2020年度自监督学习论文整理

2020年, Google 大脑、Facebook AI团队 (FAIR)以及DeepMind AI团队相继发表了contrastive learning框架。本文整理了2020年以来,对比学习(contrastive learning )的重要里程碑和大佬们的研究路线,方便大家掌握发展路径和现状。
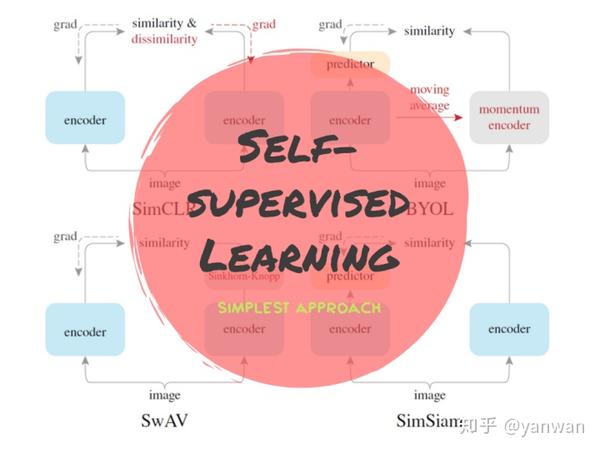

在开始之前,先介绍self-supervised learning (自监督学习) 与contrastive learning (对比学习) 这两个热点名词。
Self-Supervised Learning
Self-Supervised Learning(SSl) 其实算是近几年的热点名词,定义上回顾一下:
- unsupervised:是使用没有标注的数据训练模型
- supervised:是使用了有标注的数据训练模型
- semi-supervised :是同时使用了有标注与没有标注的数据训练模型。
而self-supervised翻成中文大概是自监督学习,也就是没有标注资料也会自己会学习的方法。属于unsupervised learning。
Contrastive Learning
Contrastive learning是self-supervised learning中非常naive的想法之一。像小孩子学习一样,透过比较猫狗的同类之间相同之处与异类之间不同之处,在即使式在不知道什么是猫、什么是狗的情况下 (甚至没有语言定义的情况),也可以学会分辨猫狗。
RoadMap of SSL
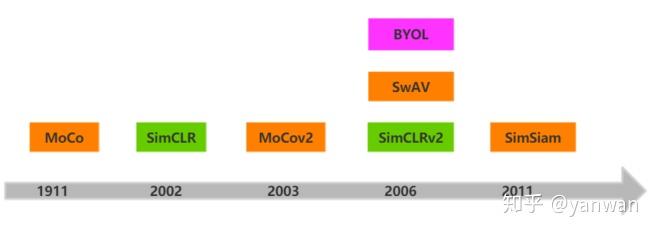

如上图,从MoCo到SimSiam,这些论文都来自三大组:
- Facebook AI Research (FAIR) :MoCo v1&v2, SwAV,Simsiam
- Google Research, Brain Team:SimCLR v1 & v2
- DeepMind Research:BYOL
(1)Facebook AI Research (FAIR) :MoCo v1&v2, SwAV,Simsiam
MoCo - Momentum Contrast for Unsupervised Visual Representation Learning
CVPR 2020
链接:https://arxiv.org/pdf/1911.05722.pdf
MoCo (momentum contrast) 的想法是维持两个encoder,一个使用gradient decent训练,另一个的参数则是跟著第一个encode的参数,但是使用momentum更新,保持一个相似但不同的状态。而这个momentum encoder的输出会被一个queue储存起来,取代原本的memory bank。相比原本的memory bank作法,MoCo的储存的representation比较新,保持一致性的同时也藉由momentum encoder确保了足够的对比性。
最终在ImageNet的实验结果达到当时的SOTA。
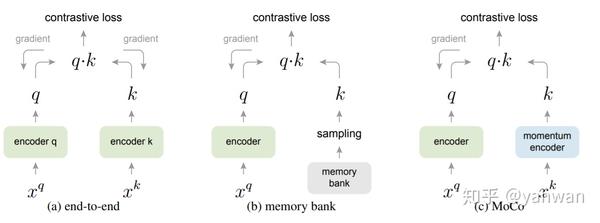

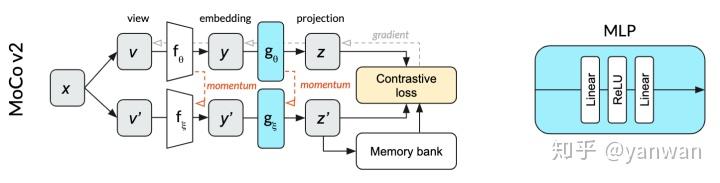
MoCo v2 - Improved Baselines with Momentum Contrastive Learning
链接:https://arxiv.org/pdf/2003.04297.pdf
MoCo v2 只是将SimCLR的两个组件 (stronger data augmentation与投影网络 )加入MoCo的架构。相对于SimCLR,多了momentum encoder与memory bank,且不需要特别大的batch。
具体的,如下图,图中的顶行和底行表示相同的网络(由θ参数化),MoCo将单个网络拆分为θ参数化的在线网络(顶行)和ξ参数化的动量网络(下排)。在线网络采用随机梯度下降法进行更新,动量网络则基于在线网络权值的指数移动平均值进行更新。动量网络允许MoCo有效地利用过去预测的记忆库作为对比损失的反面例子。这个内存库使批处理的规模小得多。在我们的狗图像插图中,正面的例子是相同图像的狗的作物。反面例子是在过去的小批量中使用的完全不同的图像,它们的投影存储在内存库中。

SwAV - Unsupervised Learning of Visual Features by Contrasting Cluster Assignments
NIPS 2020
链接:https://arxiv.org/pdf/2006.09882.pdf
对比学习需要很多负例进行比较,既耗时又耗内存,于是FAIR联合Inria也推出了SwAV,提出了一个新的想法:对各类样本进行聚类,然后去区分每类的类簇。模型结构如下:
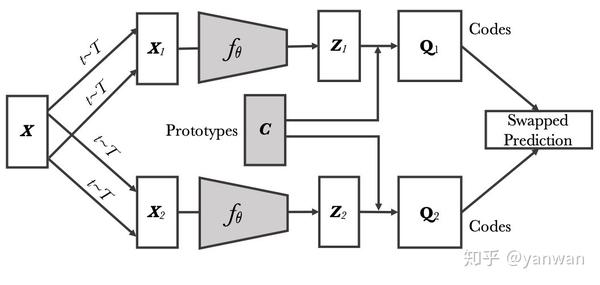

SimSiam - Exploring Simple Siamese Representation Learning
链接:https://arxiv.org/pdf/2011.10566.pdf
代码:https://github.com/PatrickHua/SimSiam
SimSiam简单用一句话描述就是没有momentum encoder的BYOL。BYOL拿掉了MoCo的memory bank,SimSiam进一步地拿掉了momentum encoder。方法简单,实务上同样能避免collapsing output的发生。
SimSiam的架构与BYOL一样是三个阶段的架构,先过主网络embedding,再过小网络projection,最后过小网络prediction。与BYOL不同之处在于SimSiam并没有两组网络参数,同一个网络对于不同的view交互地用latent projection互为彼此的prediction target。在更新参数时,都只计算prediction那条路线的gradient,也自然没有什么momentum encoder。
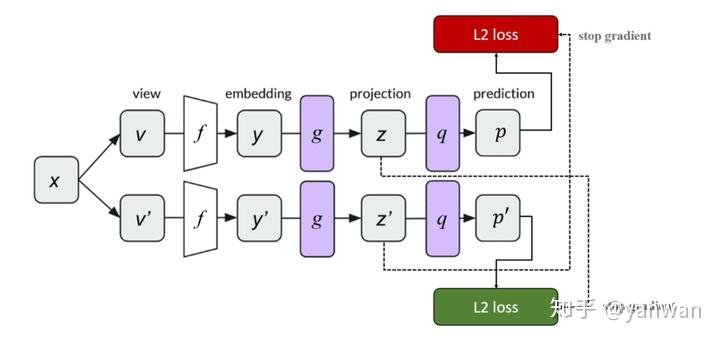

在实验结果上,SimSiam并不是最强的,但是是所有方法中最简单、最好实现的。
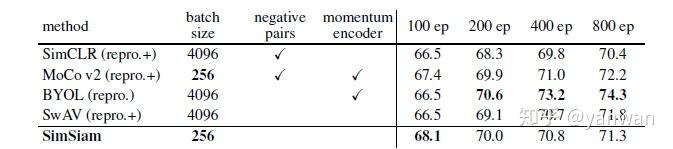

(2)Google Research, Brain Team:SimCLR v1 & v2
SimCLR - A Simple Framework for Contrastive Learning of Visual Representations
ICML 2020
链接:https://arxiv.org/pdf/2002.05709.pdf
SimCLR是self-supervised learning与contrastive learning中重要的一个相当重要的里程碑,其最大的特点在于研究各种数据增强 (data augmentation) 作为SSL的归纳偏置 (inductive bias),并利用不同data间彼此的互斥强化学习目标,避免contrastive learning的output collapse。
整体运作概念分为三个阶段:
- 先sample一些图片(batch of image)
- 对batch里的image做两种不同的data augmentation
- 希望同一张影像、不同augmentation的结果相近,并互斥其他结果。
如果要将SimCLR的架构划分阶段,大致可以分成两个阶段,首先是大个embedding网络执行特征抽取得到y,接下来使用一个小的网络投影到某个固定为度的空间得到z。
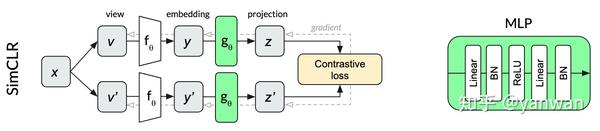

这个小网络投影也是SimCLR的另一个特点。对于同一个x,用data augmentation得到不同的v,通过网络抽取、投影得到固定维度的特征,计算z的contrastive loss,直接用gradient decent同时训练两个阶段的网络。
SimCLR直接比MoCo高出了7个点,并直逼监督模型的结果。
SimCLR v2 - Big Self-Supervised Models are Strong Semi-Supervised Learners
NIPS 2020
链接:Big Self-Supervised Models are Strong Semi-Supervised Learners
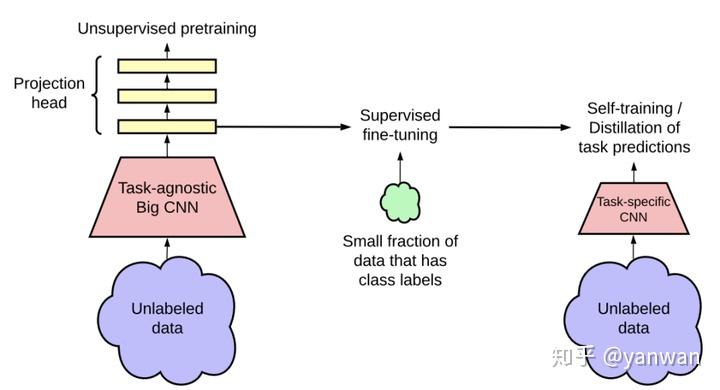
SimCLRv2使用了一种独特的方法,包括使用的无监督预训练、有监督的微调和未标记数据的蒸馏,使其成为计算机视觉中半监督学习的一个令人惊讶的强大基准,远远领先于最新技术。

(3)DeepMind Research:BYOL
BYOL - Bootstrap your own latent: A new approach to self-supervised Learning
链接:https://arxiv.org/pdf/2006.07733.pdf
BYOL建立在MoCo动量网络概念的基础上,添加了一个MLP来从 z 预测 p ,而不是使用对比损失,BYOL使用归一化预测 p 和目标z’之间的L2 loss。继续使用我们的dog image示例,BYOL尝试将dog图像的两个裁剪转换为相同的表示向量(使 p 和 z’相等)。因为这个损失函数不需要负示例,所以在BYOL中没有内存库的用处。
在BYOL中的两个MLP仅第一个线性层之后使用批处理标准化。


Self-supervised learning在2020年获得很大的进展,而且许多优质论文都是来自强大的公司的研究团队,可以预想到这是一个学界与业界都热烈渴求的方向。不过时至今日,SSL在工业上的应用应该还是相对较少。
最后,老话一句,请大家扫码关注公众号:AI约读社,也欢迎加入学术交流群,期待与大家沟通。
