
“简单粗暴”的R语言爬虫·其一

其实离我刚接触网络爬虫的时候,已经过去了很久的时间了。借此机会,就当重新温习一下知识。对于网络爬虫,我也没有到达特别专业的程度,也只是满足自己在数据采集上的需求,所以如果有说得不对的地方,麻烦大家多多指出(〃'▽'〃)。
一、网页小知识
我们平时浏览的网页,形式多样,但其实都是由一系列网页语言编译而成的,而网页上的数据信息则被嵌套在编译语句之中。为了符合主题“简单粗暴的爬虫”,我们就不详细介绍网页那些复杂的结论以及原理,我们只需要知道怎么去定位藏在网页代码中的数据和如何将数据获取到本地。
1、网页元素的定位
我们可以使用右键点击查看网页源代码,从而可以观察整体网页的排布。之后就是关键的一步,定位数据的位置。我们通常会使用xpath和css两种方法去定位数据。下面我们看一下简单的网页代码:
<div class="category_depth_1 bnr">
<li><a href="/estore/kr/zh/c/1" class="on">护肤</a></li>
<li><a href="/estore/kr/zh/c/1" class="on">家电</a></li>
<li><a href="/estore/kr/zh/c/1" class="on">美妆</a></li>
<li><a href="/estore/kr/zh/c/1" class="on">母婴</a></li>
<li><a href="/estore/kr/zh/c/1" class="on">电子产品</a></li>
</div>其实普通的网页从结构看上去还是非常有规律的,假如我们需要定位都上面的中文单词,我们应该如何操作呢?其实只要我们认真观察一下,就会发现中文单词都被<a>.....</a>所包括,此时我们可以用xpath的式子去定位——'//div///li//a'。我们发现其实xpath定位就是遵循层次的顺序,由外到内,用//连接各层的标签名,这是xpath中最简单的定位方式。如果小伙伴对xpath的其他具体定位方法有兴趣的话,可以参考下面的网页:
除了xpath的定位方法之外,我们常用的还有css定位方法。此处的css其实是一种用于修改网页样式的一种语言,而我们正好能利用其规律对网页的元素进行定位,例如我们同样地定位上面的中文单词,我们可以用'div li a'进行定位,与xpath有点相识,将各层的标签名称用空格连接。当然这仅仅是最简单的利用css进行定位,更详尽的方法可以参考下面的链接:
2、网页的"类型"
网页的类型如果正经来说会分成多种多样,比如HTML、XML、JSON等等。但是我理解的“类型”其实就分为2种:第一种是能够直接参访问代码并且定位获取网页数据的一般网页,另外一种就是使用了某些特殊的技术让我们不能够采用通常办法去获取网页数据的特殊网页。而在我们的实际网络中,后者应用也是比较多的,这个也为我们使用爬虫获取数据造成了不少麻烦。只有如何解决后者给我们带来的问题,我们迟点再去介绍。那么下面就由我们用R语言实操一下,如何获取前者网页的数据。在这之前还是得好好认识一下R中常用于网络爬虫的拓展包及其函数。
二、R中的"网爬"包
大佬们估计会从Rcurl这个拓展包说起,但是我觉得对于一些仅仅是利用爬虫去获取所需数据的伙伴来说,这个包还是太不友好且不方便,所以我们就跳过这个包[doge]。那我们直奔主题地引入第一个R包——rvest。
1、read_html()
这个函数是我们创建爬虫脚本的基础,它用于下载网页的源代码。当我们使用该函数将网页的源码下载到本地,就能开始我们提取数据的工作。我们以一个天猫网站为例子,网络连接(URL)为:天猫。只需要执行下面的代码,就能够下载网页的源码:
url = 'https://list.tmall.com/search_product.htm?spm=a220m.1000858.1000723.1.1c5a7c5awATvmK&&from=rs_1_key-top-s&q=%BB%AA%CE%AA%CA%D6%BB%FA'
web = url%>%read_html(encoding="GBK") # 网页的编码格式为GBK就这样我们就可以将网页的源码传给web这个变量。至于网页的编码格式,可以给定也可以忽略不给,这个问题不大。我们可以通过查看网页源码的编码格式:
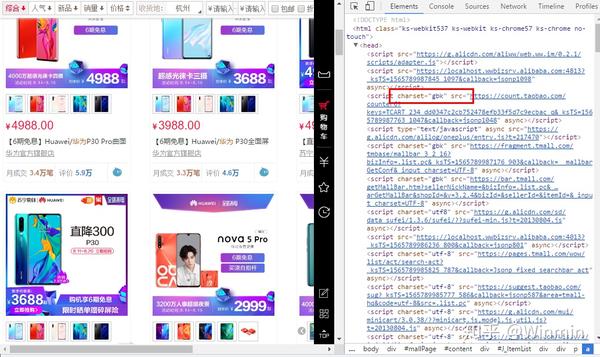

2、html_node()
将网页的页面下载之后,接着就是对网页元素所在的代码块定位了,上面我们提到定位网页元素的两种方法Xpath和Css。而R中定位的工作我们会交给html_node()来处理。比如,我们需要爬取价格元素,则我们可以通过查看网页源代码,然后写出对应的xpath或者css的式子,通过html_node()函数定位到我们的目标元素所在的代码块。
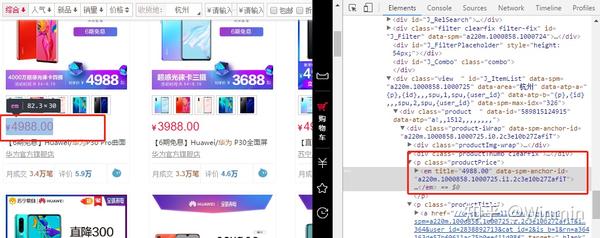

#采用xpath的方法定位代码块
md = url%>%read_html(encoding="GBK")%>%html_nodes(xpath = '//div//p[@class = "productPrice"]//em')
#采用css的方法定位代码块
md = url%>%read_html(encoding="GBK")%>%html_nodes(css = 'div.product-iWrap p.productPrice em')3、html_attr()
当我们锁定了目标元素的代码块,就可以使用下一个取值函数来读取代码块中的值了。同样地我们需要读取上面获取的代码块中的价格数据,我们认真观测可以发现价格数据是属于在<em>层中的属性title的取值,所以我们此时需要用到html_attr()来帮助我们获取属性的取值。
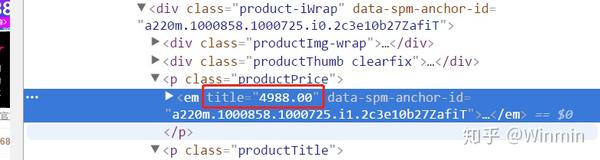

具体完整代码如下:
#执行代码并输出结果
(price = url%>%read_html(encoding="GBK")%>%html_nodes(xpath = '//div//p[@class = "productPrice"]//em')%>%html_attr('title'))
[1] "4988.00" "3988.00" "4988.00" "1199.00" "3988.00" "2999.00" "5099.00" "2199.00" "699.00" "4988.00" "3688.00"
[12] "3688.00" "4099.00" "1099.00" "3699.00" "2199.00" "1099.00" "2999.00" "549.00" "4988.00" "849.00" "2199.00"
[23] "2199.00" "12999.00" "2799.00" "4988.00" "1999.00" "1699.00" "1199.00" "5899.00" "3988.00" "3688.00" "3688.00"
[34] "1999.00" "1249.00" "4988.00" "3688.00" "2399.00" "2199.00" "3688.00" "3199.00" "2199.00" "1199.00" "2999.00"
[45] "2999.00" "2799.00" "1099.00" "1199.00" "1099.00" "2999.00" "1799.00" "749.00" "799.00" "2999.00" "2199.00"
[56] "2999.00" "5099.00" "1999.00" "3688.00" "1049.00" 4、html_text()
上面提到我们使用html_attr()来获取属性值的取值,但如果我们的目标数据在层之间,那么就需要使用html_text()来获取数据了。同样地,我们获取天猫手机网页中的产品名称信息,且看源代码可以发现其值是包含在层之间,这时就正好使用html_text()了。
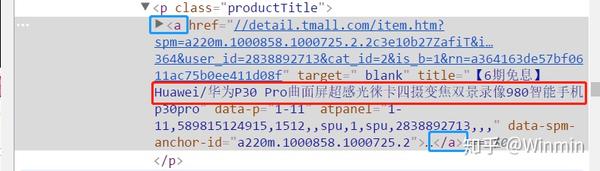

我们只需要修改一下代码,就能够获取手机的名称信息:
(name = url%>%read_html(encoding="GBK")%>%html_nodes(xpath = '//p[@class = "productTitle"]//a')%>%html_text())部分结果如下:


我们可以看到手机的名称信息就被爬取下来了,但是数据看上去包含其他一些东西,比如说头尾的"\n"换行符,还有[]中包含的促销广告,之前在介绍数据处理的文章中也提及到,对于我们爬取到的数据,是需要我们对其进行清洗的,这里也印证了这个事实。如果有对如何清洗这些数据有兴趣的话,欢迎到之前的数据处理文章去寻找方法。
5、html_table()
如何网页中的数据是以表格的形式展现的,那么我们可以使用html_table()将整个表格中的数据爬取下来。我们可以以数据查询结果|数据nba|stat-nba|历史数据|技术统计|最全最专业中文nba数据库 这个网站为例,来看看html_table()的效率。我们进入网站之后,就能看到一张包含数据的表格:
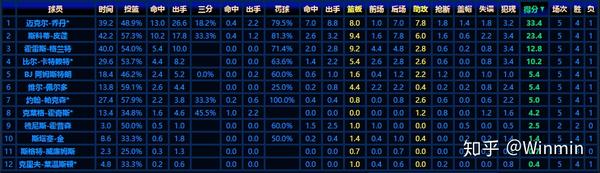

执行简单的代码,就能把整个表格的爬取下来:
url = 'http://www.stat-nba.com/query.php?QueryType=game&GameType=playoff&CW=player&Team_id=CHI&TOpponent_id=PHI&PageNum=40&Season0=1990&Season1=1991&crtcol=pts&order=1'
url%>%read_html()%>%html_table()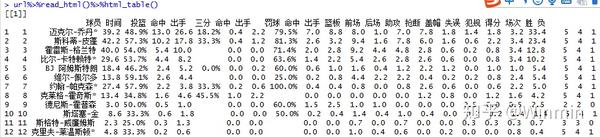

到现在为止我们对于一些普通网页的数据,能够没有压力地爬取。不过如果我们爬取像B站网页上的视频信息,你会发现同样的方法,爬取下来的只有空白,这就是网页对于爬虫的限制,但是对于这个些网站,我们也不是没有办法爬取数据的,至于用什么方法的话,我们下次再介绍,关键字提示一下——selenium。

