
推荐系统中的对抗机器学习技术总结

近年来,随着硬件基础以及算法能力的显著提高,以深度学习模型为代表的机器学习技术得到了学术界和工业界的广泛关注。由于出色的特征表示能力和数据拟合能力,深度学习模型已经席卷机器学习应用的各个子领域,比如计算机视觉、自然语言处理、网络科学、推荐系统等。


然而,随着学者们的深入研究发现,深度学习模型存在对抗样本攻击的可能[1],这使得模型的安全性、鲁棒性以及泛化能力得到巨大的挑战。其中,对抗样本是一种人为设计的非随机的扰动,将其添加到输入样本后与原始输入样本相比人的视觉上没有明显差异,但模型却以较高置信度判别成其他错误的类别(如下图添加扰动后,模型将熊猫以99%的置信度判别为了长臂猿)。


采用对抗学习的方式来生成对抗样本进而对模型进行攻击不是最终目的,我们最终的使命是通过将其建模为最大最小博弈问题让模型学习原始样本以及对抗样本进而增强模型的鲁棒性和安全性。对抗学习的研究始于计算机视觉[2],而后过渡于自然语言处理[3],如今也开始蔓延到推荐系统领域[4]。因此本文试图结合自己的理解对相关综述[5]进行总结,介绍下对抗机器学习技术在推荐系统中的应用和发展。
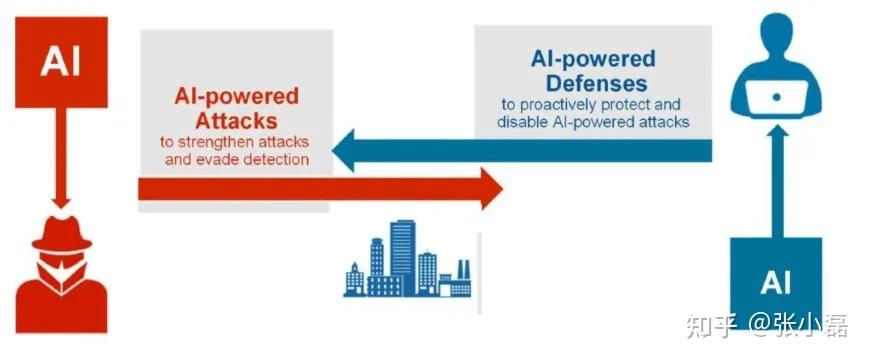

推荐系统,作为数据生产者与信息消费者之间博弈均衡的有效手段之一,逐渐得到了学术界和工业界的广泛关注。特别是,基于隐因子模型的协同过滤算法,例如矩阵分解和深度协同过滤方法,由于其出色的性能和推荐准确性而广泛用于现代推荐系统中。尽管它们取得了巨大的成功,但近年来已表明,这些方法容易受到对抗样本的攻击,即迫使推荐模型产生错误。因此,近年来,结合对抗训练以及对抗样本的机器学习技术得到了广泛关注。
对抗机器学习,顾名思义,是一种利用对抗博弈思想的机器学习技术,是一种结合了机器学习与计算机安全方向的交叉领域。通过在Google Trends上对“对抗机器学习”进行检索发现,该方向检索热度逐年上升,特别是2014年以后增长势头更是迅猛,可见对抗机器学习技术成为了研究的热点问题。
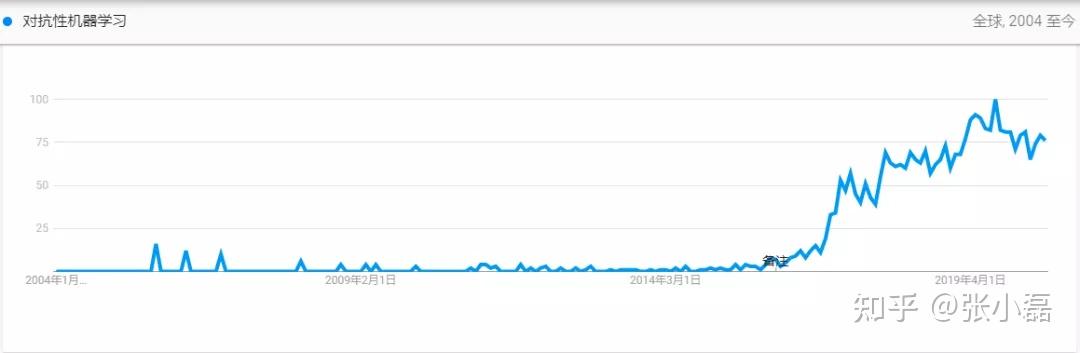

之所以2014年实现了陡峰式的增长,是因为这一年Goodfellow所提出的著名的生成式对抗网络以及对抗样本的生成算法,而这两种新发现都利用到了对抗博弈思想,因此促进了对抗机器学习领域的大发展。

由于对抗机器学习技术主要涉及两方面内容,分别是利用对抗模型的生成能力来提高样本的质量和利用对抗训练技术来提高模型的鲁棒性和安全性。因此本文的目的也是两类,即一方面展示对抗机器学习技术在推荐中的生成能力;另一方面展示对抗机器学习技术在推荐系统领域安全方面的最新进展(即攻击和防御的推荐模型)。
推荐算法分类
首先总结下自推荐系统诞生后到现阶段该领域的发展与分类,在此之前梳理过一篇一文尽览推荐系统模型演变史。如下图所示,根据作者理解将推荐系统的发展主要分为了两个时代,即专注于提升推荐精度的时代(绿色部分,专注于提高推荐准确性等评价指标),和后深度学习时代(粉色+黄色部分,从经典的学习范式到对抗机器学习过渡)。
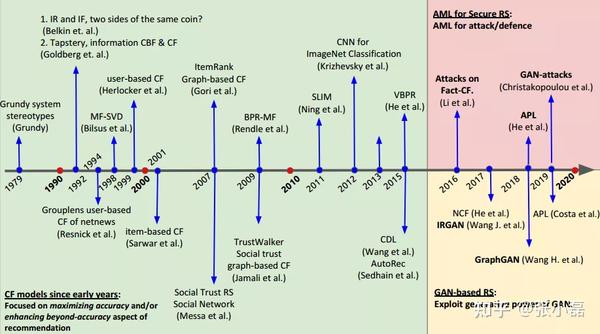

专注于提升推荐精度时代(绿色区域)主要分为了三部分:经典的非神经网络方法、领域依赖的方法和深度神经网络方法。
- 经典的非神经网络方法:主要是指90年代及以前的基于协同过滤思想的算法,比如根据模型训练方式可以分为基于记忆的方法和基于模型的方法,更多关于该算法详细内容可参考推荐系统从入门到接着入门。另外,可以根据建模时损失函数的不同分为point-wise的方法、pair-wise的方法以及list-wise的方法,更多详细内容可参考推荐系统中排序学习的三种设计思路。
- 领域依赖的方法:该类方法大概是2000年之后主要是基于推荐系统某一子领域进行研究,比如为了缓解传统协同过滤方法的数据稀疏以及冷启动问题;引入社交数据(社会化推荐)、引入知识图谱(基于知识图的推荐)等附加信息;比如为了给推荐结果提供合理的解释而产生的推荐系统可解释性的研究方向等等,我们总结了15个推荐子领域的方向供大家学习带你认识推荐系统全貌的论文清单。
- 深度神经网络的方法:该类方法主要是得益于2014年及以后深度学习强大的表征能力和数据拟合能力,基于深度学习的推荐系统成为了火热的研究方向。该领域主要分为两大类别,一种是提高用户或者物品的特征表示的方法,比如利用CNN来抽取物品的深层次视觉特征表示用来更好的提供推荐、利用GNN来提取用户的社交网络信息来提高推荐精度等方法;另一类方法主要是利用深度学习技术的拟合能力和建模能力,比如NCF用非线性的多层感知机来替代简单的内积操作,利用GRU4Rec来建模用户的行为序列等。更多关于深度推荐系统的内容欢迎参考当推荐系统邂逅深度学习。
更具体的,专注于提升推荐精度的时代的主要代表方法如下图所示。
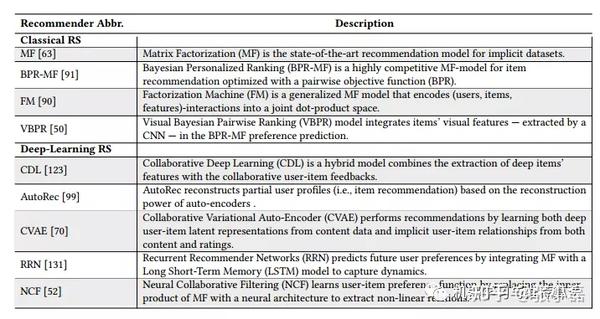

后深度学习时代(粉色+黄色区域)主要指2017年之后的由经典的机器学习方式到对抗机器学习方法的转变。正因为之前的研究偏向于关注模型的准确性、时效性等直接目标,导致了模型在可解释性、鲁棒性、安全性方面的指标相对较弱,因此后深度学习时代大家更加关注这些指标。针对于对抗机器学习的利用,目前主要是利用对抗学习的方式来显式指定判别器来指导生成模型产生样本的质量(基于GAN的推荐系统)以及利用对抗训练的思想来显式的指定攻击模型进而提高模型的鲁棒性和安全性(基于安全防御的推荐系统)。
基于GAN的推荐系统总结
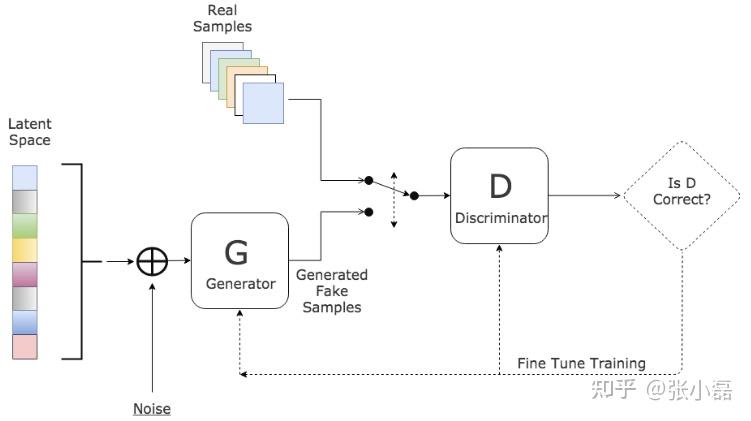
利用生成对抗网络的思想结构来进行推荐样本的生成的主要思路如下图所示。其原理基本与原始的生成对抗网络的结构一样,分为生成器和判别器。生成器通过用户侧的信息来产生生成的物品编号,判别器用来判别该物品是否为用户真正喜欢的物品的概率,最终在对抗训练的指导下生成器能够生成真实的物品编号,判别器判断不出来是否是真实的物品编号。
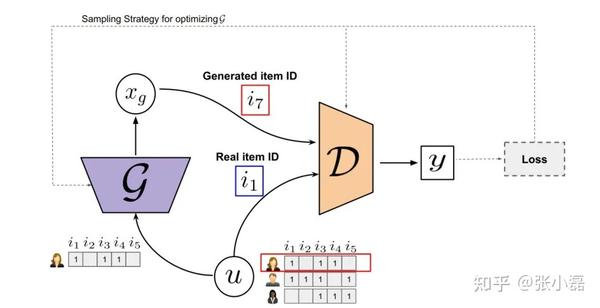

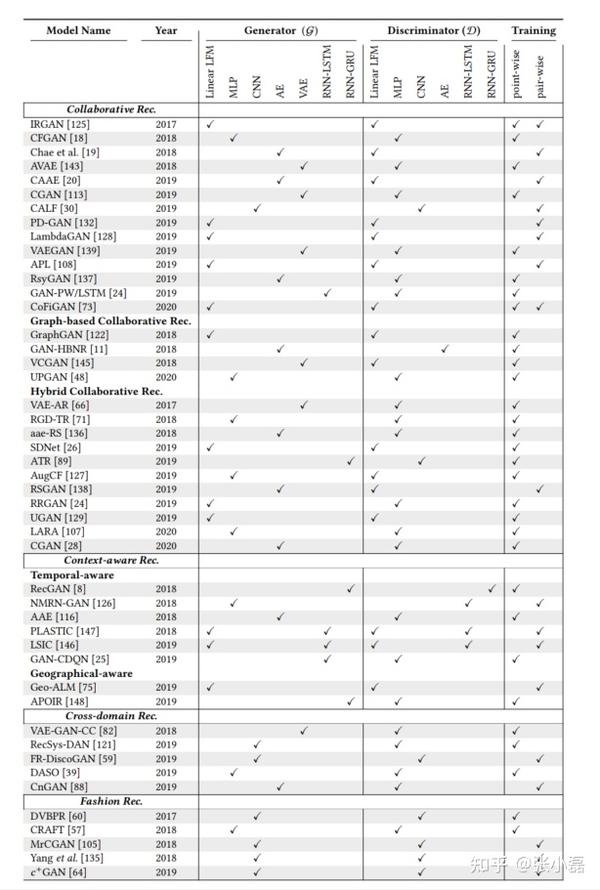
其中,IRGAN方法是第一个将GAN的思想应用到信息检索领域的模型,但其与CV领域不同的是,生成器需要生成的是离散的项目编号,因此传统的反向传播算法不能适用,所以采用强化学习中的策略梯度来进行更新参数;另外,CFGAN方法将GAN与推荐中的协同过滤相结合,与IRGAN不同的是,该方式不是生成离散的项目编号,而是生成实数向量的方式来解决样本混淆的问题。利用对抗训练方式来提高推荐模型生成样本质量的主要代表方法如下图所示。

基于安全防御的推荐系统总结
对于安全方面的内容,我们有必要了解一下基本概念,比如对于攻击的分类方式以及对于防御攻击的常用方式。对于攻击的分类按照攻击难以程度的不同、攻击阶段的不同、攻击目标的不同以及攻击手段的不同都会有相应的分类。按照攻击难易程度分为黑盒攻击、白盒攻击和灰盒攻击。
- 黑盒攻击:即攻击者对模型和训练集几乎没有任何背景知识,只能拿到模型的输出结果。这种攻击方式较难但是最符合实际场景。
- 白盒攻击:即攻击者对模型和训练集的知识背景掌握较多,比如模型结构、梯度等信息。这种攻击方式比较容易成功,但和实际场景的设定差距较远。
- 灰盒攻击:即攻击者掌握模型和训练集的部分情况,介于黑盒和白盒之间的一种情况,比如能够拿到数据集的部分数据或者掌握模型的参数、超参数或者梯度等信息。
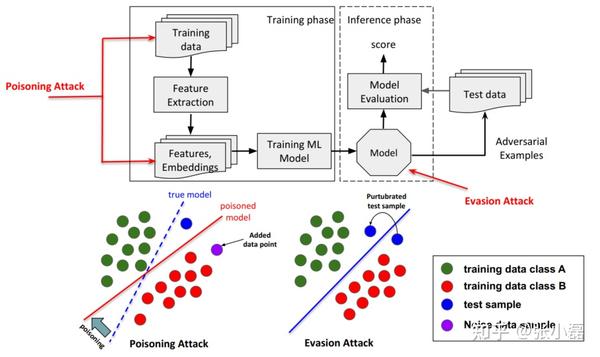
按照攻击阶段分为中毒攻击和逃避攻击。
- 中毒攻击:(Poisonning attack) 即在模型的训练阶段添加相对应的攻击样本,使得模型的参数或者分界面产生相应的改变,比如推荐系统中的托攻击(Shilling Attack)。
- 逃避攻击:(Evasion attack) 即在模型的推理/测试阶段通过改造样本而使得模型分类产生改变,比如利用FGSM方法生成的对抗样本攻击。

按照攻击目标分为有目标攻击和非目标攻击。
- 定向攻击:即对于一个模型,通过攻击使得输入数据错误分类到一个指定的类别上。反映到公式上就是在最小化扰动delta的同时通过添加扰动使得模型f分类为指定的yt。
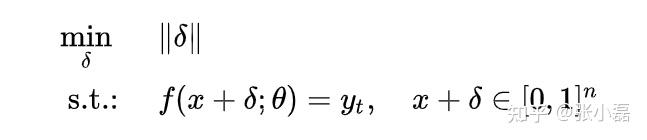

- 非定向攻击:即对于一个模型,通过攻击使得输入数据分类错误即可,不需指定分类为某种具体的类别。反映到公式上就是在最小化扰动delta的同时通过添加扰动使得模型f分类为除了y之外的类别。
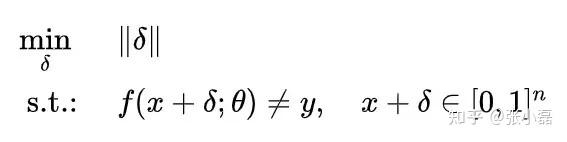

按照攻击手段分为成员推理攻击、模型反演攻击、超参数攻击、用户属性攻击等(在此没有关注不可信的数据收集者、不可信传输以及不可信云储存等攻击)。当然随着新技术与新模型的不断发展,人们也考虑了最新相关的攻击,比如从BERT中发现存在信息泄露的可能[6]、比如对GNN模型进行分析进行链接攻击[7]等。
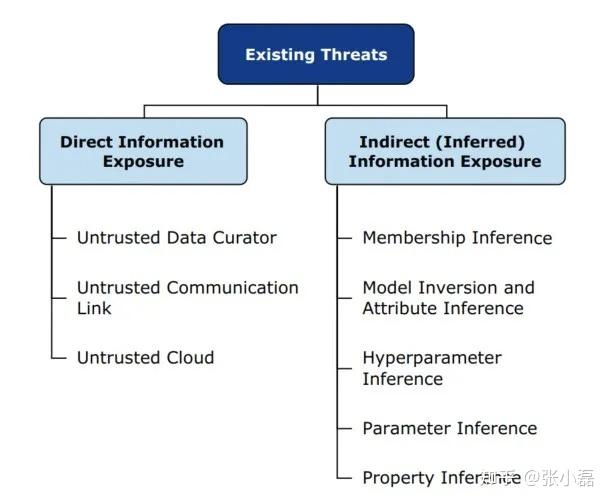

介绍完相关的攻击分类后,我们大致介绍下防御攻击的保护手段。防止模型遭受攻击的手段主要是通过在数据收集阶段、数据训练阶段以及推理阶段进行保护,所涉及的技术包括匿名化、差分隐私、多方安全计算、同态加密等算法。另外对抗机器学习、联邦学习等最新的技术现在也得到了越来越多的关注。


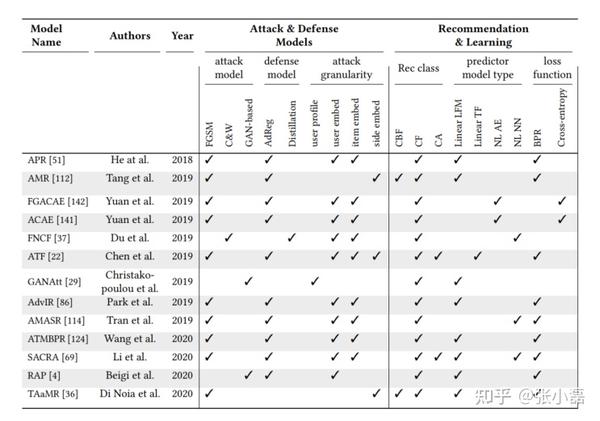
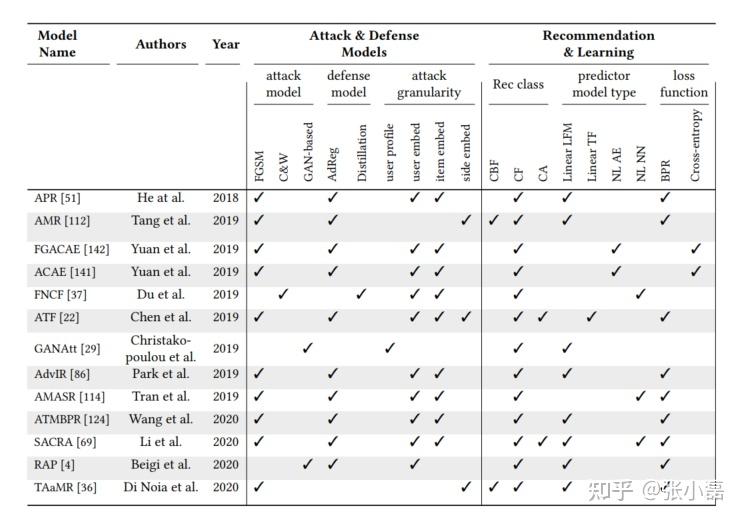
利用对抗思想来提高模型的鲁棒性的主要框架如下图所示,需要显式的指定一个攻击模型,这个攻击模型可以是简单的分类模型,也可以是一个复杂的神经网络模型。另外将防御和攻击看做一个最大最小化博弈问题,使得模型最终得到一个推荐性能良好同时能够抵御模型攻击的综合模型。值得注意的是,与传统计算机视觉中往输入图片中添加扰动不同,推荐系统领域由于输入样本是离散形式,因此需要在它们生成的Embedding上进行扰动/噪声的添加。
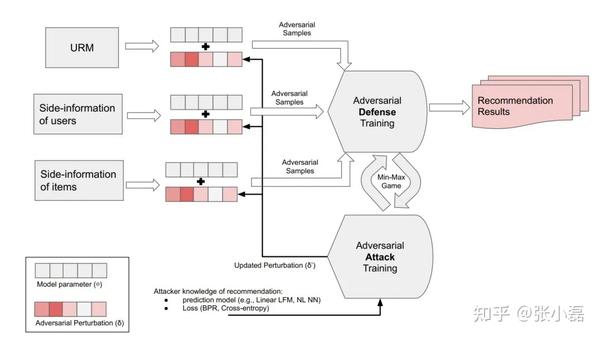

其中,文献[4]提出的对抗方式的BPR方法就是利用对抗训练的方式来产生对抗样本进而同正常样本一同参与训练来提高模型的鲁棒性和泛化能力;文献[9]提出的RAP方法通过显式的训练一个用户属性攻击模型,进而利用对抗训练的方式来提高推荐模型的推荐质量以及抵御用户属性攻击的能力。利用对抗训练方式来提高推荐模型抵御攻击的主要代表方法如下图所示。
世界上许多事物都存在两面性,任何一方的优势都有可能成为另一方的劣势,机器学习/深度学习模型亦是如此。当模型凭借着高算力进行一味地数据投喂时,虽然能够挖掘出用户精准的行为偏好,但无疑会提高对用户的隐私数据造成泄露的风险。所以如何权衡大数据的有效性与隐私安全是一个值得我们深入研究的问题。以上的总结希望能够对大家有所帮助。
更多关于对抗机器学习在推荐中应用的相关论文和代码,可参考如下仓库。
https://github.com/hongleizhang/RSPapers
https://github.com/advboxes/AdvBox
https://github.com/sisinflab/adversarial-recommender-systems-survey
嘿,记得关注“机器学习与推荐算法”呀~
参考文献
1. Szegedy et al. Intriguing properties of neural networks. ICLR, 2014.
2. Goodfellow et al. Explaining and Harnessing Adversarial Examples. ICLR, 2015.
3. Miyato et al. Adversarial Training Methods for Semi-Supervised Text Classification. ICLR, 2017.
4. He et al. Adversarial Personalized Ranking for Recommendation. SIGIR, 2018.
5. Deldjoo et al. Adversarial Machine Learning in Recommender System. 2020.
6. Carlini et al. Extracting Training Data from Large Language Models. 2020.
7. He et al. Stealing Links from Graph Neural Networks, USS, 2020.
8. Gunes et al. Shilling attacks against recommender systems: a comprehensive survey, 2014.
9. Beigi et al. Privacy-aware recommendation with private-attribute protection using adversarial learning. WSDM, 2020.

