
行人重识别算法SCPNet论文解读与代码开源

前言:这是我室友 @范星.xfanplus 和我去年在ACCV2018上发表的一篇论文,论文和代码都已经放出。在ACCV会议上我替室友做了论文展示,然后我再替他来对这个论文写一篇详解。论文原版结果是用旷视内部框架实现的,最近用pytorch重新复现并开源,结果和论文中的基本一致。
- Xing Fan, Hao Luo, Xuan Zhang, et al. SCPNet: Spatial-Channel Parallelism Network for Joint Holistic and Partial Person Re-Identification[C]//Asian Conference on Computer Vision. Springer, Cham, 2018. [pdf]
- Github code:xfanplus/Open-SCPNet
1、摘要翻译
全身行人重识别已经在过去几年取得了很好的进展。但是在一些场景中,行人通常会被其他目标所遮挡,这种遮挡场景下的行人重识别被称为局部行人重识别,简称partial ReID。本文我们提出了spatial-channel parallelism network (SCPNet)。SCPNet中每组channel的特征提供了行人身体某一块空间区域的ReID特征,并利用空间-通道相关性来监督网络学习一个鲁棒的特征。这个特征在全身行人重识别和遮挡行人重识别两个任务上均达到了state-of-the-art的性能。
2、背景介绍
行人重识别是智慧零售、智能安防领域里面比较重要的一个研究课题,因此在学术界上也比较受到关注。经过短短几年时间的发展,在学术数据集上大家已经刷到了一个比较好的性能,当然这也得益于早期水平local feature代表方法PCB、AlignedReID等论文的推动。


PCB [1]相信大家已经比较熟悉了,PCB最重要的贡献就是发现,对图像的每个水平local feature进行loss监督训练可以提高特征的性能。而SCPNet论文的实验现象给了我一些启示,后面会给出我的一些解释,为什么监督local feature能够提高网络的性能。此外,从直观上感觉,遮挡区域主要会影响遮挡区域的local feature,剩下区域的local feature应该还是不错的。而global pooling会导致遮挡区域影响整个global feature。因此local feature可能是解决遮挡的一个思路。

AlignedReID [2]是我们的另外一篇工作,我个人认为AlignedReID里面有个很不错的思路是利用local feature来监督global feature,然后在使用的时候只用global feature,达到提速的效果。而SCPNet同样传承了AlignedReID的这个思路。
当然这些方法基本都是在Market1501和DukeMTMC这些数据集下完成的,这些数据集都是经过数据清洗的,总体来说行人图像比较完整。但是在真正实用场景下,遮挡一直是若干个痛点中的一个很大的痛点。如下图,partial-ILIDS是机场场景下拍摄的图片,行人被行李箱遮挡是非常频繁的。而遮挡场景下,行人的表观特征会被遮挡物污染,造成特征产生变化,从而使得识别错误。


ICCV2015郑伟诗老师课题组曾经用传统方法做过partial ReID的工作,后来沉寂了很久,CVPR2018何凌霄师兄的DSR工作把partial ReID重新拉了回来。虽然最近出现了少量partial ReID的工作,但是有大部分都是专门针对于partial ReID的,并没有对person ReID(备注:下文person ReID就默认指全身ReID,而ReID指person ReID和partial ReID)有任何促进,甚至不能应用于person ReID。而从实用的角度来讲,我们当然希望一个方法既能提高person ReID的性能,又能提高partial ReID的性能。而这就是SCPNet的设计的初衷。
综上,SCPNet产生的motivation有如下几点:
- PCB显示对每个local feature监督能够提高ReID的性能,(并且在直观上我们认为local feature有助于遮挡条件下partial ReID);
- AlignedReID显示了用local feature监督global feature是可行的,我们希望继续传承这一思路;
- 从实用的角度考虑,我们希望设计一个网络,既能提高person ReID的性能,又能提高partial ReID的性能。
3、SCPNet


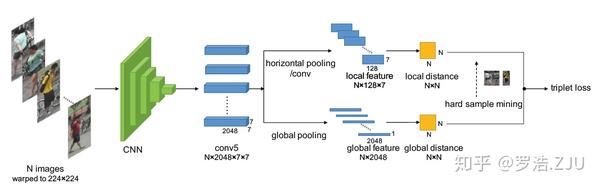
上图是SCPNet的结构图,总体来说是比较简单的,backbone用的是大家都用的Resnet50。和AlignedReID一样,SCPNet总共有两个分支,一个是local分支,一个是global分支。local分支也是比较传统的水平pooling得到local features。而global分支做了一点点的轻微改变,就是用一个1×1的conv层将feature map的通道维度从C维提升到4C维。
接下来是SCPNet的核心了,对于local分支,我们通过水平pooling可以得到四个局部特征,就是上图右上角的蓝、红、黄、绿的四个特征向量,也就是按照spatial分块得到的特征。另外,对于global分支,我们通过升维可以得到一个 H\times W \times 4C 的feature map,经过pooling之后得到4C维的全局特征, 然后我们按照channel进行分组,同样分为四组,也能得到4个global features,就是上图右下的蓝、红、黄、绿的四个特征向量,这是按照channel分组得到的特征。
传承AlignedReID的思想,我们设计了SCP loss将local分支的spatial信息传递给global分支,这一点后面再详细介绍。因为我们已经将local features的信息传递global features了,传承PCB的结论,我们对每个global特征进行ReID loss的监督。根据目前主流的作为,每个global feature都计算ID loss和triplet loss。
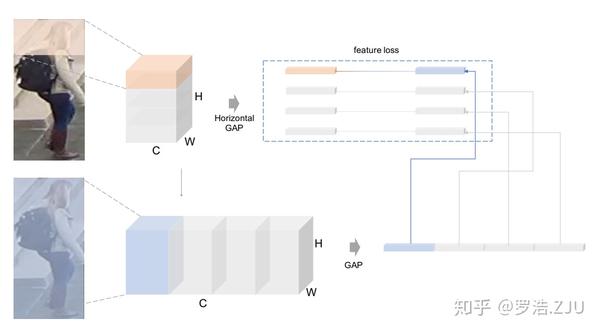

接下来就是SCP loss了。SCP loss的功能是将局部信息传递给global分支,现在我们有四个local features,还有四个global features,那么自然而然就会想到用local features去监督global features,最后SCP loss写作:
L_{S C P}=\sum_{r=1}^{R}\left\|f_{s, r}-f_{c, r}\right\|_{2}^{2} \\
其中 f_{s,r} 是第 r 块local feature,而 f_{c,r} 是第 r 块global feature。通过最小化SCP loss,SCPNet就是将图片的空间特征传递给global特征的channel维度,每一组channel都包含了一块区域的局部特征。最终SCPNet的总损失就是ReID loss和SCP loss的加权和:
L=L_{c l a s s}+L_{m e t r i c}+\lambda L_{S C P} \\
其中 L_{c l a s s} 是四个ID loss之和, L_{m e t r i c} 是四个triplet loss之和,而 \lambda 是平衡ReID loss和SCP loss的权重参数。特别指出,local feature并没有任何梯度传入,这是为了保持local feature完整的空间信息,虽然SCP loss是一个L2损失,但是在训练过程中f_{s,r} 是被固定住的。而ReID loss监督local feature的任务我们交给global feature。这就是SCPNet的整个网络结构。
最终在测试阶段,SCPNet使用的是4C维度的global feature,这个global feature已经包含了空间信息。当然用1×1对feature map进行降维,然后在水平池化得到4个C/4维度的local features也是没问题,实验结果基本差不多。
4、实验结果
论文使用了4个person ReID的数据集Market1501、DukeMTMC-reID、CUHK03、CUHK-SYSU 和两个partial ReID的数据集Partial-REID和Partial-iLIDS。其中两个partial ReID仅仅作为测试,因为数据集太小了。训练细节就不赘述,可以去论文里面找。
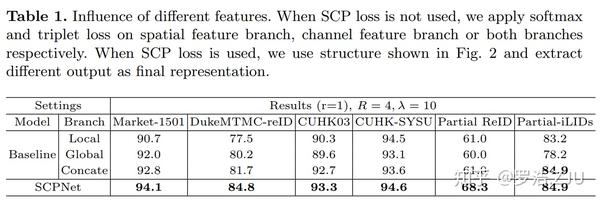

第一个Ablation study是验证SCP loss的作用。首先,我们把SCP loss去掉来训练一个baseline,也就是 \lambda=0 的条件下训练一个网络。由于是对比实验,所以表1中的结果是在四个person ReID数据集上训练,在六个数据集上分别测试的结果。多数据训练应该算是AlignedReID留下的后遗症,好在是对比实验review也没有特别深究,不过也因为这个原因被怼了,强烈不推荐这样。Local是指融合所有local features的结果,Global就是global分支4C维度特征的结果,Concate是指融合上面两个特征的结果,显然Concate结果是最高的。然后我们用 \lambda=10 来训练SCPNet,最终4C维度的global feature在六个数据集上都达到了更高的性能,这也得益于PCB的效果。
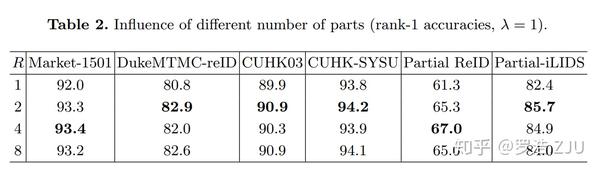



第二个Ablation study是验证分块数量 R 的影响,我们将图像分为1块、2块、4块和8块分别作了实验,在2块、4块上结果都是不错的。但是从可视化的角度来看,我们觉得4块更直观一点,因为可以分为头部、胸部、大腿和小腿四个区域。而2块的话基本就是上半身和下班身两块,上半身头部和胸部通常特征也是不一样的,在夏天大腿和小腿也经常特征是不一样的。所以综上我们选择4块。
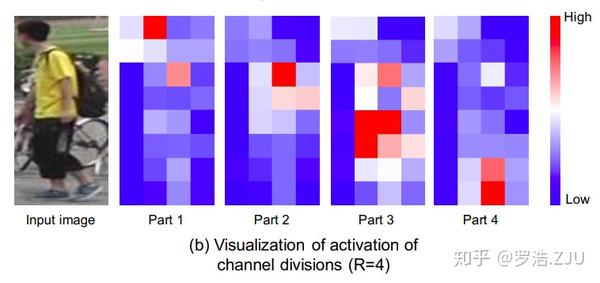

接下来我们可视化feature map的激活性,我们按照channel维度将feature map分为四块,然后用local feature进行监督,最后我们可视化了这四个feature map。结果发现,每个feature map都重点关注图像的某个空间区域,而这也验证了我们的想法,SCP loss将空间信息传递给了global feature的channel维度。
当然,这个图也让我猜测了一下PCB有效的原理:经过水平池化之后得到的局部特征,它们都会重点关注于图像中的某一块区域,但是由于网络很深,其实感受野是很大的,所以它们是能看见整张图像的,结果就是每个局部特征都重点关注于某个区域却又能看见整张图像,通过监督若干个这种既有专攻又有全局的特征,网络能够学习到更鲁棒的特征。
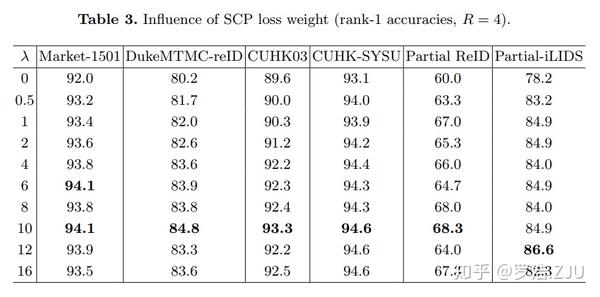

当然最后一个Ablation study就是权重 \lambda 的影响,最后发现 \lambda=10 时候的效果不错,最后也就用这个参数了。
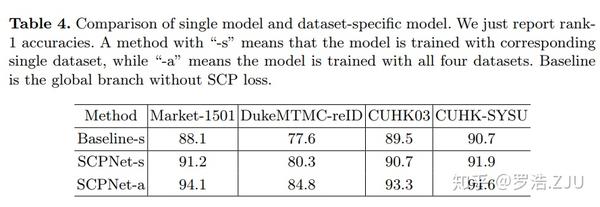

所有的Ablation study都是在多数据集训练完成的,自己和自己对比的对比实验review还能接受吧。但是和state-of-the-arts对比的时候就很不公平了。因此首先就是在单数据集训练单数据集测试的条件下重新训练网络。-s就是指single的意思,表示单数据集训单数据集测,而-a就是all的意思,表示多数据集训练单数据集测试。可以看出,在Market1501数据集上SCPNet能比baseline涨3.1个点。
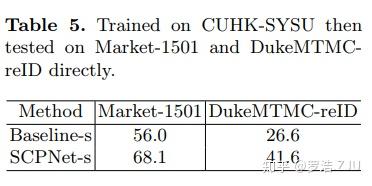
表5是cross-domain的实验,我们在CUHK-SYSU数据集分别训练了baseline和SCPNet,然后在Market1501和DukeMTMC-reID上做测试,最后结果涨了10多个点。这也就是说SCPNet并不是在训练集上过拟合,而是真正提高了网络的泛化能力。


图6用一个极端例子来解释为什么SCPNet同样能提高partial ReID的性能。图中上下两张照片的上半身和下半身被物体遮挡了。我们通过可视化feature map的激活性,发现上面图的part1和part2激活性很低,而part3和part4还行。而下面图part1和part2激活性还行,而part3和part4很低。也就是说SCPNet的global feature里面有一部channel的feature还是包含了不少特征信息的。而对于传统的global feature,只要有一个区域被遮挡了,整个特征基本都要被污染。并且SCPNet的global feature哪里被污染还是比较明确的,就是对应区域的channel部分。在遮挡情况下,SCPNet提供的特征有一部分能用,被污染的部分也比较明确,这使得对遮挡的处理能力更加鲁棒。
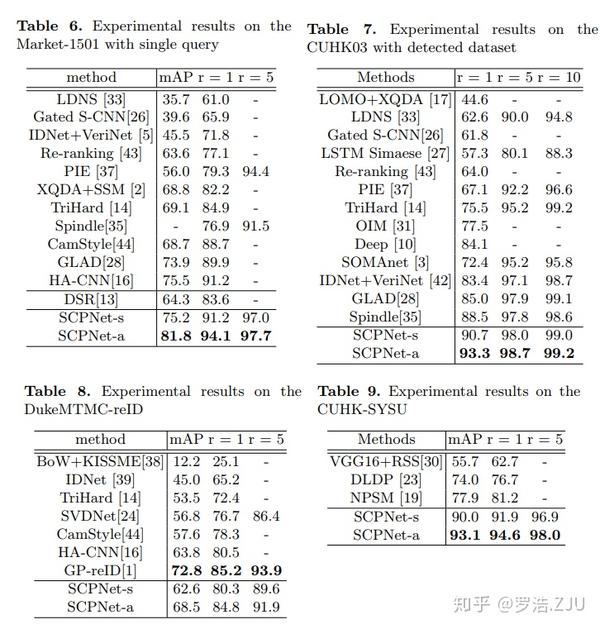

和person ReID的state-of-the-arts比较如上表,不过多赘述了,反正能跟上趟吧。
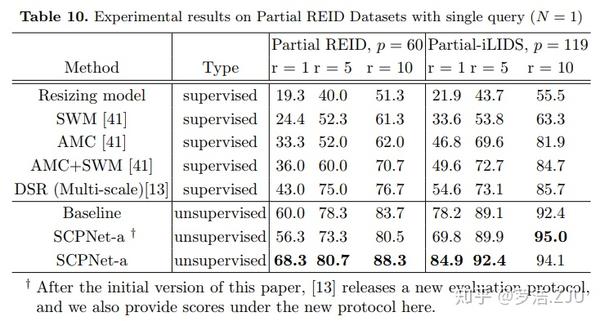

和person ReID的state-of-the-arts比较如上表,这里还是有些问题的。首先就是监督和非监督的问题,因为partial ReID数据集比较小,目前主流还是在Market1501上训,在partial ReID数据集数据集上测,所以理论上DSR应该也算是无监督的方法。另外一个问题就是partial ReID的评测脚本还没有特别统一,并且还存在一个评测的更新,所以大家是否在一个评价协议下评测的还不清楚。但是根据论文描述,我们这个结果大概率是可信的。可以看出比stoa还是高出了不少,当然很大原因还是因为做的人太少,准确率太低了。但是SCPNet能够提高partial ReID的性能,这个结论是不会错的。
5、代码解析
row_f1 = row_f1.detach()
row_f2 = row_f2.detach()
row_f3 = row_f3.detach()
row_f4 = row_f4.detach()代码特别拿出这一块,这代表了四个local features,为了实现local feature没有梯度传入的目的,需要使用pytorch的detach()函数。当然这是0.3版本的pytorch,0.4版本以上的好像这个API换掉了,貌似是_detach()还是什么,不是很确定。
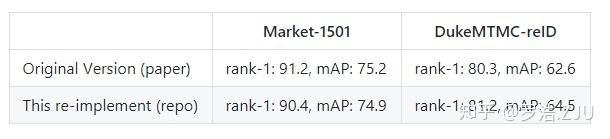

因为论文的结果是基于旷视内部框架实现的,为了开源计划,我们用pytorch重新复现了一下,结果基本能达到论文repo的结果。当然因为用了别人的baseline,所以有些细节可能不一样,作为大家repo的一个参考吧。
6、Contributions和Drawbacks:
最后总结一下SCPNet,SCPNet概括起来有一下几个contributions:
- SCPNet提出用一个很简单的SCP loss来实现local feature监督global feature的目标。这个方式比AlignedReID更加直观也更加有效。并且还可以把PCB的优点吸引进来。
- SCPNet可以同时提高person ReID和partial ReID的性能。这个是非常有实用价值的一点,我们肯定不希望对这两个任务做一个二分类的判定然后用不同的模型去解决。
总体而言,SCPNet的motivation是比较清晰的,而主要创新点也很简单,最终效果也不错,实用性也OK。但是为什么没有得到顶会认可,我认为有主要几个原因:
- 最重要的致命原因就是多数据集训练,这个就是被ECCV拒稿的核心原因,做Ablation study也许review可以忍忍,但是和stoa比较的时候是无法忍受的,所以这就是学术上的原因。
- 对比实验比较充足,但是缺少部分重要的对比实验。比如和PCB的比较,虽然论文和Local分支进行了比较,但是没有和PCB比较,应该在相同的baseline条件下训个PCB,然后用SCPNet和PCB比较一下才更有说服力。此外就是和DSR比较的不公平,两个论文的baseline水平是不一样的,如果真要严谨一点应该在自己的baseline上测试一下DSR的结果,这样才能看出两个方法在partial ReID任务上的优劣。当然因为ACCV水平更次一等的原因没有被针对,但是从学术严谨的角度上来讲应该是要补充的。
- partial ReID任务还是比较乱的,目前partial ReID的数据集又小,评测又不统一,这个需要有个工作来统一一下。
其实论文能否能中未必是方法好不好,性能强不强,很重要的一点就是论文一定要能给别人带来不一样的东西,能给别人带来启发,并且要有实验结果来证明你的结论。我认为SCPNet是有的,就是传承PCB和AlignedReID的结论,然后用一种很简单的方式融合起来,并且告诉大家这种方法在两个ReID的任务中都是有效的。而充分的Ablation study和可视化展示也证明了结论是可信的。
[1] Sun Y, Liang Z, Yi Y, et al. Beyond Part Models: Person Retrieval with Refined Part Pooling (and A Strong Convolutional Baseline)[C]// European Conference on Computer Vision. 2018.
[2] Zhang, X., Luo, H., Fan, X., Xiang, W., Sun, Y., Xiao, Q., Jiang, W., Zhang, C., Sun, J.: AlignedReID: Surpassing Human-Level Performance in Person ReIdentification (2017)
[3] Xing Fan, Hao Luo, Xuan Zhang, et al. SCPNet: Spatial-Channel Parallelism Network for Joint Holistic and Partial Person Re-Identification[C]//Asian Conference on Computer Vision. Springer, Cham, 2018.

