
python入门:搭建文字识别OCR

正文开始之前,我得强调此篇文章是面向无基础的新手,所以我们得从环境搭建讲起。
一、python环境搭建
新手强烈建议通过安装anaconda来安装python,因为anaconda作为一款程序环境管理的软件十分强大,安装它之后,python的环境也被安装在里面了,无须再另外操劳了。

二、python第三方库的安装
python之所以火热,这跟它的开源离不开关系,我们可以把第三方库(包、模块)看作是“工具箱”,不同的“工具箱”可以实现不同的功能。那我们此次要用到的“工具箱”有以下三个:requests;base64(python内置的,不用再次“购买”);docx;为了安装这些“工具箱”,我们得去“商店”“购买”,这个“商店”便是电脑的命令行,如果是安装anaconda的,则要进入到CMD.exe Prompt中。
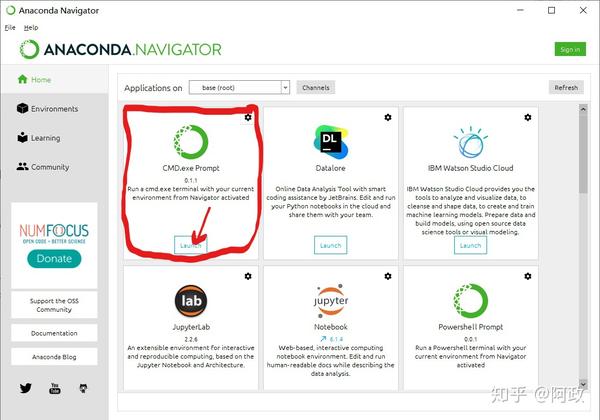

进入到命令行时,我们用以下三个命令安装“工具箱”,下面是“购买”的指令:
pip install requests
pip install docx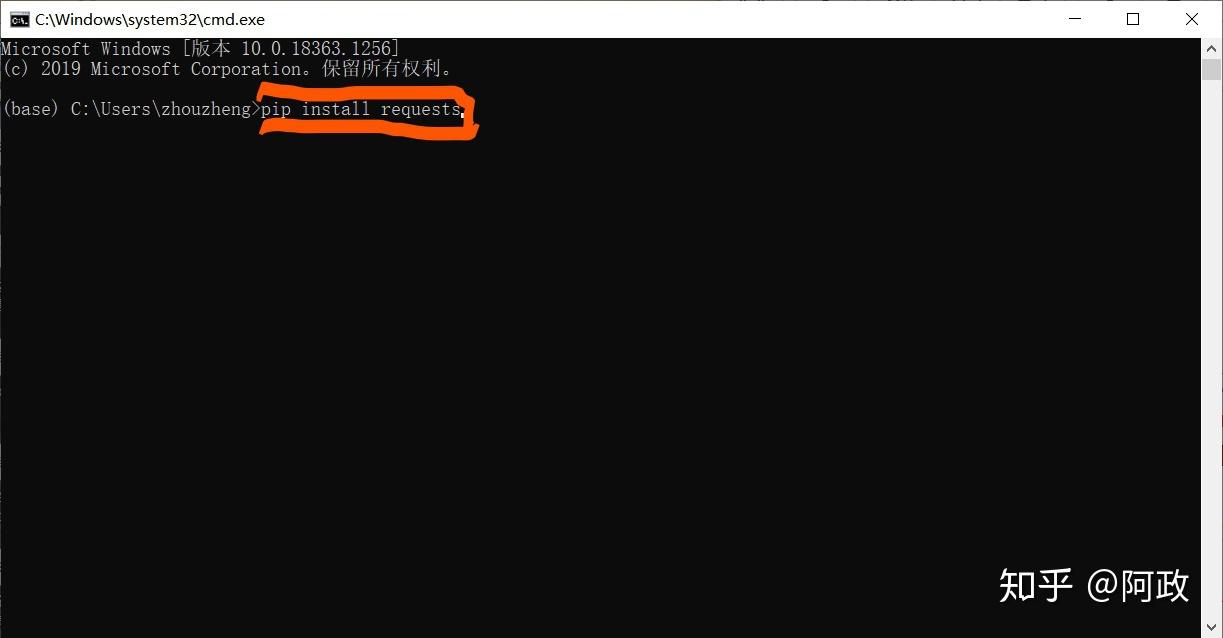

三、正式编程
(一)拿“工具箱”
在python编程中,有一个特点:我们一般要先把所要用到的“工具箱”一一拿出来,就像电工修理电器时,需要拿出电压器,电洛铁等工具。下面是拿“工具箱”的代码。我们用jupyter编程。
import requests #用于请求百度接口
import docx #用于将识别结果存储到docx文档中
import base64 #用于64编码(二)使用百度接口
百度接口具体的使用方法可以到百度云服务官方网站查询,不再赘述。
# client_id 为官网获取的AK, client_secret 为官网获取的SK
host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=SD0q3GnC6t6oWgc690A4Bcif&client_secret=K5yXqDfpnOI8EQfHyvzXGBm2QkL8UpxO'
response = requests.get(host)
token=response.json()
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/handwriting"(三)使用百度接口识别图片文字
f = open('G://data//极大似然估计.png', 'rb') #这里是需要识别的图片文档路径,
img = base64.b64encode(f.read())
params = {"image":img}
access_token = token['access_token']
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if response:
res=response.json()(四)将识别结果存入到docx文档中
doc=docx.Document()
p=doc.add_paragraph()
for item in res['words_result']:
p.add_run(item['words'])
print(item['words'])
doc.save('G://pics//results//读书1.docx') #识别结果文档命名为 读书1.docx编辑于 2021-01-09 03:08
