
【结合知识的预训练二ERNIE】Enhanced language representation with informative entities

引入:语言模型比如BERT在大量的语料中进行无监督的预训练,可以学习丰富的语义知识,然后在不同的NLP下游任务中进行微调,都获得了不错的效果。然而现有的这些预训练语言模型都忽视了知识图谱中的知识,事实上,在预训练的过程中,如果能有效融合这些知识,可以增加语言模型的表达能力。论文提出了一种模型ERNIE让语言模型在训练的过程中融合知识图谱中的知识。论文被发表在了2019年的ACL顶会上。- 名词解释
1.1. entity typing task
1.2. Structured Knowledge Encoding
1.3. Heterogeneous Information Fusion
1.4. ERNIE
- 背景和相关工作
2.1. 基于特征的方法
2.2. 微调的方法
2.3. 不足
- 模型结构
3.1. T-Encoder
3.2. K-Encoder
- 模型效果
4.1. 预训练过程
4.2. 微调过程
4.3. 实体分类任务
4.4. 关系分类任务
Ernie Enhanced language representation with informative entities论文的源码被公布在了github上,有兴趣的同学可以进行实验并研究实现细节。
1. 名词解释
1.1. entity typing task
实体类型识别任务,输入一句话比如:
Bob Dylan wrote Blowin’ in the Wind in 1962, and wrote Chronicles: Volume One in 2004.实体类型识别任务的目的是识别出这句话的实体Bob Dylan的类型,(在这里是songwriter或者writer)。从这个例子可以看出如果事先不知道Blowin’ in the Wind和Chronicles: Volume One是什么类型(在这里是音乐和书),很难识别出实体Bob Dylan的类型。
1.2. Structured Knowledge Encoding
这是将知识图谱融合到语言表达模型的一个通用的挑战,即给定一篇文本,如何有效的将与这篇文本在知识图谱中相关的知识进行融合预训练(如何将知识图谱中的知识进行encode融合在语言表达模型中是一个挑战)。
1.3. Heterogeneous Information Fusion
一般地,语言模型和知识图谱的训练是两个不同的过程,他们被孤立在两个不同的向量空间,如何建立一个桥梁将他们联系在一起是一个挑战。
1.4. ERNIE
ERNIE(Enhanced Language RepresentatioN with Informative Entities) 是论文提出的模型名称,ERNIE也是芝麻街中的一份子,如下图所示。为了和芝麻街的其他人物(Bert,Elmo)做“兄弟”,该论文的模型简称使用了一些微妙的sample。

2. 背景和相关工作
预训练模型可以分为两大类:基于特征的方法和微调的方法
2.1. 基于特征的方法
基于特征的方法最经典的便是word2vec方法了,基于特征的方法旨在利用提取特征的技术将自然语言中的字或词进行分布式表达。通常,这些表达的结果会被放在模型输入层作为字词向量的初始化使用。然而,当这些语言模型训练结束,字词向量便固定,这将无法解决自然语言处理任务中普遍存在的一词多义问题。ELMo基于文本周围词语生成中心词的向量表达在一定程度上解决了一次多义问题,提升了模型的语言表达能力。
2.2. 微调的方法
基于特征的方法只使用字词向量表达作为输入层,流入模型中。微调的方法将训练的模型结构和参数一并接入下游任务,并会在下游任务的训练过程进行微调。这种方法最开始是由Dai and Le (2015)训练了一个自编码器,然后将这个自编码器与下游任务进行结合。之后,围绕这一方法诞生了大量的文献,比较经典的如BERT,ULMFiT,GPT均获得了不错的效果。
2.3. 不足
上述方法尽管在一些自然语言处理任务中获得了不错的提升,但是他们在训练的过程中都没有使用知识图谱中的知识。比如1.1中的举例,如果模型事先知道Blowin’ in the Wind和Chronicles: Volume One是音乐和书,那么会很轻松的推测出Bob Dylan是songwriter和writer,事实上,知识图谱便可以提供这个信息。此外最近的一些研究也表明了将知识图谱中的知识融入到预训练模型中,能有效的提升预训练模型的效果。
3. 模型结构
如下图所示,ERNIE可以分为两个encoder(T-Encoder和K-Encoder)。其中浅层的T-Encoder是用来提取句子的词法和句法特征信息即文本信息,K-Encoder是将知识图谱中的知识信息融合到T-Encoder提取的文本信息中,这样便可以将文本特征和实体特征投影到同一个特征空间。图中{w_1,w_2,...,w_n} 表示输入的文本,n表示这篇文本的长度。{e_1,e_2,...,e_m}表示输入文本中出现的实体序列,m表示这篇文本包含的实体数,通常m<n。如果文本中出现的单词w在知识图谱中有对应的实体e,他们之间的对齐被定义为f(w) = e。接下来,详细描述ERNIE的数据流过程。
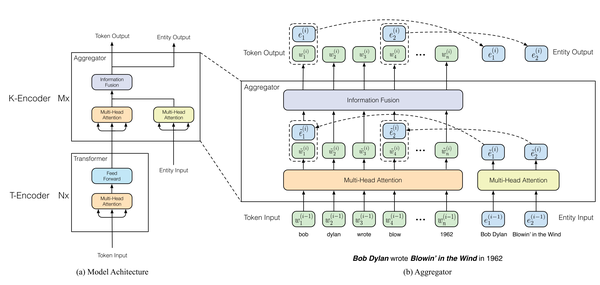
3.1. T-Encoder
给定一篇文本{w_1,w_2,...,w_n},和BERT类似,T-Encoder基于Transformer中的多头自注意力机制进行文本的语义特征提取,生成每个单词的向量表达{\bm{w_1},\bm{w_2},...,\bm{w_n}} ,可用下式进行表达。这里不再赘述,详情可以查看BERT的实现方式。接下来重点探讨K-Encoder的细节。
3.2. K-Encoder
K-Encoder是ERNIE提出的用来将知识图谱中的特征融合到语言模型中的一种结构,它由多层聚合器(aggregator)组成。首先T-Encoder已经对输入的文本进行了语义特征的提取,得到每个单词的向量表达,这些向量{\bm{w_1},\bm{w_2},...,\bm{w_n}}会作为K-Encoder的第一个输入。其次,在这些单词中假定有m个实体在知识图谱中,ERNIE使用这些实体经过的TransE训练得到的实体特征{\bm{e_1},\bm{e_2},...,\bm{e_m}}作为第二个输入。如下图所示。
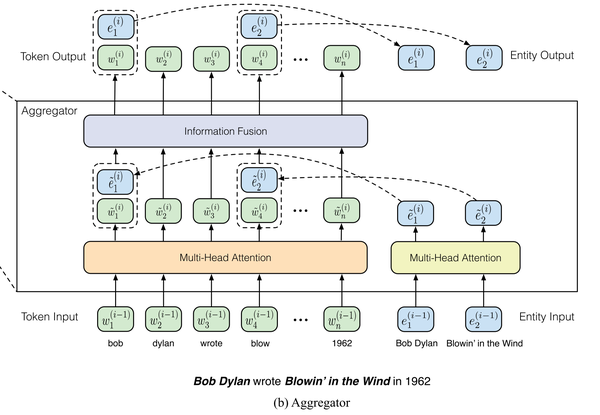
紧接着,两个输入分别使用各自的多头自注意力机制提取特征,下面公式右上角角标i表示第i层K-Encoder。
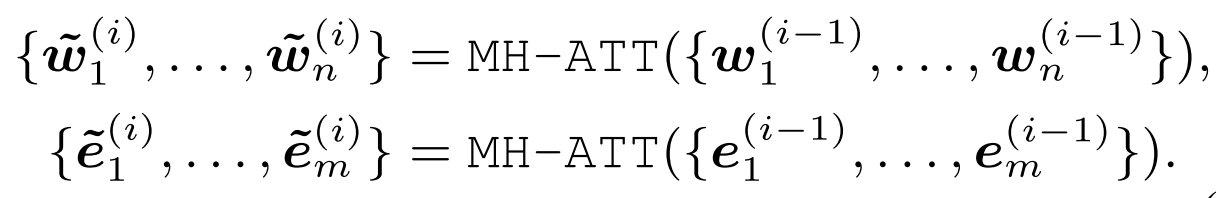
然后,ERNIE利用一个信息融合层,得到单词和实体的在下一层的向量表达,假设单词w_j对应的实体是e_k即e_k = f(w_j),信息融合的过程可以表示如下,得到单词和实体对应的向量表达,其中\sigma是一种激活函数,论文中使用了GELU函数作为激活函数:
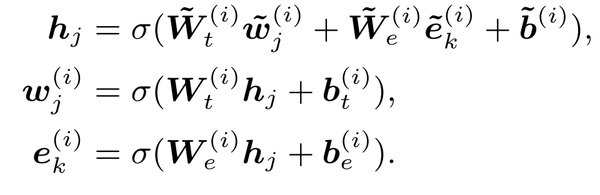
如果单词w_j在知识图谱中没有对应的实体,可用下式进行计算向量表达:
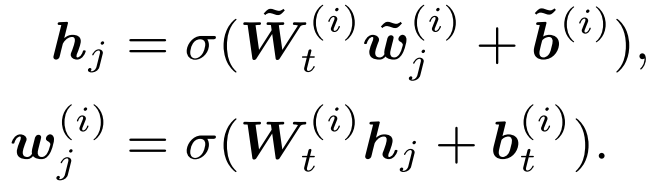
最后一层融合器的输出被当作是K-Encoder的输出。
4. 模型效果
4.1. 预训练过程
ERNIE的训练过程是一个多任务的训练过程,其中包括有三个任务,因此损失函数也是由三部分组成。他们分别是dEA,MLM和NSP损失。
其中MLM(masked language model)和NSP(next sentence prediction)损失函数和BERT一致,这里不再赘述。这里需要讲的是dEA损失函数。dEA(denoising entity auto-encoder)是一个过程,这个过程是用来预测文本中出现的单词在知识图谱中对应的实体。考虑到知识图谱中存在大量的实体,这将会导致预测的效率低下,论文只使用对应文本出现的实体集合{e_1,e_2,...,e_m}作为待预测的候选集。因此,单词w_i对应在知识图谱中的实体是e_j的概率可以计算如下:
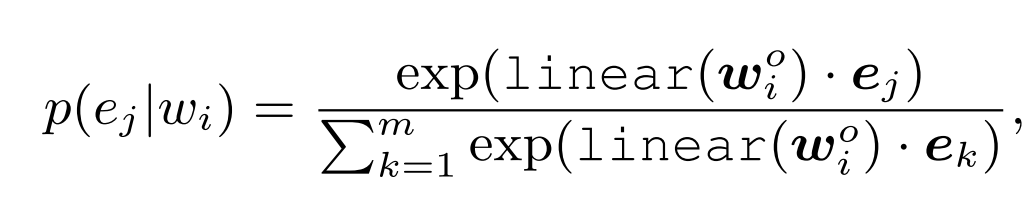
其中linear(.)表示线性层,上式最后会被用在交叉熵损失函数中训练。
考虑到单词对应到实体的过程具有一定的错误率,论文在计算损失函数dEA时使用了如下过程:(1)给定一个单词到实体的对应关系,5%的概率将实体进行随机更换成另外一个实体,通过这种方式可以让模型学习到如何对实体进行纠错。(2)以15%的概率隐藏单词到实体的对应关系,通过这种方式可以让模型知道训练并不需要所有的实体对齐关系。(3)剩下80%的概率保持单词到实体的关系。
4.2. 微调过程
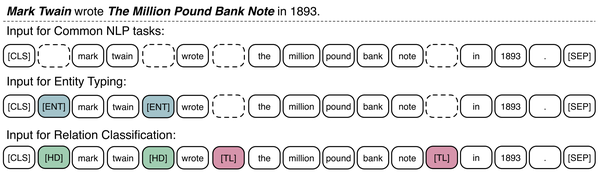
如下图所示,ERNIE在普通自然语言处理任务(比如文本分类,命名实体识别)的微调过程和BERT类似。针对知识驱动的实体分类任务和关系分类任务,ERNIE在实体的前后侧增加了一些特殊字符。其中关系分类任务头部实体的前后侧增加字符[HD],尾实体增加字符[TL],这在普通的关系分类模型中相当于是位置信息的融合,模型最后还是使用句子头部的[CLS]字符进行关系分类。实体分类任务是关系分类任务的一个简化版本。
4.3. 实体分类任务
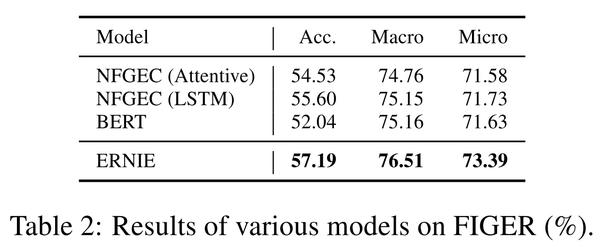
论文使用了两个数据集进行了验证FIGER和Open Entity。这两个数据集的情况如下:

论文使用了NFGEC模型,UFET模型以及BERT模型作为对照,分别在两个数据集的实验结果如下:
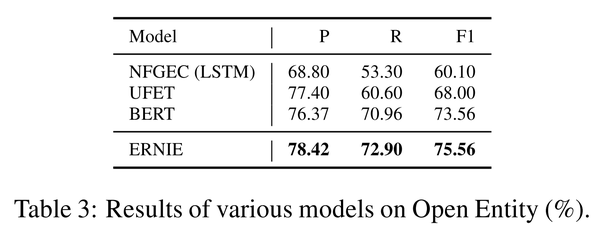
4.4. 关系分类任务
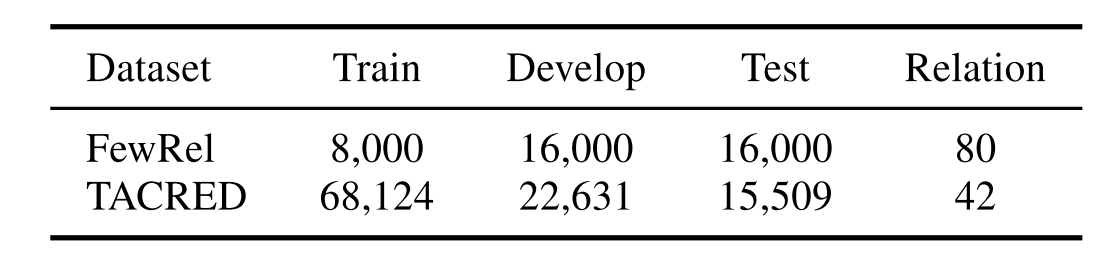
关系分类任务旨在预测两个实体之间的关系,论文也使用了两个数据集(FewRel和TACRED)来评价模型的性能,下面是这两个数据集的情况:
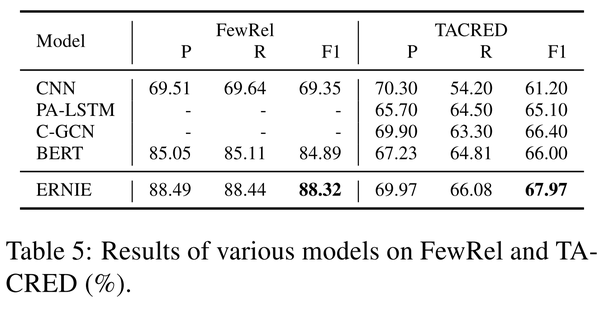
论文使用了CNN,PA-LSTM,C-GCN和BERT作为对照,实验结果如下:
- [1] Zhang Z, Han X, Liu Z, et al. ERNIE: Enhanced language representation with informative entities[J]. arXiv preprint arXiv:1905.07129, 2019.
- [2] Tomas Mikolov, Ilya Sutskever, Kai Chen, Greg S Corrado, and Jeff Dean. 2013. Distributed representations of words and phrases and their compositionality. In Proceedings of NIPS, pages 3111–3119.
- [3] Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In Pro- ceedings ofNAACL-HLT, pages 2227–2237.
- [4] Andrew M Dai and Quoc V Le. 2015. Semi-supervised sequence learning. In Proceedings of NIPS, pages 3079– 3087.
- [5] Todor Mihaylov and Anette Frank. 2018. Knowledgeable reader: Enhancing cloze-style reading comprehension with external commonsense knowledge. In Proceedings ofACL, pages 821–832.
- [6] Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Ja- son Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. In Pro- ceedings ofNIPS, pages 2787–2795.