【知识图谱】ConMask算法详解

前言
VoidOc:【知识图谱】知识图谱(二)—— 知识抽取与知识挖掘
VoidOc:【知识图谱】知识图谱(三)—— 知识推理算法总结
一、介绍
论文:https://arxiv.org/pdf/1711.03438.pdf
代码仓:bxshi/ConMask
通过利用知识库中已存在的实体和关系进行知识图谱补全, 我们定义为“Closed-World KGC”即 “封闭世界知识图谱补全”:此类知识图谱补全方法严重依赖现有知识图谱连接,难以处理知识图谱外部加入的新实体。为了能够应对知识图谱外部的未知新实体, Shi 等人于2018年《Open world Knowledge Graph Completion》论文中进一步定义了“开放世界知识图谱补全”,该类方法可以接收知识库外部实体并将其链接到知识图谱。基于上述思想提出 ConMask 模型,下面来详解一下这个模型。
首先我们来做两个定义
- 封闭世界知识图谱补全任务 Closed-word KGC task
给定一个需要补全的知识图谱G=(E,R,T), 其中E为图谱中所有实体(Entity)的集合,R为图谱中所有关系(Relationship)的集合,T为图谱中所有RDF三元组(h,r,t)的集合;封闭世界知识图谱补全任务则是通过找到一组缺失的三元组 T'={(h,r,t)|h\in E, r\in R, t\in E, (h,r,t)\notin T } 来完成对G的补全。
也就是说,封闭世界知识图谱补全任务无法引入原图谱中不存在的实体,只能是"发现"原来不存在的三元组。
- 开放世界知识图谱补全任务 Open-word KGC task
给定一个需要补全的知识图谱G=(E,R,T), 其中E为图谱中所有实体(Entity)的集合,R为图谱中所有关系(Relationship)的集合,T为图谱中所有RDF三元组(h,r,t)的集合;开放世界知识图谱补全任务则是通过找到一组缺失的三元组 T'={(h,r,t)|(h,r,t)\notin T, h \in E^{i}, t \in E^{i}, r \in R } 来完成对G的补全, 其中 E^{i} 是E的超集(superset)。
也就是说,开放世界知识图谱补全任务可以引入原图谱中不存在的实体,那么这与一般的三元组信息抽取任务有什么区别呢?论文里说:
1)开放世界KGC的目标不是从大型文本语料库中提取三元组,而是发现缺失的关系;
?这里我个人有个疑问,既然ConMask不能发现新的关系,那不就是基于给定关系的三元组信息抽取吗?
二、ConMask模型
举个例子,给定语料”... Ameen Sayani was introduced to All India Radio, Bombay, by his brother Hamid Sayani. Ameen participated in English programmes there for ten years ...”让你补全(Ameen Sayani , residence,?)这个三元组,其中Ameen Sayani 从未在图谱中出现过。
如果一个人类来回答此问题,正常的推理逻辑可能是首先注意到Ameen Sayani 是一位受欢迎的电台名人->她工作的电台位于孟买(Bombay)->孟买最近更名为Mumbai,所以可能的答案是Mumbai。
同理,ConMask模型也将推理过程分为以下几个步骤:
1)定位与任务相关的信息,基于关系的内容遮蔽(Relationship-dependent content masking):筛选文本信息,删去无关信息,仅留下与任务有关的内容,其中模型采用attention机制基于相似度得到上下文的词和给定关系的词的权重矩阵,通过观察发现目标实体有时候在权重高的词(indicator words)附近,提出 MCRW (Maximal Context-Relationship Weight)考虑了上下文的权重求解方法。
在开放世界KGC中,我们不能仅依靠KG的拓扑来指导我们的模型。相反,我们更需要考虑如何从文本中提取有用的信息来帮助模型做判断。在一个(h,r,?)或(?,r,t)任务中,MCRW的目标就是预处理输入文本,以便根据给定的关系选择小的相关文本片段,从而mask掉不相关的文本。具体如何选择与给定关系最相关的单词呢?则是通过为给定实体描述中的单词分配基于关系的相似性分数来屏蔽不相关的单词。我们将基于关系的内容掩码定义为:


MWRW就是通过计算 \phi(e) 中每个词和 \psi(r) 中每个关系之间的相似性分数而得到的,公式如下:


然而有时候MWRW分最高的词不一定是目标实体,而是与给定关系语义上最近的的词汇;如下图所示当给定三元组(Michelle Obama, spouse,?)推理任务时,married因为语义上与给定关系spouse最接近,MWRW得分最高,但不是正确答案。所以为了改进这一点,作者提出了MCRW(Maximal Context-Relationship Weight),并且将MWRW找到的词定义为“Indicator Word”作为跳板,通过加权一层最大池化来发现最终目标实体。


MCRW函数定义如下:


2)目标融合(Target fusion):使用全卷积神经网络从相关文本抽取目标实体的embedding(用FCN即全卷积神经网络的方法);这个部分输入是masked content matrix,每层先有两个 1-D 卷积操作,再是sigmoid激活函数,然后是 batch normalization,再是最大池化。FCN的最后一层接的是均值池化而不是最大池化,以确保目标融合层的输出始终返回单个k维嵌入。
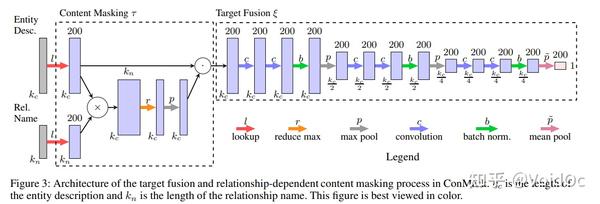

3)目标实体解析(Target entity resolution):生成候选实体和抽取实体嵌入之间的相似度排名,通过计算KG中候选实体和抽取实体embedding的相似度,结合其他文本特征得到一个ranked list,rank最高的认为是最佳结果。为了加快训练速度,我们设计了一个list-wise ranking的损失函数,该函数具有正负目标采样,在采样时按50%的比例替换head和tail生成负样本以增强模型鲁棒性。Loss函数定义如下:


当pc>0.5时,我们保留输入的尾部实体t,并对头部实体h进行正负采样;当pc<=0.5时,我们保留头部实体h,并对尾部实体t进行采样。
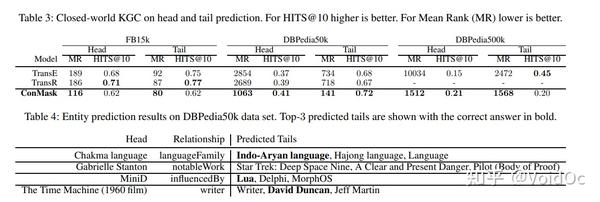
三、实验结果