
Natural Language Processing By Chris Manning And Dan jurafsky 第0篇

接下来我会学习这门课程,这门课已经在coursera上找不到了,但这门课应该算是nlp的经典入门课程了,其实nlp的入门与实践有3大经典课程:
- Natural Language Processing By Chris Manning And Dan jurafsky
- Michael Collins的自然语言处理
- cs224n
由于我不想做书单收集者,所以先一门一门来,第一门课程的视频和资料我已经找到了,作业也有,光看视频,不写代码,其实效率很低。
这3个链接就是作业和讲义,我挑些重点和作业进行展示讲解吧~
中文,英文预处理过程很不一样,




最大逆向匹配分词算法就是属于这一类


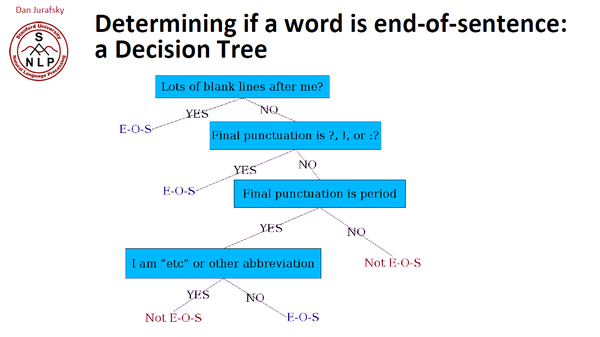







通过决策树来决定句子的结束位置。
前两周我觉得没有什么其它重要的内容了,所以就一笔带过了。接下来进入第3周,开始比较重要了。
最小编辑距离








编辑距离:编辑距离(Edit Distance),又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。一般来说,编辑距离越小,两个串的相似度越大。
当替换的权重是2的时候,变成了Levenshtein,理解了定义,不难得出上面的编辑距离的计算结果。
那么编辑距离有什么用呢?






So, this space of all possible sequences is enormous. So we can't afford to navigate naively in this, in this sequence. And the intuition of solving this problem of lots of possible sequences is some of these paths wind up at the same state. So, we don't have to keep track of every way of transforming one string into another if the second
pieces of the set are identical. All we have to keep is the shortest path to every revisited state. (其实就是不用去进行全局序列对比,只要使用局部序列对比就可以了)




也就是不用每次都去找整个序列的相似部分,而是去找最小子列的相似部分


So let's look at an example of how this works, we are gonna to define minimum edit distance formally as, for two strings. You have string X of length N and string Y of length M. We'll define a distance matrix D(i, j). And that will be the edit distance between the first i characters, one through i, of X and the first j characters, one through j, of string Y. So that's what's in that's what's defined by D(i, j). And so, the distance between the entire two strings is gonna be D(N, M) because the strings are of length N and M. So that's our definition of minimum added distance.
这里讲了一下编辑距离的定义


这里开始讲如何去计算编辑距离,其实就是用表格的方法计算编辑距离,其实这里涉及到动态规划


表格大概是这样画
具体算法如下:


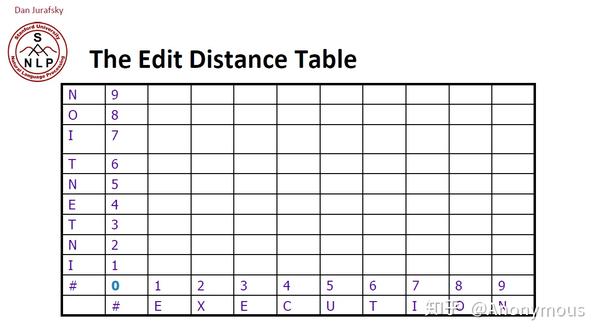

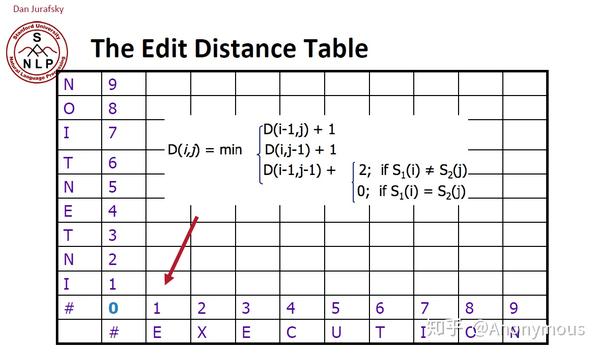


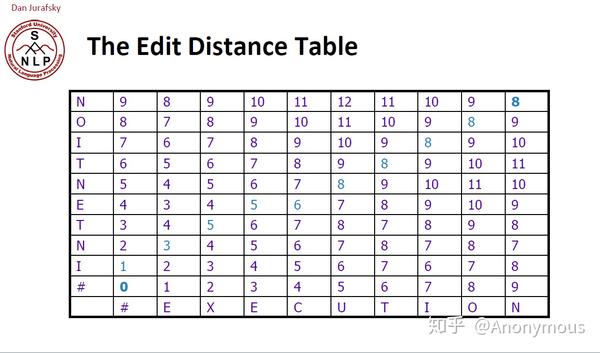

D(1,1) = min({D(0, 1) + 1, D(1, 0) + 1, D(0, 0) + 2}) = 2
一开始看这个表格我有点懵逼,但其实是这样的,先看上面没有结果的图,然后来计算D(1, 1)这个空应该填什么,首先是D(0,1)和D(1,0)的值,都为1,横轴是i, 纵轴是j, D(i, 0), D(0, j)的值就是i和j对应的值。所以D(0,1) = D(1,0) = 1, 那么根据上面的公式,D(1, 1) = D(0, 0) + 2, 那D(0, 0)是为0的,那么S(i=1) = E, S(j=1) = I, 这两个字母是不相等的,所以要加2
再来看一个例子,D(1, 2) = min({D(0, 2) + 1, D(1, 1) + 1, D(0, 1) + 2}) = min({2 + 1, 2 + 1, 1 + 2}) = 3
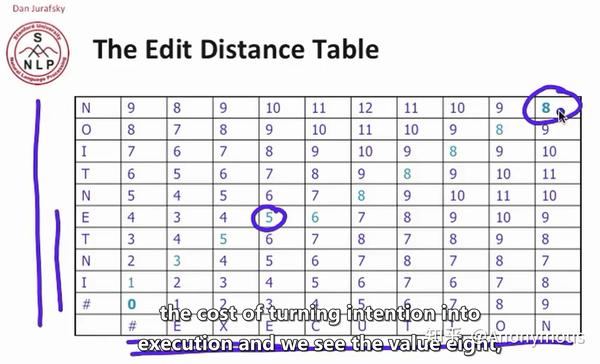

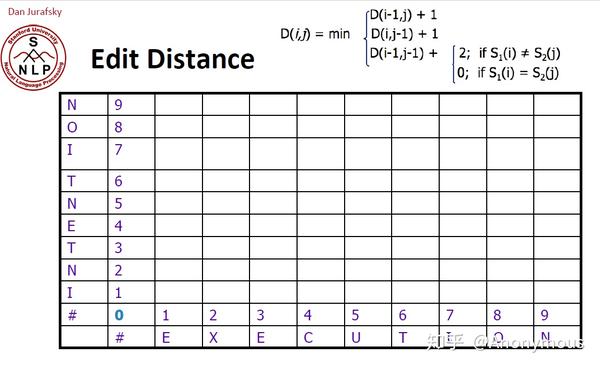
所以将这张表格填充完之后,看这个图里面打圈的地方,5和8,5代表将INTE转换成EXE所需要的编辑距离,那么INTENTION转换成EXECUTION的编辑距离就是8
但是仅仅知道编辑距离是不够的,要能知道回溯的路径
Knowing the edit distance between two strings is important but it turns out not be sufficient, We often need something more which is the alignment between two strings. We wanna know which symbol in string x corresponds to which symbol in string y and this is gonna be important for any application we have, for often from spell checking to machine translation even in computation biology.
就是说要知道两个字符串之间的对应关系,那要想知道对应关系就要记录回溯路径
The way we compute this alignment is we keep a back trace. A back trace is simply a pointer.
也就是回溯路径就是一个指针
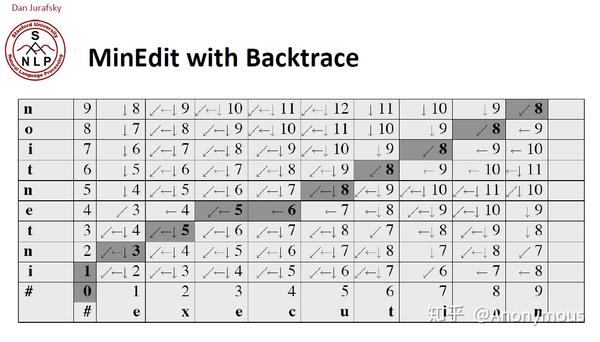

看一下D(1,1), D(1, 2), D(1, 3)这三个空格对应的路径值2, 3, 4是怎么来的,在之前计算2,3,4这3个值时,是来自3个方向,因为3个方向得出来的值都是3


Computing the backtrace very simple. We take our same minimum edit algorithm that we have seen and here I have labelled the cases for you. So when we are looking
at a cell we're deleting, inserting or substituting and we simply add pointers. So in a case where we are inserting we point left and in a case where we are deleting we point down and in a case where I am substituting we point diagonally. I have shown you that arrow on the previous slide.
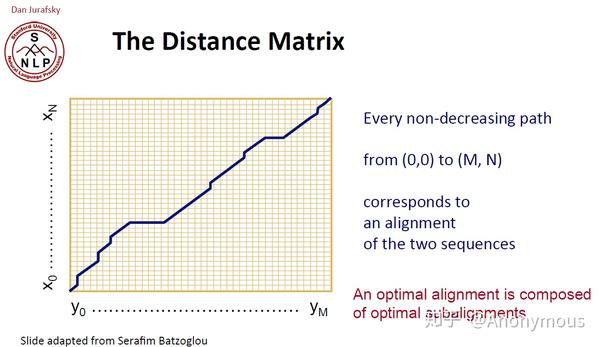

只要不是下降的路径都可以


所以有了回溯以后,就可以把它们对应起来。


接下来看下时间复杂度,空间复杂度,由于是m*n的矩阵,所以时间空间复杂度都为O(nm), 至于Backtrace的最差情况,如果有N deletions, M insertions, 所以就是N plus M.






打字的时候就很容易将某些字母和某些字母混淆,


那么在编辑距离的计算方法里面,deletion的权重为1,insertion的权重为1,substitution的权重为2。那么也就是在计算编辑距离的时候要把这些权重考虑进去。
那在计算生物这个领域,编辑距离也是有应用的。






这里写了自然语言处理和计算生物两个领域的区别


跟之前的算法差不多,只不过d代表插入和删除,s代表替换,不过由于是生物邻域的东西,跟自然语言处理还是有些差别,精力有限,我就不展开了。
这里既然提到了编辑距离,还是想详细说下编辑距离算法的实现,从分治法(递归)和动态规划两个方向上来说,首先题目是这样:
给了2个字符串string1, string2, 找到最小的步数将string1转换成string2, 对于每个字符可以有3种操作:
- 插入一个字符
- 删除一个字符
- 替换一个字符
那么递归思路如下:
所谓递归,便是把大问题”分治“成类似的小问题。
假设,a 的长度是 m,b 的长度是 n,要求 a[1]a[2]...a[m] => b[1]b[2]...b[n] 的最小编辑距离,记为 d[m][n]。
- 如果 a[m] === b[n],那么问题转化为求解:a[1]a[2]...a[m-1] => b[1]b[2]...b[n-1] 的最小编辑距离,因此 d[m][n] === d[m-1][n-1]。比如,"xyz" => "pqz" 的最小编辑距离等于 "xy" => "pq" 的最小编辑距离。
- 如果 a[m] !== b[n],又分为三种情况:
- 比如,"xyz" => "efg" 的最小编辑距离等于 "xy" => "efg" 的最小编辑距离 + 1(因为允许插入操作,插入一个 "z"),抽象的描述便是 d[m][n] === d[m-1][n] + 1。
- 比如,"xyz" => "efg" 的最小编辑距离等于 "xyzg" => "efg" 的最小编辑距离 + 1,且因为最后一个字符都是 "g",根据第一个判断条件,可以再等于 "xyz" => "ef" 的最小编辑距离 + 1,因此,得到结论:"xyz" => "efg" 的最小编辑距离等于 "xyz" => "ef" 的最小编辑距离 + 1,抽象的描述便是:d[m][n] === d[m][n-1] + 1。
- 比如,"xyz" => "efg" 的最小编辑距离等于 "xyg" => "efg" 的最小编辑距离 + 1(因为允许替换操作,可以把 "g" 换成 "z"),再等于 "xy" => "ef" 的编辑距离 + 1(根据第一个判断条件),抽象的描述便是: d[m][n] === d[m-1][n-1] + 1。
- 上述三种情况都有可能出现,因此,取其中的最小值便是整体上的最小编辑距离
3. 如果 a 的长度为 0,那么 a => b 的最小编辑距离为 b 的长度;反过来,如果 b 的长度为0,那么 a => b 的最小编辑距离为 a 的长度。
那么python代码如下:
#! python3
# -*- coding: utf-8 -*-
def edit_distance(a, b, i, j):
"""
:param a: 字符串a
:param b: 字符串b
:param i: 字符串a的长度
:param j: 字符串b的长度
:return:
"""
if i == 0:
return j
elif j == 0:
return i
elif a[i-1] == b[j-1]:
return edit_distance(a, b, i-1, j-1)
elif a[i-1] != b[j-1]:
condition_0 = edit_distance(a, b, i-1, j) + 1
condition_1 = edit_distance(a, b, i, j-1) + 1
condition_2 = edit_distance(a, b, i-1, j-1) + 1
return min([condition_0, condition_1, condition_2])
elif i == 0 and j == 0:
return 0
def main():
"""
测试数据
:return:
"""
res = edit_distance('abc', 'abc', 3, 3)
print(res)
if __name__ == '__main__':
main()接下来就是用动态递归去解决编辑距离,只不过动态递归的逻辑和递归的逻辑是反的,递归的逻辑是:“要求得 d[m][n],先要求得 d[m-1][n-1]……”,动态规划的逻辑是:“先求得 d[m-1][n-1],再求 d[m][n]……”这是它们的主要区别。举个例子,在已知 d[0][0],d[0][1],d[1][0] 的前提下,要求 d[1][1]:
- 如果 a[1] === b[1],那么 d[1][1] 等于 d[0][0],也就是 0;
- 如果 a[1] !== b[1],那么 d[1][1] 等于 d[0][1]、d[1][0] 和 d[0][0] 三者中的最小值 + 1,也就是 1。
接着用同样的方式,可以求得 d[1][2]、d[1][3]、……、d[1][n],然后继续求得 d[2][1]、d[2][2]、……、d[2][n],一直到 d[m][n]。




代码如下,用numpy去建立数组:
def dynamic_edit_distance(a, b):
"""
:param a: 字符串a
:param b: 字符串b
:return:
"""
a_length = len(a)
b_length = len(b)
x = np.zeros(shape=(a_length+1, b_length+1), dtype='int32')
print(x)
print(type(x))
for i in range(a_length+1):
x[i][0] = i
for j in range(b_length+1):
x[0][j] = j
print(x)
for i in range(1, a_length+1):
for j in range(1, b_length+1):
if a[i-1] == b[j-1]:
x[i][j] = x[i-1][j-1]
else:
x[i][j] = min([x[i-1][j]+1, x[i][j-1]+1, x[i-1][j-1]+1])
return x[a_length][b_length]其实这是我第一次接触动态规划:
深入研究看一下这篇文章吧
第一份作业,上来就是头疼的正则表达式,提取电子邮件和电话号码,本来不想写了,算了,既然开始学这门课了,就还是认真完成吧,题目要求我翻译一下:
ashishg e ashishg@stanford.edu
ashishg e rozm@stanford.edu
ashishg p 650-723-1614
ashishg p 650-723-4173
ashishg p 650-814-1478
balaji e balaji@stanford.edu
bgirod p 650-723-4539
bgirod p 650-724-3648
bgirod p 650-724-6354
cheriton e cheriton@cs.stanford.edu
cheriton e uma@cs.stanford.edu
cheriton p 650-723-1131
cheriton p 650-725-3726
dabo e dabo@cs.stanford.edu
dabo p 650-725-3897
dabo p 650-725-4671
dlwh e dlwh@stanford.edu
engler e engler@lcs.mit.edu
engler e engler@stanford.edu
eroberts e eroberts@cs.stanford.edu
eroberts p 650-723-3642
eroberts p 650-723-6092
fedkiw e fedkiw@cs.stanford.edu
hager e hager@cs.jhu.edu
hager p 410-516-5521
hager p 410-516-5553
hager p 410-516-8000
hanrahan e hanrahan@cs.stanford.edu
hanrahan p 650-723-0033
hanrahan p 650-723-8530
horowitz p 650-725-3707
horowitz p 650-725-6949
jks e jks@robotics.stanford.edu
jurafsky e jurafsky@stanford.edu
jurafsky p 650-723-5666
kosecka e kosecka@cs.gmu.edu
kosecka p 703-993-1710
kosecka p 703-993-1876
kunle e darlene@csl.stanford.edu
kunle e kunle@ogun.stanford.edu
kunle p 650-723-1430
kunle p 650-725-3713
kunle p 650-725-6949
lam e lam@cs.stanford.edu
lam p 650-725-3714
lam p 650-725-6949
latombe e asandra@cs.stanford.edu
latombe e latombe@cs.stanford.edu
latombe e liliana@cs.stanford.edu
latombe p 650-721-6625
latombe p 650-723-0350
latombe p 650-723-4137
latombe p 650-725-1449
levoy e ada@graphics.stanford.edu
levoy e melissa@graphics.stanford.edu
levoy p 650-723-0033
levoy p 650-724-6865
levoy p 650-725-3724
levoy p 650-725-4089
manning e dbarros@cs.stanford.edu
manning e manning@cs.stanford.edu
manning p 650-723-7683
manning p 650-725-1449
manning p 650-725-3358
nass e nass@stanford.edu
nass p 650-723-5499
nass p 650-725-2472
nick e nick.parlante@cs.stanford.edu
nick p 650-725-4727
ok p 650-723-9753
ok p 650-725-1449
ouster e teresa.lynn@stanford.edu
ouster e ouster@cs.stanford.edu
pal e pal@cs.stanford.edu
pal p 650-725-9046
psyoung e patrick.young@stanford.edu
rajeev p 650-723-4377
rajeev p 650-723-6045
rajeev p 650-725-4671
rinard e rinard@lcs.mit.edu
rinard p 617-253-1221
rinard p 617-258-6922
serafim e serafim@cs.stanford.edu
serafim p 650-723-3334
serafim p 650-725-1449
shoham e shoham@stanford.edu
shoham p 650-723-3432
shoham p 650-725-1449
subh e subh@stanford.edu
subh e uma@cs.stanford.edu
subh p 650-724-1915
subh p 650-725-3726
subh p 650-725-6949
thm e pkrokel@stanford.edu
thm p 650-725-3383
thm p 650-725-3636
thm p 650-725-3938
tim p 650-724-9147
tim p 650-725-2340
tim p 650-725-4671
ullman e support@gradiance.com
ullman e ullman@cs.stanford.edu
ullman p 650-494-8016
ullman p 650-725-2588
ullman p 650-725-4802
vladlen e vladlen@stanford.edu
widom e siroker@cs.stanford.edu
widom e widom@cs.stanford.edu
widom p 650-723-0872
widom p 650-723-7690
widom p 650-725-2588
zelenski e zelenski@cs.stanford.edu
zelenski p 650-723-6092
zelenski p 650-725-8596
zm e manna@cs.stanford.edu
zm p 650-723-4364
zm p 650-725-4671这是给定的最终结果,第一列是文件名,第二列是类别,e代表email, p代表号码,第三列是正则提取的结果。




上面这些目录就是包含文本的文件,所以任务就是利用正则将文本全部按照给定的结果给抽取出来。作业版本是python2, 根据写的正则表达式会去计算True Positives, False Positives, False Negatives这些值。这里介绍一下机器学习里的True Positive, True Negative, False Positive, False Negative这四个概率,以及衍生的计算公式。
对于二分类问题常用的评价指标是精准率(precision)和召回率(recall),分类器在测试数据集上的预测或正确或不正确,4种情况出现的总数分别记作:
- TP: 将正类预测为正类数;
- FN: 将正类预测为负类数;
- FP: 将负类预测为正数类;
- TN: 将负类预测为负数类;
精准率定义为:
P = \frac{TP}{TP + FP}
召回率定义为:
R = \frac{TP}{TP+FN}
此外,还有 F_1 值,是精准率和召回率的调和均值,即
\frac{2}{F} = \frac{1}{P} + \frac{1}{R}
精准率和召回率都高时, F_1 值也会高。
这些概念还是挺常见的,在这里主要是有提到一下,作业里的目标是这样的,Your goal, then, is to reduce the number of false positives and negatives to zero.
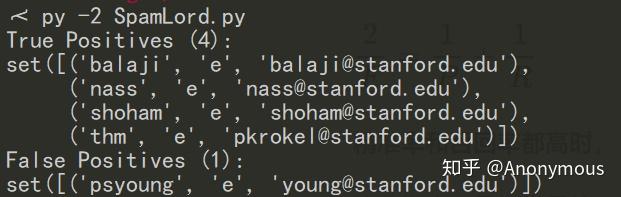

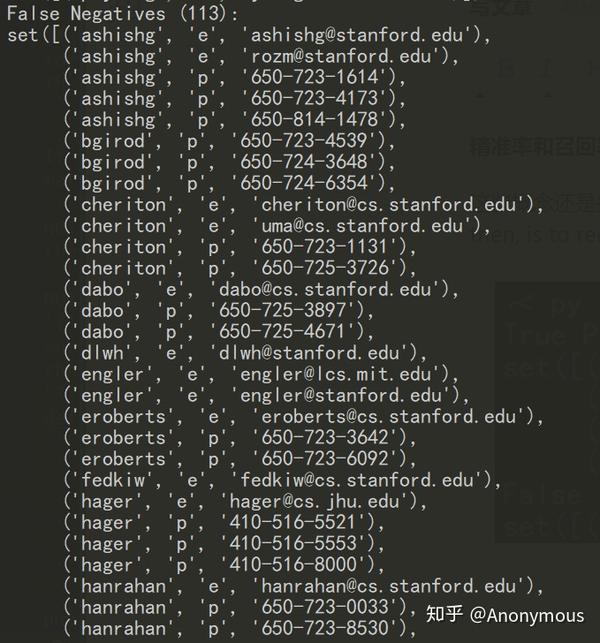

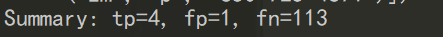

它这里显示的初始结果是这样,最终目标就是将false positives和false negatives的数量减为零
#! python2
# -*- coding: utf-8 -*-
import sys
import os
import re
import pprint
# my_first_pat = '(\w+)@(\w+).edu'
# email_pat = '(\w+)@(\w+).edu|(\w+)@(\w+)\.(\w+).edu|(\w+)@(\w+)\.(\w+).edu|(\w+)\.(\w+)@(\w+)\.(\w+).edu|(\w+)\.(\w+)@(\w+).edu|(\w+)@(\w+)\.(\w+).edu'
# email_pat = '(?=(\w+)@(\w+).edu)(?=(\w+)@(\w+)\.(\w+).edu)(?=(\w+)\.(\w+)@(\w+)\.(\w+).edu)(?=(\w+)\.(\w+)@(\w+).edu)(?=(\w+)@(\w+)\.(\w+).edu)'
# email_pat_0 = '(\w+)@(\w+).edu'
# email_pat_1 = '(\w+)@(\w+)\.(\w+).edu'
# email_pat_2 = '(\w+)\.(\w+)@(\w+)\.(\w+).edu'
# email_pat_3 = '(\w+)\.(\w+)@(\w+).edu'
# email_pat_4 = '(\w+)@(\w+)\.(\w+).edu'
# phone_pat = '\d{3}-\d{3}-\d{4}'
my_email_pattern = r'''
# pattern for email
(([\w-]+|[\w-]+\.[\w-]+) # hanks, justin.hanks, hanks-, justin-hanks-
(\s.?\(f.*y.*)? # followed by
(\s?(@|&.*;)\s?|\s(at|where)\s) # @, @ , at , where ,@,
([\w-]+|[\w-]+([\.;]|\sdo?t\s|\s)[\w-]+) # gmail., ics.bjtu, ics;bjtu, ics dot bjtu, -ics-bjtu-
([\.;]|\s(do?t|DOM)\s|\s) # ., ;, dot , dt , DOM
(-?e-?d-?u|com)\b) # .edu, .com, -e-d-u
|
(obfuscate\('(\w+\.edu)','(\w+)'\)) # obfuscate('stanford.edu','jurafsky')
'''
my_phone_pattern = r'''
# pattern for phone
\(?(\d{3})\)? # area code is 3 digits, e.g. (650), 650
[ -]? # separator is - or space or nothing, e.g. 650-XXX, 650 XXX, (650)XXX
(\d{3}) # trunk is 3 digits, e.g. 800
[ -] # separator is - or space
(\d{4}) # rest of number is 4 digits, e.g. 0987
\D+ # should have at least one non digit character at the end
'''
"""
TODO
This function takes in a filename along with the file object (actually
a StringIO object at submission time) and
scans its contents against regex patterns. It returns a list of
(filename, type, value) tuples where type is either an 'e' or a 'p'
for e-mail or phone, and value is the formatted phone number or e-mail.
The canonical formats are:
(name, 'p', '###-###-#####')
(name, 'e', 'someone@something')
If the numbers you submit are formatted differently they will not
match the gold answers
NOTE: ***don't change this interface***, as it will be called directly by
the submit script
NOTE: You shouldn't need to worry about this, but just so you know, the
'f' parameter below will be of type StringIO at submission time. So, make
sure you check the StringIO interface if you do anything really tricky,
though StringIO should support most everything.
"""
# def process_file(name, f):
# # note that debug info should be printed to stderr
# # sys.stderr.write('[process_file]\tprocessing file: %s\n' % (path))
#
# res = []
# for line in f:
# email_matches_0 = re.findall(email_pat_0, line)
# email_matches_1 = re.findall(email_pat_1, line)
# email_matches_2 = re.findall(email_pat_2, line)
# email_matches_3 = re.findall(email_pat_3, line)
# email_matches_4 = re.findall(email_pat_4, line)
# # email = None
# for m in email_matches_0:
# email = '%s@%s.edu' % m
# res.append((name, 'e', email))
# for m in email_matches_1:
# email = '%s@%s.%s.edu' % m
# res.append((name, 'e', email))
# for m in email_matches_2:
# email = '%s.%s@%s.%s.edu' % m
# res.append((name, 'e', email))
# for m in email_matches_3:
# email = '%s.%s@%s.edu' % m
# res.append((name, 'e', email))
# for m in email_matches_4:
# email = '%s@%s.%s.edu' % m
# res.append((name, 'e', email))
# # res.append((name, 'e', email))
#
# phone_matches = re.findall(phone_pat, line)
# for m in phone_matches:
# res.append((name, 'p', m))
# return res
def process_file(name, f):
# note that debug info should be printed to stderr
# sys.stderr.write('[process_file]\tprocessing file: %s\n' % (path))
res = []
for line in f:
# match email
matches = re.findall(my_email_pattern, line, re.VERBOSE | re.I)
for m in matches:
email = ""
if len(m[-1]) != 0:
email = '%s@%s' % (m[-1], m[-2])
else:
if m[1] == "Server":
# skip "server at" sentence
continue
email = '%s@%s.%s' % (m[1].replace("-", ""),
m[6].replace(";", ".")
.replace(" dot ", ".")
.replace("-", "")
.replace(" ", "."),
m[-4].replace("-", ""))
res.append((name, 'e', email))
# match phone number
matches = re.findall(my_phone_pattern, line, re.VERBOSE)
for m in matches:
phone = '%s-%s-%s' % m
res.append((name, 'p', phone))
return res
"""
You should not need to edit this function, nor should you alter
its interface as it will be called directly by the submit script
"""
def process_dir(data_path):
# get candidates
guess_list = []
for fname in os.listdir(data_path):
if fname[0] == '.':
continue
path = os.path.join(data_path,fname)
f = open(path,'r')
f_guesses = process_file(fname, f)
guess_list.extend(f_guesses)
return guess_list
"""
You should not need to edit this function.
Given a path to a tsv file of gold e-mails and phone numbers
this function returns a list of tuples of the canonical form:
(filename, type, value)
"""
def get_gold(gold_path):
# get gold answers
gold_list = []
f_gold = open(gold_path,'r')
for line in f_gold:
gold_list.append(tuple(line.strip().split('\t')))
return gold_list
"""
You should not need to edit this function.
Given a list of guessed contacts and gold contacts, this function
computes the intersection and set differences, to compute the true
positives, false positives and false negatives. Importantly, it
converts all of the values to lower case before comparing
"""
def score(guess_list, gold_list):
guess_list = [(fname, _type, value.lower()) for (fname, _type, value) in guess_list]
gold_list = [(fname, _type, value.lower()) for (fname, _type, value) in gold_list]
guess_set = set(guess_list)
gold_set = set(gold_list)
tp = guess_set.intersection(gold_set)
fp = guess_set - gold_set
fn = gold_set - guess_set
pp = pprint.PrettyPrinter()
#print 'Guesses (%d): ' % len(guess_set)
#pp.pprint(guess_set)
#print 'Gold (%d): ' % len(gold_set)
#pp.pprint(gold_set)
print('True Positives (%d): ' % len(tp))
pp.pprint(tp)
print('False Positives (%d): ' % len(fp))
pp.pprint(fp)
print('False Negatives (%d): ' % len(fn))
pp.pprint(fn)
print('Summary: tp=%d, fp=%d, fn=%d' % (len(tp), len(fp), len(fn)))
"""
You should not need to edit this function.
It takes in the string path to the data directory and the
gold file
"""
def main(data_path, gold_path):
guess_list = process_dir(data_path)
gold_list = get_gold(gold_path)
score(guess_list, gold_list)
"""
commandline interface takes a directory name and gold file.
It then processes each file within that directory and extracts any
matching e-mails or phone numbers and compares them to the gold file
"""
if __name__ == '__main__':
if len(sys.argv) == 1:
# 当没有加参数的时候 python SpamLord.py
main('../data/dev', '../data/devGOLD')
elif len(sys.argv) == 3:
# 当加了两个参数的时候 python SpamLord.py dev devGOLD
main(sys.argv[1], sys.argv[2])
else:
print('usage:\tSpamLord.py <data_dir> <gold_file>')
sys.exit(0)
。。。最后还是看了一下别人的答案,我是老实人,一直写不到完全正确。。。
