数据挖掘中常见的「异常检测」算法有哪些?

无监督学习:异常检测入门
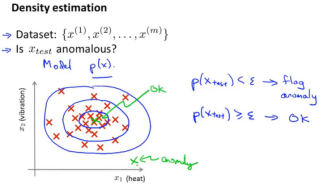
目的:
对于无标签样本,给出一个测试样本属于训练样本集的可能性,可用于欺诈检测(如 异常行为用户检测)等。
高斯分布参数估计(MLE):
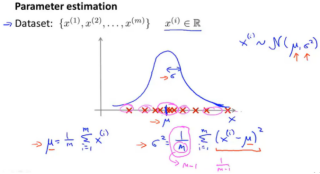
注:1/m和1/m-1仅在理论特性上有区别,实际计算差别不大。
算法流程:


注:
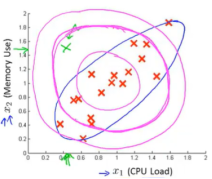
μj为特征xj的均值;不要求各特征独立正态分布(但高斯分布效果更好); p<ε区域都认为异常。(此处p(x)表示为多个独立高斯乘积形式,对于2 维特征,在x1x2平面只能拟合出圆形、水平椭圆和垂直椭圆;不能很好的拟 合x1x2相关的倾斜椭圆情况,需要用到多元高斯分布来建模p(x))
如何选择ε及评价检测能力:
需要带标签数据构建训练集(正常类y=0(又叫负向类))、交叉集(正常类+异 常类)和测试集(正常类+异常类),并且由于异常样本少,需要用偏斜类评价参 数F1等评价。
由训练集估计正态分布参数计算p(x);
由交叉集在不同ε下分类结果计算F1选择ε;
由测试集根据偏斜类参数评价最终算法模型。

异常检测和监督学习的区别:
异常检测和监督学习都是利用带标记样本进行训练,有区别,可相互转换。
什么时候使用异常检测?
当正向类(positive,异常类)很少,种类很多,很难覆盖未来可能遇到的种 类时,我们只利用负向类高斯模型建模。如欺诈行为检测、飞机引擎检测、计 算机集群的计算机运行情况等。
什么时候使用监督学习?
同时有大量正向类和负向类,未来正向类和训练集类似时。如垃圾邮件分类、 天气预报、肿瘤分类等。
特征调优处理:
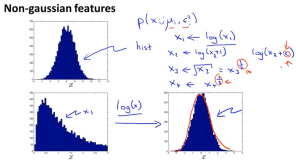
特征转换:
非高斯分布(hist观察)特征转(一般取log或次幂)高斯分布,不必须,但 转换后效果更好。(hist函数可将1维特征x转换成直方图,通过将x轴分段, 落入每段内点数作为纵坐标)
误差分析及特征选取:
分析错分样本,设计新特征或特征组合,将正常类和异常类区分开。
多元高斯分布:
对于特征相关的情况,多元高斯拟合效果更好,n为特征数,m样本数,x=[x1,x2,...], μ=[μ1,μ2,...]。
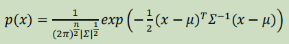
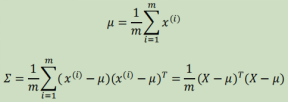
μ决定最高概率点位置,协方差sigma决定形状,对于2维特征分布如下:
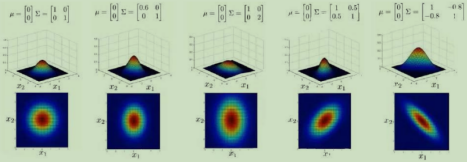

注:
Sigma对角阵时,x1x2不相关,多元高斯和独立高斯乘积可相互先换:
p(x;μ,sigma)=p(x1;μ1,σ12)·p(x2;μ2,σ22);
其中μ=[μ1,μ2];sigma对角元素为σ12和σ22。
独立高斯乘积模型和多元高斯模型如何选择:

注:
(1)特征相关时两种模型都可以使用,但原始模型需要手动创建特征来捕获异常;
(2)多元高斯模型要对n×n的sigma矩阵求逆,n较大计算慢;
(3)多元高斯要求m大于n(10n)且选取特征线性无关,否则sigma奇异;