FairMOT论文阅读笔记(巨详细版)

论文地址:FairMOT: On the Fairness of Detection and Re-Identification in Multiple Object Tracking
代码地址:ifzhang/FairMOT
摘要:
多目标追踪的关键组成部分就是目标检测加上ReID
提出问题:经作者研究表明,以前方法准确性低主要是因为ReID任务没有公平地学习,导致了很多身份切换,不公平之处主要有两点:
(1)将ReID视为次要任务,其准确性在很大程度上取决于主要检测任务。 因此,训练在很大程度上偏向于检测任务,而忽略了re-ID任务;
(2)它们使用ROI-Align去直接提取目标检测中的特征用于re-ID任务;
这样会导致所采样的目标特征点可能属于实例和背景中干扰项。
为了解决这样的问题,提出了一种简单的方法FairMOT,由两个齐次的分支去用于预测像素级的目标度分数和re-ID特征,任务之间实现的公平性使FairMOT获得高水平的检测和跟踪精度,并在几个公开数据集上大大超过了以前的先进技术。
引言:
多目标跟踪(MOT)一直是计算机视觉的一个长期目标,其目的是估计视频中感兴趣对象的轨迹。 问题的成功解决,可以使视频分析,动作识别,智能老年人护理,人机交互等多种应用受益。
现有的方法,通常通过两个单独的模型来解决这个问题:检测模型首先通过每个帧中的包围框来定位感兴趣的对象,然后关联模型为每个包围框提取重新识别(Re-ID)特征,并根据在特征上定义的某些度量将其链接到现有的轨道之一。在视频流的每一帧中,我们希望评估当前检测器,识别其错误并更新它,以避免将来出现这些错误。
近几年,在目标检测和re-ID方面分别取得了显著进展,这又大大提高了整体跟踪性能。 然而,这些方法不能执行实时推理,特别是当有大量对象时,因为这两个模型不共享特征,它们需要对视频中的每个边界框应用re-ID模型。
随着多任务学习的成熟,使用单个网络估计对象和学习re-ID特征的一次性跟踪器受到了更多的关注。不幸的是,与两步跟踪相比,跟踪精度明显下降。 特别是,ID交换的数量增加了很大的幅度。 结果表明,将这两个任务结合起来是一个非平凡的问题,应该仔细处理。 本文旨在深入了解失败背后的原因,并提出一种简单而有效的方法。 特别是,确定了三个因素。
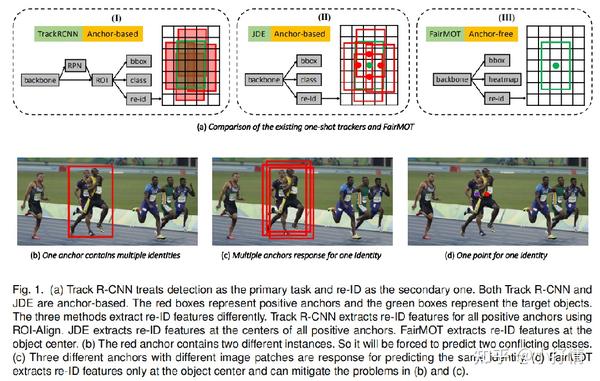
1.1.Unfairness Caused by Anchors
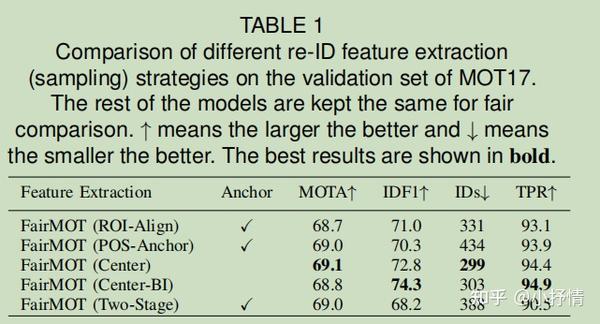
现有的one-shot追踪器大多是基于anchor的。例如YOLO,Mask RCNN。经研究发现基于anchor的框架不适合学习re-ID特征。尽管它有好的检测结果,但是也会导致大量的ID切换。
One anchor corresponds to multiple identities:
基于锚的方法通常使用ROI-Pool或ROI-Align从每个建议中提取特征。 大多数取样地点在ROI中,Align可能属于错误的实例或背景,因此,提取的特征在准确和鉴别地表示目标对象方面并不是最优的。
Multiple anchors correspond to one identity:
多个相邻的锚,它们对应于不同的图像块,只要它们的IoU足够大,就可能被迫估计相同的标识。 这给训练带来了严重的歧义。 另一方面,当图像经历小扰动时,例如由于数据增强,可能同一锚被迫估计不同的身份。 此外,目标检测中的特征映射通常被降采样8/16/32次,以平衡精度和速度这对于对象检测是可以接受的,但对于学习ReID特征来说太粗糙了,因为在粗锚处提取的特征可能不与对象中心对齐。

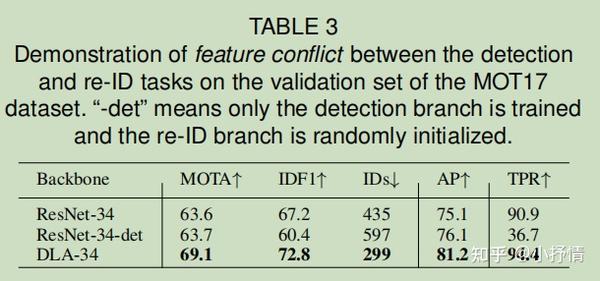
1.2.Unfairness Caused by Features
对于one-shot追踪器,大多数特性在目标检测和re-ID任务之间共享。 但众所周知,它们实际上需要来自不同层的特征才能达到最佳效果。 特别是,目标检测需要深度和抽象的特征来估计对象类和位置,但re-ID更多地关注低级外观特征,以区分同一类的不同实例。
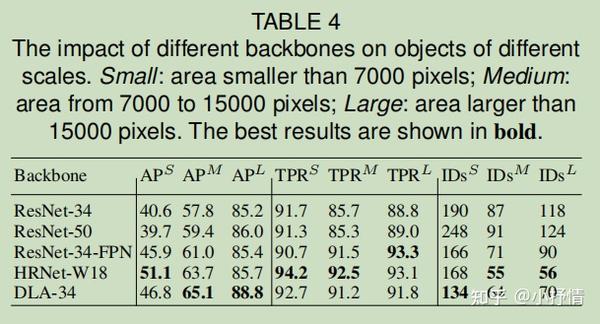
多层特征聚合通过允许两个任务(网络分支)从多层聚合特征中提取所需的任何特征来有效地解决矛盾。 如果没有多层融合,模型将偏向于初级检测分支,并产生低质量的re-ID特征。 此外,多层融合,融合了不同接收场的层的特征,也提高了处理对象尺度变化的能力,这是在实践中非常常见的。
1.3.Unfairness Caused by Features Dimension
以前的re-ID工作通常学习非常高维的特征,并在其领域的基准上取得了有希望的结果。 然而,我们发现学习低维特征实际上更适合于one-shot MOT,原因有三:
(1)虽然学习高维ReID特征可能会稍微提高它们区分对象的能力,但由于这两个任务的竞争,它显著地损害了目标检测的准确性,这反过来也对最终的跟踪精度产生了负面影响。 因此,考虑到目标检测中的特征维度通常很低(类号框位置),我们建议学习低维re-ID特征来平衡这两个任务;
(2)当训练数据较小时,学习低维re-ID特征降低了过度拟合的风险。 MOT中的数据集通常比re-ID中的数据集小得多。 因此,它有利于降低特征维数;
(3)学习低维re-ID特征提高了推理速度,如我们的实验所示。
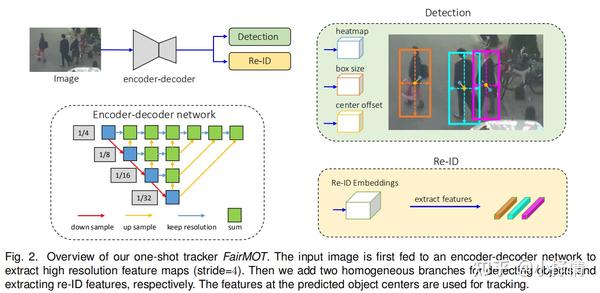
1.4.Overview of FairMOT

2. Related Work
2.1. Non-deep Learning MOT Methods
多目标跟踪算法被分为两类,在线方法和批处理方法。
在线方法依赖当前帧和先前帧进行追踪。
批处理方法依赖整个视频序列。
大多数在线方法假设目标检测是可用的,并将重点放在数据关联步骤上。例如:
SORT首先利用卡尔曼滤波来预测未来的目标位置,计算它们与未来帧中的目标重叠,最后采用匈牙利算法进行目标匹配达到追踪。
IOU-tracker在不使用卡尔曼滤波的情况下,通过其空间重叠直接关联相邻帧中的检测,达到追踪效果。
由于SORT和IOU-Tracker的简单性,在实践中得到了广泛的应用。 然而,由于缺乏re-ID功能,它们可能无法满足诸如拥挤场景和快速相机运动等具有挑战性的场景。
批处理方法由于其在整个序列中的有效全局优化,取得了比在线方法更好的效果。
2.2. Deep Learning MOT Methods
一些很优秀的方法将对象检测和re-ID视为两个单独的任务。
两步方法的主要优点是它们可以分别为每个任务开发最合适的模型,而不做妥协。 此外,它们还可以根据检测到的边界框裁剪图像补丁,并将它们调整到相同的大小,然后再估计re-ID特征。 这有助于处理对象的尺度变化。 因此,这些方法在公共数据集上取得了最佳性能。它们通常非常缓慢,因为这两个任务需要单独完成,而不需要共享。因此,在许多应用中很难实现视频速率推理。
随着多任务学习的快速成熟,在深度学习中,one-shot MOT已经开始引起更多的研究关注。 其核心思想是在单个网络中同时完成对象检测和身份嵌入(re-ID特征),以减少推理时间。 例如,Track-RCNN在MaskR-CNN的顶部添加了一个re-ID头并为每个建议返回一个边界框和一个re-ID功能。 同样,JDE是建立在YOLOv3之上的。它实现了接近视频速率的推理。 然而,一次跟踪的精度通常低于两步跟踪的精度。
3. FAIRMOT
3.1.Backbone Network
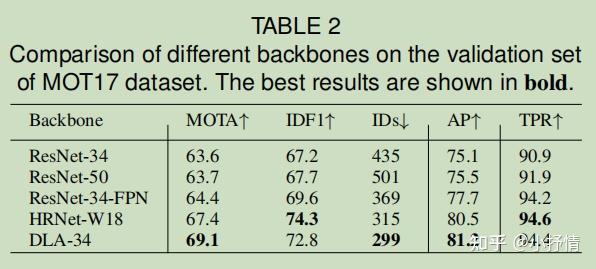
采用了ResNet-34网络作为backbone,深度层聚合(DLA)的增强版本被应用于骨干以融合多层特征。与原来的DLA不同,它在低级和高级特征之间有更多的跳过连接,这类似于特征金字塔网络(FPN)。
此外,所有上采样模块中的卷积层都被变形卷积所取代,使得它们可以根据目标尺度和姿态动态调整感受野。这些修改也有助于缓解对齐问题。 得到的模型命名为DLA-34。
输入图片尺寸定义为 H_{image} *W_{image} 。
输出特征图为 C*H*W , H=H_{image}/4 , W=W_{image}/4 ,除了DLA之外,其他提供多尺度卷积特征的深层网络,如高级HRNet,可以在我们的框架中使用,为检测和re-ID提供公平的特性。
3.2.Detection Branch
检测分支使用了CenterNet。特别是,将三个平行头附加到DLA-34上,分别估计热图、对象中心偏移和包围盒大小。 每个头都是通过对DLA-34的输出特征应用3×3卷积(具有256个通道)来实现的,然后是1×1卷积层,它生成最终的目标。
3.2.1.Heatmap Head
3.2.2.Heatmap Offset and Size Heads
主要介绍三个输出的Loss,HeatMap:Focal loss ,box offset ,size:L1 loss ,详情参考Objects as points论文。
3.3.Re-ID Branch
Re-ID分支旨在生成能够区分目标的特性。 理想情况下,不同目标之间的亲和力应该小于相同目标之间的亲和力。 为了实现这一目标,我们应用了128个内核的卷积层在骨干特征之上提取每个位置的re-ID特征。 表示得到的特征映射为 E\in R^{128\times W \times H} 。从特征映射中可以提取以(x,y)为中心的目标的ReID特征 E_{x,y}\in R^{128} 。
3.3.1 Re-ID Loss
作者通过分类任务学习re-ID特征。 训练集中相同标识的所有对象实例都被视为同一类。


3.4.Training FairMOT
主要介绍了几个loss函数
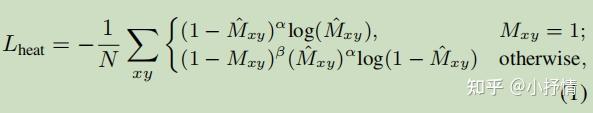

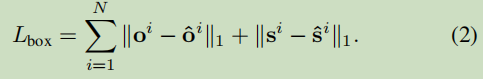

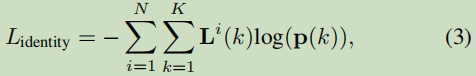

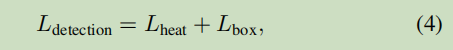

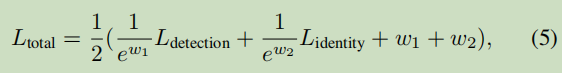

除了上述的标准训练策略外,我们还提出了一种弱监督学习方法来训练COCO等图像级目标检测数据集的FairMOT。将数据集中的每个对象实例视为一个单独的类,并将同一对象的不同转换视为同一类中的实例。所采用的转换包括HSV增强,旋转缩放,平移和剪切。
在CrowdHuman数据集上预先训练我们的模型然后在MOT数据集上finetune。 通过这种自我监督的学习方法,我们进一步提高了最终的性能。
3.5.Online Inference
3.5.1.Network Inference
与以前的工作JDE相同,网络以大小为1088×608的帧作为输入,在预测的热图之上,根据热图分数执行非最大抑制(NMS),以提取峰值关键点。保留热图分数大于阈值的关键点的位置。然后,根据估计的偏移量和框大小计算相应的包围框。我们还在估计的对象中心提取标识embedding。
3.5.2.Online Association
遵循标准的在线跟踪算法来关联框。
首先根据第一帧中的估计框初始化一些轨迹。 然后,在随后的帧中,根据在Re-ID特征上计算的余弦距离将检测到的与现有的轨迹进行链接,并通过Bipartite matching将它们的盒重叠。我们还使用卡尔曼滤波来预测当前帧中轨迹的位置。如果它离链接到的检测太远,我们将相应的成本设置为无穷大,这有效地防止检测目标移动过大。 我们在每个时间步骤中更新跟踪器的外观特征,以处理外观变化。
4.EXPERIMNETS
随后通过大量的对比实验验证最好的追踪网络选择。