
ICIP2018 | 图像鉴黄做得好,健康上网少烦恼

机器之心发布,作者:Xizi Wang, Feng Cheng, Shilin Wang*, Huanrong Sun, Gongshen Liu, ChengZhou,来源:上海交大 - 上海嵩恒内容分析技术联合实验室。
在纷繁复杂的网络世界中,敏感信息识别与处理起着极为重要的作用。而近日研究者在 ICIP 2018 提出 LocoaNet,该网络结合了局部敏感区域检测网络与全局分类网络,并采用了多任务学习策略以提取敏感图片高鉴别力的特征,该网络在 NPD 和 AIC 等数据集取得了很高的分类准确率。
引言
根据中国互联网络信息中心发布第 42 次《中国互联网络发展状况统计报告》,截至 2018 年 6 月底,中国网民数量已达 8.02 亿!平均每周上网 27.7 小时,出去每周睡眠时间(以 8 小时 / 天为例),现代人每天有近 1/4 的时间在拥抱网络。
随着科技的发展进步,互联网也成为人们日常生活和工作中离不开的工具,它在给人们带来生活方便、处理事务高效的同时,也会成为一些不法分子的有利工具,利用其传播和散延一些不良信息,如黄色图片、影视等,涉黄案件接踵而来,由此一来,「打黄」也显得尤为重要。
不同于文字鉴黄,图像鉴黄目前仍大量依赖人类鉴黄师,一方面存在审核标准的主观误差,另一方面也不利于鉴黄师这一职业人员的长期心理健康。随着人工智能浪潮的涌动,机器鉴黄领域也在不断呈现出令人耳目一新的硕果。由嵩恒网络与上海交通大学联合首创 local-context aware network(基于局部上下文感知的深度神经网络)就带来了一种新的解决方案。
现有解决方案
目前,现有的敏感图像的鉴别技术方案主要分为两种。第一种是基于卷积神经网络 CNN(Convolution Neural Network)的敏感图像分类方法 [1]。作者直接将图像的像素信息分别输入到 AlexNet[2] 与 GoogLeNet[3] 中,基本保留了输入图像的所有信息,通过卷积、池化等操作对特征进行提取和高层抽象,并将两种网络输出图像识别的概率值加权求和来分类。CNN 作为一种端到端的学习方法,应用非常广泛。第二种是 CNN 全局图像分类与局部图像目标检测 Faster RCNN 相结合的敏感图像分类方法 [4]。在给定的图片中,Faster RCNN 可以精确地找到物体所在的位置,并标注物体的类别,即进行图像的识别与定位。作者将局部目标检测和全局特征相结合,进一步提升了敏感图像检测的正确率。
我们提出的解决方案
目前现有的技术无法解决图像中存在敏感区域大小各异情况下的分类问题。而且针对图像的分类没有把各个语境下的特征整合起来进行分类,需要分段训练各个语境的网络再拼接起来,训练过程繁琐。在局部敏感区域网络中还需要大量人力进行图像标注。
本文提供了一种对敏感图片进行鉴定的方法及其终端,该终端将敏感图片分为三个等级:色情、性感、正常;该终端主要由一个 ResNet(残差神经网络)和一个基于特征金字塔的多目标检测网络组合成的系统——LocoaNet,其完整结构如图 1 所示,
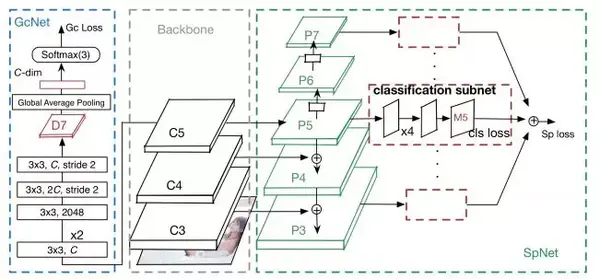

LocoaNet 分为三个部分,ResNet 作为骨干网络(Backbone),敏感身体区域检测网络 (SpNet) 以及全局分类网络 (GcNet)。选择 ResNet 作为骨干网络主要是由于它分类准确率高且计算速度快。其他一些诸如 VGG16,ResNet101 网络也可以作为骨干网络。
传统的全局分类网络应用在敏感图片识别任务的主要缺陷在于全局分类网络比较看重整体图像,易于在分类时过多的考虑背景图像。而对于一些有高鉴别力的局部区域(比如裸体,身体敏感区域)不太关注。而这些区域往往对敏感图像分类起决定性作用。因此,我们设计了敏感身体区域检测网络(SpNet)来使特征提取网络更加关注敏感身体区域,学习了具有强语义信息的多尺度特征表示。
SpNet 的设计使用了特征金字塔网络(FPN)[6] 与 RetinaNet[7]。在骨干网络 ResNet 生成的每一个不同分辨率的残差层 feature map 中引入了后一分辨率缩放两倍的 feature map 并做基于元素的相加操作。从而生成新的 feature map。通过这样的连接操作使生成的 feature map 都融合了不同分辨率、不同语义强度的特征,在不增加额外的计算量的情况下保证了每一层都有合适的分辨率以及强语义特征,提升物体检测的精度。在的 feature map 上进行核为,步长为的卷积而成。在上进行同样的卷积操作生成。之间加入了 ReLU 操作层。
对 P3 至 P7 的每一层 feature map,进行四层核为 3*3,filter 数量为 256 的卷积以及一层 ReLU 操作提取 feature map Mi, i∈[3,7]。Mi 上的每一个点为对应九个不同大小的 Anchor(锚点),与输入图像上的一个以该点为中心的九种尺寸的区域对应。SpNet 的主要目标为对每一个 Anchor 进行多目标检测,检测是否出现敏感身体部位。在此,所谓多目标检测中检测的是敏感图片中人体的一些关键部位,分为胸部(色情)、女性性器官(色情)、男性性器官(色情)、臀部(色情)、阴毛(色情)、胸部(性感)、臀部(性感)、背部(性感)、腿(性感)和上半身(性感)等十个特征部位。对 Mi 进行核为 3*3,filter 数量为 KA(K 为待检测的目标数量,A 为每个 Anchor 对应的尺寸数量,K=10, A=9)的卷积并进行 Sigmoid 操作,得到的 feature map 即为每个 Anchor 包含各个目标的概率。SpNet 可以对 C3 到 C5 特征提取层的参数进行调整,使分类网络 LocoaNet 更关注敏感区域,学习到更高鉴别力的特征。
GcNet 网络起到全局分类的作用,将图片分为正常、性感、色情三个类别中。GcNet 将骨干网络的最后一层 feature map 作为输入,通过五层卷积层生成 feature map。每层卷积后都应用 ReLU 操作进行线性整流。对进行全局均值池化后连接到一个输出为三单元的全连接层,对图像进行三分类。
由于包含分类网络和目标检测网络两种网络,LocoaNet 的训练采用多任务学习的方法。LocoaNet 的损失函数为 SpNet 损失函数和 GcNet 损失函数之和。SpNet 的损失函数使用了 focal loss[7],GcNet 的损失函数为交叉熵代价函数 (cross-entropy loss)。骨干网络采用了在 ImageNet 的预训练模型上进行 finetune。在实际使用过程中,不运算 SpNet 网络部分,仅计算 GcNet 部分进行图像分类,减少了计算复杂度。
除此之外,我们还使用了递进学习的策略使得 LocoaNet 能够快速的移植到其他数据集上进行训练,达到迁移学习的目的。目标检测网络的训练前期需要大量的样本目标框标注,消耗大量的人力。递进学习方法的引入可以让我们的模型在无样本框标注的数据集上进行训练。递进学习方法的过程如下:
- 步骤一: 在有敏感区域标注的数据集上训练 LocoaNet,同时更新骨干网络,SpNet 和 GcNet 的参数
- 步骤二: 在仅有类别标注的数据集上训练,固定 SpNet 的参数,仅更新骨干网络和 GcNet 的参数,最小化分类损失。
- 步骤三: 在上训练,固定 GcNet 参数,仅更新骨干网络和 SpNet 的参数,最小化目标检测损失。
- 重复步骤二和步骤三直到网络收敛。
在本文中,我们设计了 LocoaNet,把局部敏感区域检测网络与全局分类网络相结合,采用了多任务学习策略,对敏感图片提取高鉴别力的特征,达到了很高的分类准确率。同时提出了递进学习策略提升网络对其他数据集的泛化能力。不仅如此,计算复杂度相比于现有设计更小。本发明在公开数据集 NPDI[8] 上达到了 92.2% 的三分类准确率,在 AIC(包含有类别标注的 150000 张图像和有敏感区域标注的 14000 张色情图像)上达到了 95.8% 的三分类准确率。
论文:Adult Image Classification by a Local-Context Aware Networ。


论文地址:https://ieeexplore.ieee.org/document/8451366
摘要:在打造一个健康有序的网络环境的过程中,「鉴黄」已经成为一个重要命题。近年来,基于深度学习基础提出的解决方案已经帮助该领域取得了一定的突破,当在识别精准度等方面还有待进一步提升。本发明专利结合深度学习,建立了鉴定敏感图片的模型及其终端,一方面,为类似于鉴黄师等职位的人提高工作效率,另外一方面,通过自动化的手段在第一时间有效的制止了敏感图片在有些网站的流传。
参考文献:
[1] Moustafa, Mohamed. "Applying deep learning to classify pornographic images and videos." arXiv preprint arXiv:1511.08899 (2015).
[2] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. "Imagenet classification with deep convolutional neural networks." Advances in neural information processing systems. 2012.
[3] Szegedy, Christian, et al. "Going deeper with convolutions." Cvpr, 2015.
[4] Ren, Shaoqing, et al. "Faster r-cnn: Towards real-time object detection with region proposal networks." Advances in neural information processing systems. 2015.
[5] Ou, Xinyu, et al. "Adult Image and Video Recognition by a Deep Multicontext Network and Fine-to-Coarse Strategy." ACM Transactions on Intelligent Systems and Technology (TIST) 8.5 (2017): 68.
[6] Lin, Tsung-Yi, et al. "Feature pyramid networks for object detection." CVPR. Vol. 1. No. 2. 2017.
[7] Lin, Tsung-Yi, et al. "Focal loss for dense object detection." arXiv preprint arXiv:1708.02002 (2017).
[8] Sandra Avila, Nicolas Thome, Matthieu Cord, Eduardo Valle, Arnaldo de A. Araújo. Pooling in Image Representation: the Visual Codeword Point of View. Computer Vision and Image Understanding (CVIU), volume 117, issue 5, p. 453-465, 2013.
