
【论文笔记】node2vec

论文名称:node2vec: Scalable Feature Learning for Networks
node2vec的思想同DeepWalk一样:生成随机游走,对随机游走采样得到(节点,上下文)的组合,然后用处理词向量的方法对这样的组合建模得到网络节点的表示。不过在生成随机游走过程中做了一些创新。
Introduction
首先介绍了复杂网络面对的几种任务,一种是网络节点的分类,通俗点说就是将网络中的节点进行聚类,我们关心的是哪些节点具有类似的属性,就将其分到同一个类别中。另一种是链接预测,就是预测网络中哪些顶点有潜在的关联。
要完成这些任务首先要解决的问题就是网络嵌入,以前的手工提取特征的方式有着诸多不足。一种替代的提取网络特征的方法是通过解优化函数的方式学习网络的表示特征。但是这样的方法面临一个计算效率和准确度的平衡问题,无法兼顾两者。通过将一些传统的降维方法如PCA应用到网络表示中也确实有一定的效果,缺点是会涉及矩阵分解,运算量大,同时准确率也不高,而且有些方法只是针对特定的任务才有效果。
能否设计出又能保持节点邻居信息而且又容易训练的模型呢?这就是本文尝试解决的工作。我们发现很多节点在网络中往往有一些类似的结构特征。一种结构特征是很多节点会聚集在一起,内部的连接远比外部的连接多,我们称之为社区。另一种结构特征是网络中两个可能相聚很远的点,在边的连接上有着类似的特征。比如下图, {u,s_1,s_2,s_3,s_4} 就属于一个社区,而 u,s_6 在结构上有着相似的特征。
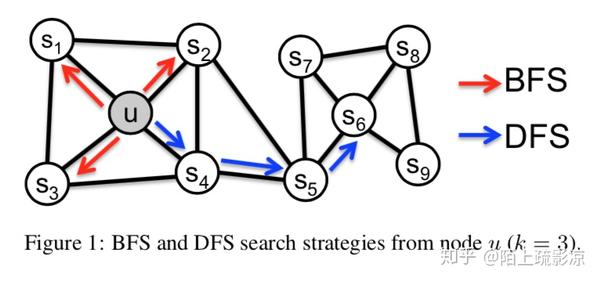

那么要设计的网络表示学习算法的目标必须满足这两点:
- 同一个社区内的节点表示相似。
- 拥有类似结构特征的节点表示相似。
然后就是日常吹一下本文的工作了,总之本文的贡献就是:提出了一个有效的、可扩展的表示学习算法,可以体现网络特征和节点邻居特征。
Related Works
之前的工作存在着一些问题:
- 特征需要依赖人手工定义,不是某个领域内专业人士无法从事工作,而且依靠人手工定义特征这件事本身就很悬,就算是领域专家也不能肯定某个提取出来的特征就一定管用,所以这种方法就很玄学了。
- 一些非监督学习中的降维方法被拿来使用,但是这些方法计算效率低,准确度也不够,而且还不能反应出网络的结构特征。
最近(当时是最近)在NLP中的方法为本文的作者提供了思路,其实跟DeepWalk的想法是一样的。用skip-gram模型来解决网络表示学习的问题。
Algorithm
一些基本图的定义,网络映射到向量的形式化定义就不提了,基本上一眼就能看懂的。直接上损失函数,其实跟DeepWalk也是一样的,只不过换了种表达而已。
\max \limits_{f} \sum_{u∈V}logPr(N_s(u)|f(u))
其中 f(u) 就是当前节点, N_s(u) 就是邻居节点(以s的方法采样得到的),为了让这个结果更容易计算,引入了两个假设,其实这都是skip-gram模型中的。
第一个假设是条件独立(Conditional independence),即采样每个邻居是相互独立的,所以如果要计算采样所有邻居的概率只需要将采样每个邻居的概率相乘就行了,公式化表达就是:
Pr(N_s(u)|f(u))=\prod_{n_i∈N_s(u)}Pr(n_i|f(u))
第二个假设是特征空间的对称性(Symmetry in feature space),其实也很好理解,比如一条边连接了a和b,那么映射到特征空间时,a对b的影响和b对a的影响应该是一样的。用一个模型来表示一个(节点,邻居)对:
Pr(n_i|f(u)) = \frac{exp(f(n_i)·f(u))}{\sum_{v∈V}exp(f(v)·f(u))}
将上面三个公式结合起来得到最终要优化的结果:
\max \limits_{f} \sum_{u∈V}[-logZ_u + \sum_{n_i∈N_s(u)}f(n_i)·f(u)]
推导过程如下:
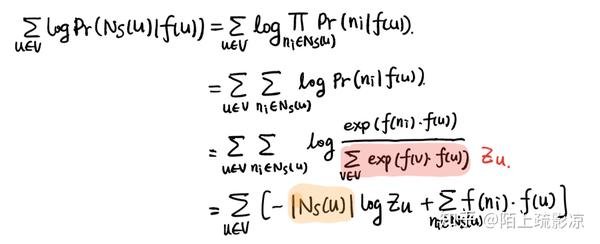

如果我的推导没错的话,推导完后其实是有一个 |N_s(u)| 的系数的(图中橙色部分),但是这部分没有在最终的损失和函数中。可能是因为整个这一项 |N_s(u)|logZ_u 都是常数的原因。
注意两点:
- Z_u 直接计算特别费时,本文用Negative Sampling方法解决的。
- N_s(u) 未必是u的直接邻居,只是用s方法采样得到的邻居,跟具体的采样方法有关。
到这里之前这些公式基本都是NLP中处理词向量那块的,现在让我们把目光放到node2vec中的创新内容。
说到随机游走的采样,本文分析了两种图的游走方式,深度优先游走(Depth-first Sampling,DFS)和广度优先游走(Breadth-first Sampling,BFS),之前的图中也画出了两种游走的路径,学过图论或者数据结构的很好理解。游走的路径就是采样后得到的随机游走。
复杂网络处理的任务其实离不开两种特性,前面也提到过:一种是同质性,就是之前所说的社区。一种就是结构相似性,值得注意的是,结构相似的两个点未必相连,可以是相距很远的两个节点。
BFS倾向于在初始节点的周围游走,可以反映出一个节点的邻居的微观特性;而DFS一般会跑的离初始节点越来越远,可以反映出一个节点邻居的宏观特性。
铺垫了这么多终于到本文的工作了,能不能改进DeepWalk中随机游走的方式,使它综合DFS和BFS的特性呢?所以本文引入了两个参数用来控制随机游走产生的方式。
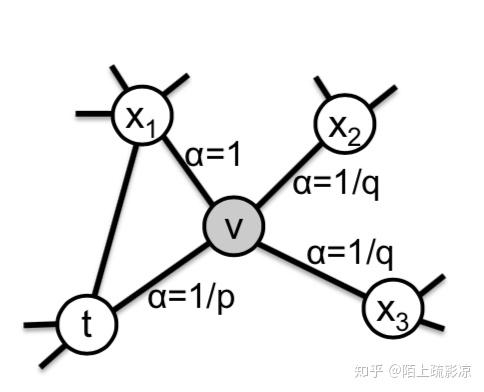

上图中,对于一个随机游走,如果已经采样了 (t,v) ,也就是说现在停留在节点v上,那么下一个要采样的节点x是哪个?作者定义了一个概率分布,也就是一个节点到它的不同邻居的转移概率:
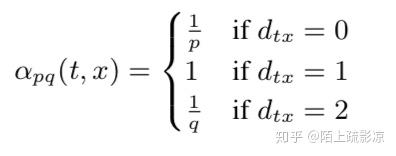
直观的解释一下这个分布:
- 如果t与x相等,那么采样x的概率为 \frac{1}{p} ;
- 如果t与x相连,那么采样x的概率1;
- 如果t与x不相连,那么采样x概率为 \frac{1}{q} 。
参数p、q的意义分别如下:
返回概率p:
- 如果 p>max(q,1) ,那么采样会尽量不往回走,对应上图的情况,就是下一个节点不太可能是上一个访问的节点t。
- 如果 p<min(q,1) ,那么采样会更倾向于返回上一个节点,这样就会一直在起始点周围某些节点来回转来转去。
出入参数q:
- 如果 q>1 ,那么游走会倾向于在起始点周围的节点之间跑,可以反映出一个节点的BFS特性。
- 如果 q<1 ,那么游走会倾向于往远处跑,反映出DFS特性。
当p=1,q=1时,游走方式就等同于DeepWalk中的随机游走。
下面来逐行看看论文中提供的算法:


首先看一下算法的参数,图G、表示向量维度d、每个节点生成的游走个数r,游走长度l,上下文的窗口长度k,以及之前提到的p、q参数。
- 根据p、q和之前的公式计算一个节点到它的邻居的转移概率。
- 将这个转移概率加到图G中形成G'。
- walks用来存储随机游走,先初始化为空。
- 外循环r次表示每个节点作为初始节点要生成r个随机游走。
- 然后对图中每个节点。
- 生成一条随机游走walk。
- 将walk添加到walks中保存。
- 然后用SGD的方法对walks进行训练。
第6步中一条walk的生成方式如下:
- 将初始节点u添加进去。
- walk的长度为l,因此还要再循环添加l-1个节点。
- 当前节点设为walk最后添加的节点。
- 找出当前节点的所有邻居节点。
- 根据转移概率采样选择某个邻居s。
- 将该邻居添加到walk中。
Experiments
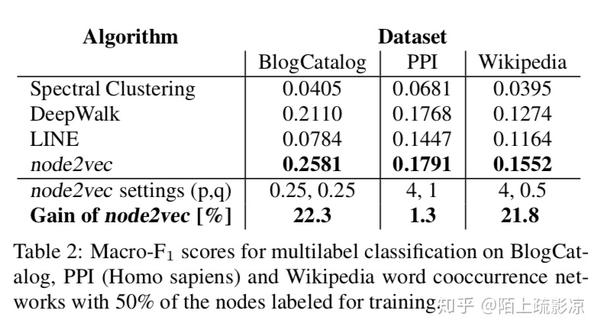
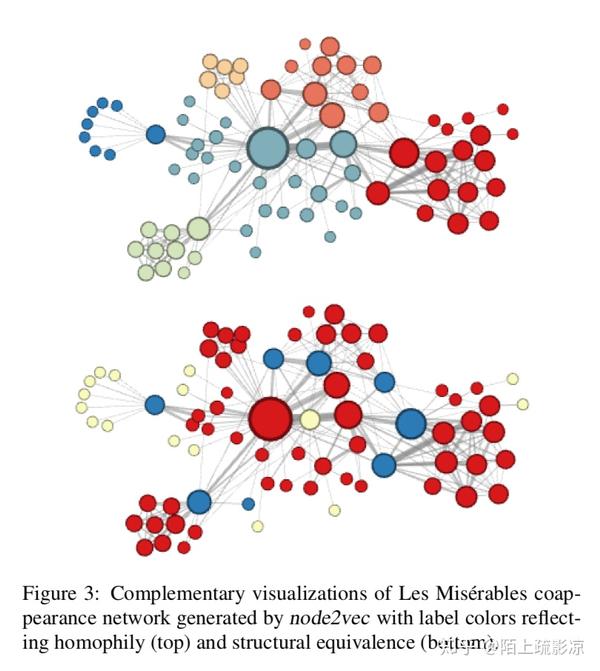
下图是一些实验结果和可视化效果:


总结
本文其实思想跟DeepWalk是一样的,不过改进了DeepWalk中随机游走的生成方式,使得生成的随机游走可以反映深度优先和广度优先两种采样的特性,从而提高网络嵌入的效果。
