用于医学图像的基于图的自监督表示学习 | AAAI 2021

本文提出了一种用于医学图像的上下文感知的无监督表示学习方法,其可用来量化COVID-19的临床进展,并证明能很好地泛化到来自不同医院的COVID-19患者,代码刚刚开源!
注1:文末附【医疗影像】学习交流群,小助手会拉你进群!
注2:欢迎点赞,支持分享!
Context Matters: Graph-based Self-supervised Representation Learning for Medical Images


作者单位:匹兹堡大学
代码:https://github.com/batmanlab/Context_Aware_SSL
论文(已收录于AAAI 2021):https://arxiv.org/abs/2012.06457
监督学习方法需要大量带注释的数据集。收集此类数据集既耗时又昂贵。到目前为止,很少有带注释的COVID-19成像数据集。
尽管自监督学习使我们能够通过利用未标记的数据来引导训练,但是用于自然图像的通用自监督方法并未充分融合上下文。对于医学图像,一种理想的方法应该足够灵敏,以检测与每个解剖区域正常出现的组织的偏离;在这里,anatomy is the context。
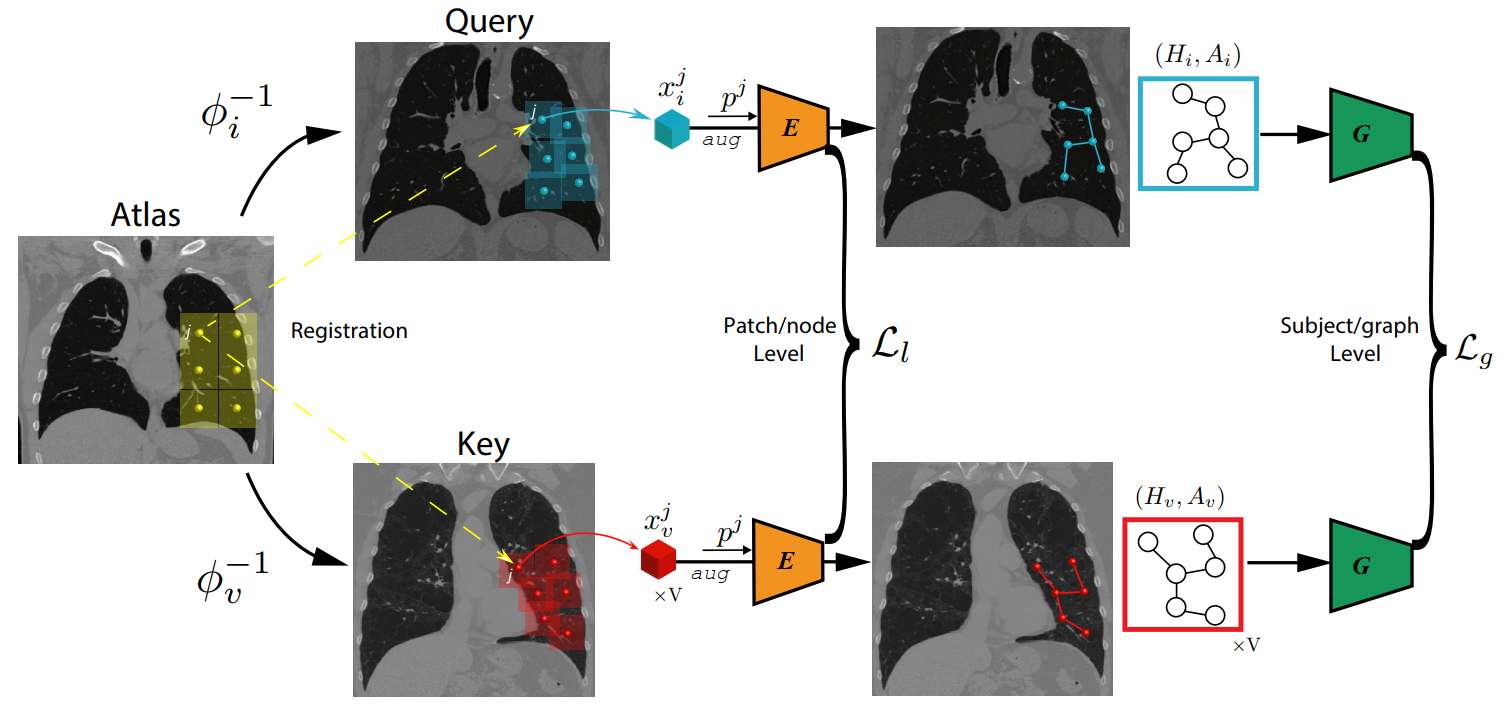
我们介绍了一种具有两个level的自监督的表示学习目标的新颖方法:一个在区域解剖level ,另一个在患者level。我们使用图神经网络来合并不同解剖区域之间的关系。该图的结构由每个患者与解剖图谱之间的解剖对应关系告知。
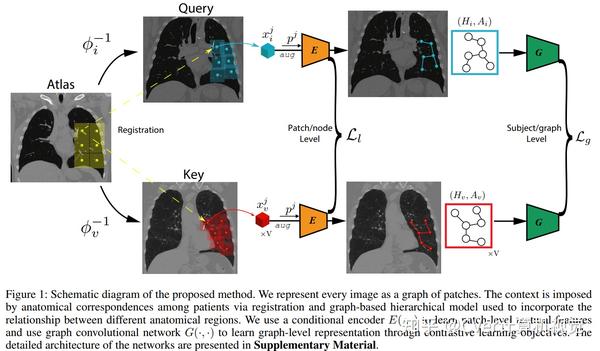



另外,图表示具有以全分辨率处理任何大小的图像的优点。在大型肺部计算机断层扫描(CT)数据集上进行的实验表明,我们的方法与不考虑上下文的基线方法相比具有优势。
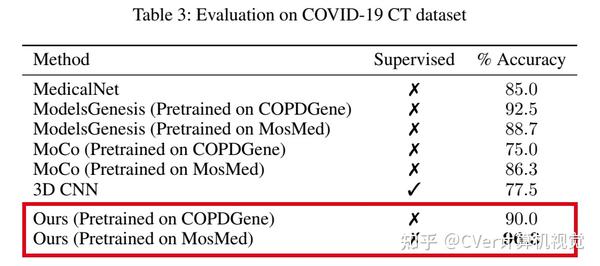
实验结果
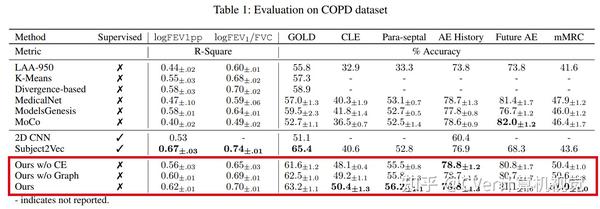
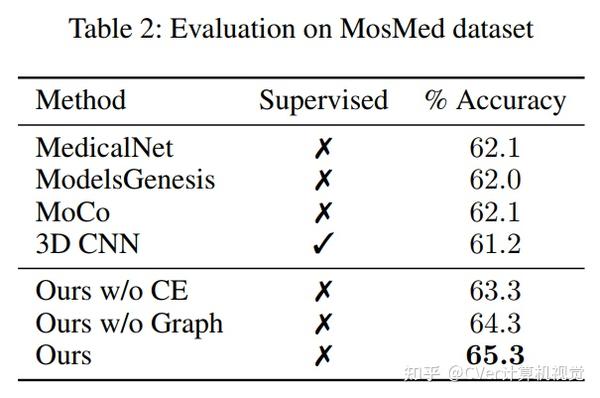
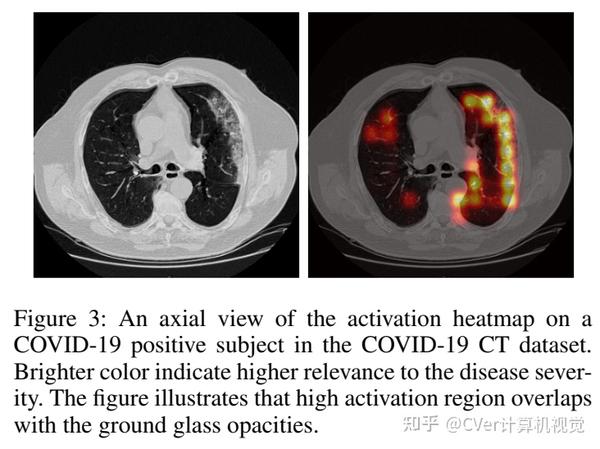
我们使用学习的嵌入来量化COVID-19的临床进展,并表明我们的方法可以很好地泛化到来自不同医院的COVID-19患者。定性结果表明我们的模型可以识别图像中的临床相关区域。




CVer-医疗影像交流群
已建立CVer-医疗影像微信交流群!想要进医疗影像学习交流群的同学,可以直接加微信号:CVer6666。加的时候备注一下:医疗影像+学校+昵称,即可。然后就可以拉你进群了。
推荐阅读
医学图像语义分割最佳方法的全面比较:U-Net和U-Net++
重新标记ImageNet:从单标签到多标签,从全局标签到局部标签
全能涨点!TDAF:用于视觉任务的自上而下的注意力框架 | AAAI 2021
京东AI发布FaceX-Zoo:用于人脸识别的PyTorch工具箱
涨点神器!SoftPool:一种新的池化方法,带你起飞,代码已开源!
超越MoCo v2!上交和华为提出HSA:用于对比表示学习的分层语义聚合缺陷检测比赛Top3方案分享
2020年度arXiv十大热门论文来了!YOLOv4、SimCLR和GPT-3均上榜
Papers with Code 2020 全年回顾(顶流论文+顶流代码+Benchmarks)
基于GAN的图像合成技术:全面调研和案例研究(2014-2020)
涨点神器!IC-Conv:具有高效空洞搜索的Inception卷积
