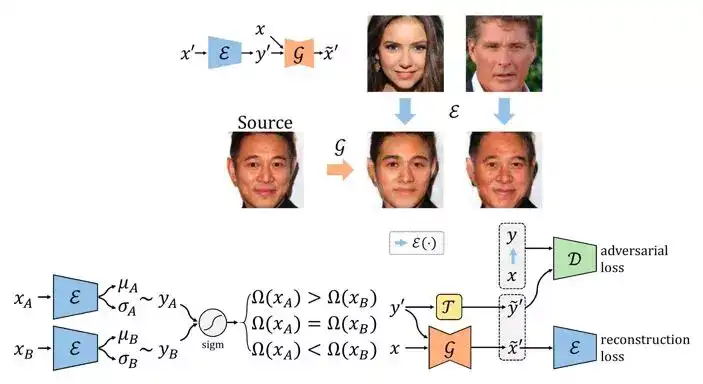

我们提出先训练一个比较网络来预测每张图片的得分,再将这个得分当做条件训练CGAN。第一部分的比较网络我们受到国际象棋等比赛中常用的等级分(Elo rating system)算法的启发,将一次成对比较的标注视为一次比赛,用一个网络预测图片的得分,我们根据等级分设计了可以反向传播学习的神经网络。
我们还考虑了网络的贝叶斯版本,使网络具有估计不确定性的能力。对于图像生成部分,我们将鲁棒条件对抗生成网络(Robust Conditional GAN, RCGAN)拓展到条件是连续值的情形。
我们在四个数据集上进行了实验,分别改变人脸图像的年龄和颜值。实验结果表明提出的弱监督方法和全监督基线相当,并远远好于非监督方法。
三、图机器学习研究
3、基于小样本学习的知识图谱补全


论文链接:https://arxiv.org/pdf/1911.11298.pdf
知识图谱作为重要的数据资源已经被大量应用于推荐以及自然语言处理的各项应用当中。在实际场景中,知识图谱的不完整性则作为一个重要的研究课题。
尽管大量的知识图谱补全的算法致力于解决该问题,当前算法都依赖于大量的训练数据才能较好地学习到知识图谱中各类节点间的关系。在实际的应用场景中,训练数据缺失的情况普遍存在。因此,一个更加实际的场景是如何在有限的训练数据中,准确地通过对各种模态关系的研究学习,从而对不完整的知识图谱进行补全。
为了解决该问题,本文提出了一种基于小样本的知识图谱关系学习架构来预测在知识图谱中各类实体节点间的连接关系。
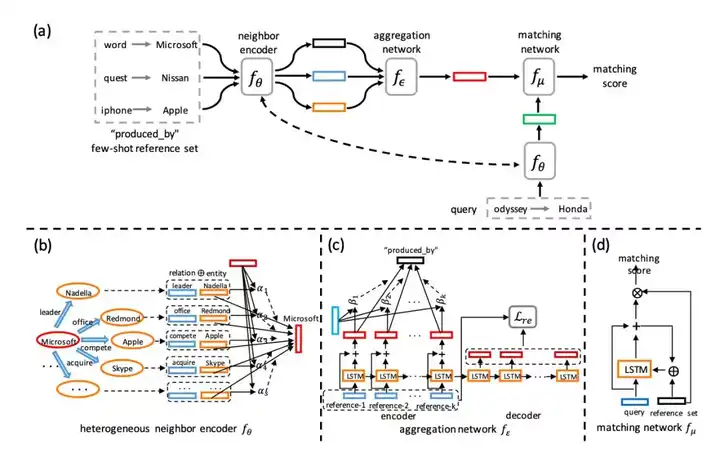

模型架构图
在所提出的方法架构中,我们首先设计了一种基于注意力机制的异构网络中邻接关系的编码器。该编码器能够在对到在异构网络中实体节点嵌入学习的过程中,考虑到不同邻居节点以及其对应的不同关系的影响。
其次,我们开发了一种基于循环神经网络的自编码架构来对小样本中不同实体样例间的交互信息。通过对该实体间交互的建模,我们可以更好地发现在知识图谱中具有相同特性的实体节点,从而精确地补全知识图谱中缺失的相关信息。
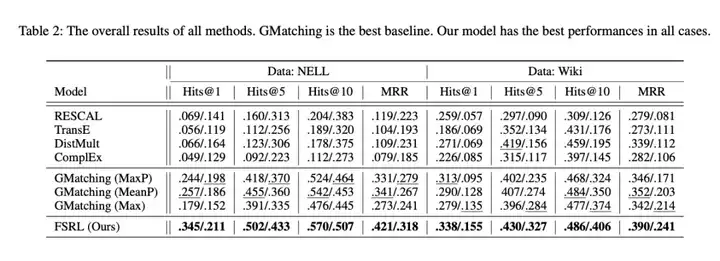

通过在两个公共知识图谱数据集上和现有算法的对比实验,我们验证了提出的方法能够产生更好的知识图谱补全的结果。
四、算法研究
4、针对鲁棒支持向量机的快速数据筛选算法


论文地址:https://arxiv.org/pdf/1912.11217.pdf
在现实机器学习应用中,我们经常使用鲁棒支持向量机提高预测性能,减小噪声的影响。由于鲁棒支持向量机使用非凸的的目标函数,差分优化方法经常被采用来计算,并使用多个外循环,从而大大地增加了计算复杂性,限制了鲁棒支持向量机在大数据上的使用。


在我们最新的工作,我们设计了新的快速数据筛选算法,快速找到并去掉代表性差的数据,在不影响预测结果的前提下,大大降低训练数据的数目,从而解决了鲁棒支持向量机无法在大数据上应用的难点。
已有的快速数据筛选算法只能使用在凸的目标函数上,因此不能直接应用到鲁棒支持向量机模型。


因此我们设计了新的快速数据筛选算法,基于凸函数和凹函数共同表达的框架,我们提供了新的数据筛选规则,并提供理论支持,保证我们的算法可以筛选到所以有代表性的数据,没有遗漏。
这是第一个针对非凸目标函数的快速数据筛选算法。
我们在多个大数据集上进行了测试,我们的新算法可以大大提高鲁棒支持向量机的效率,从而可以解决大数据中的预测问题。
5、基于四重随机梯度的大规模非线性半监督有序回归AUC优化


论文链接:https://arxiv.org/pdf/1912.11193.pdf
有序回归问题(类别标记存在有序关系)广泛存在于现实世界中,例如天气预报中的级别关系,预警系统中的级别关系, 金融风险预测的级别关系。传统的有序回归算法通常是基于有序二分类分解方法,即将原问题分解为多个二分类的子问题,再最小化子问题的分类误差来进行求解。但是,这种方法会天然的会使每个二分类问题出现类别不均衡的问题。最小化分类误差的方法无法有效的解决这种类别不均衡问题。有研究指出,在有序回归问题中,利用AUC指标类别不明感的特点,直接优化AUC指标能得到一个更好的有序回归模型。
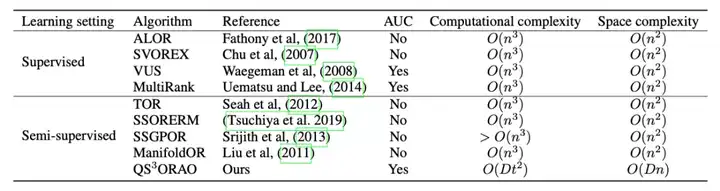

进一步地,在现实问题中,收集大量的有标签的等级数据非常困难。然而存在很多没有标记的数据。如何利用这些无标记数据提升有序回归分类器是一个重要的问题。
本文考虑在半监督有序回归数据集上通过优化AUC指标来训练分类器。通过二分类分解法,我们给出了半监督有序回归AUC优化的目标函数。同时,针对大规模的带有核的优化问题,我们给出一种基于双重随机梯度的优化算法,QS3ORAO。




我们的算法的具有O(1/t)的收敛速度。此外,实验结果表明,我们的算法在速度,处理数据规模方面优于现有的方法,同时具有相似的推广性能。
6、学习从轨迹中生成电子地图


论文链接:
https://www.ntu.edu.sg/home/c.long/paper/AAAI-RuanS.361.pdf
最新且准确的路网数据对于城市中的很多应用,比如车载导航和线路优化等,都非常重要。传统的道路数据采集方法依赖于现场调查,消耗大量的人力物力。
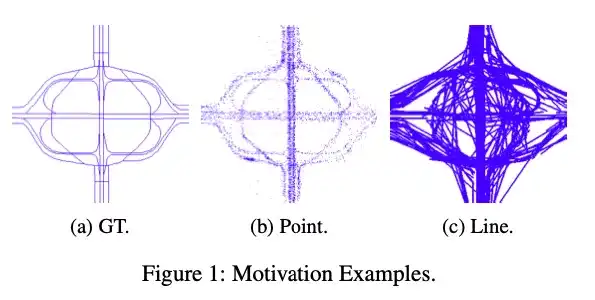

随着GPS设备的普及,海量轨迹数据在城市里产生,给我们提供了一种用轨迹数据生成路网的机遇。但是,现有的轨迹数据恢复地图的方法,需要很多经验参数,并且没有很好的利用现有地图中的先验知识,导致生成的地图被过度简化,或者过度复杂化。
因此,我们提出了一种基于深度学习来从轨迹中生成电子地图的方法DeepMG, 它能够学习现有路网的结构,并克服GPS定位中存在的噪声。DeepMG的框架如下图所示:
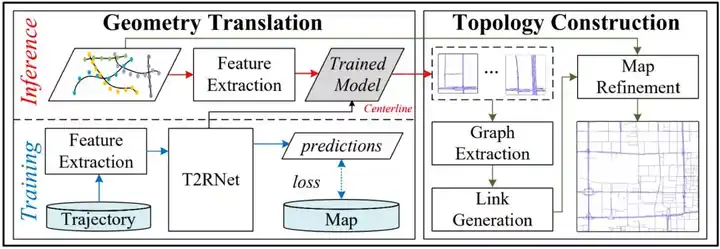

DeepMG框架.
它先从空间视角和转移视角从轨迹中抽取特征,并利用深度卷积神经网络T2RNet(如下图)推测道路中心线。
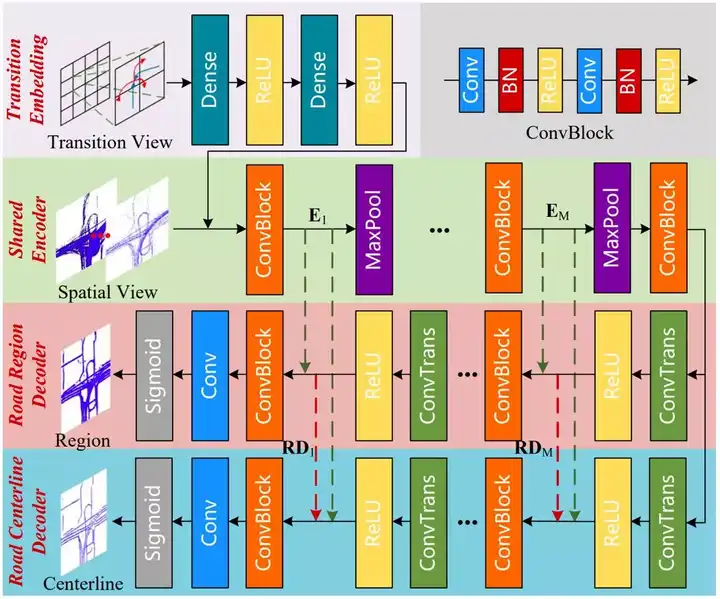

T2RNet网络结构.
T2RNet通过引入辅助任务道路覆盖区域预测,提升中心线预测的准确性。之后,再次利用轨迹数据精细化得到的路网,保证路网拓扑的联通性以及正确性。
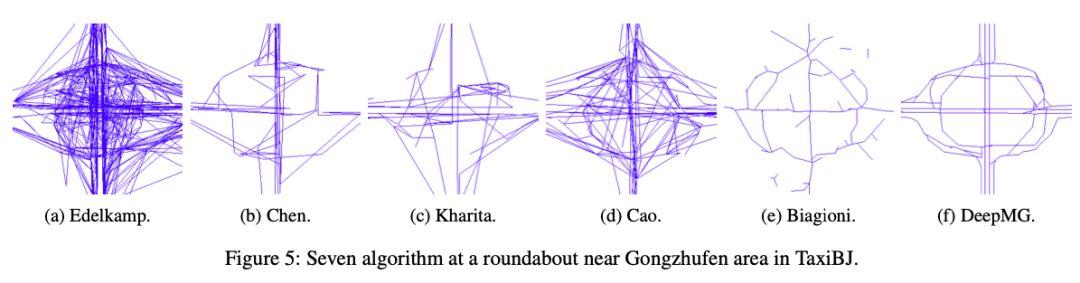

实验表明DeepMG从量化指标和视觉效果上都显著优于非深度学习的方法。
By the way,这篇论文是我们京东城市JUST极客战队撰写的哦,战队小哥哥们可是凭借这篇paper获得了京东数科首届黑客马拉松创新大赛二等奖呢(骄傲脸)~




欢迎大家关注我们的微信公众号“京东城市”了解更多业界前沿资讯哦ε=ε=ε=(~ ̄▽ ̄)~