
基于空间对齐的图卷积网络

Learning Aligned-Spatial Graph Convolutional Networks for Graph Classification
论文来源:ECML-PKDD 2019
论文原作者:Lu Bai, Yuhang Jiao, Lixin Cui, and Edwin R. Hancock
引言
目前大部分GCN方法可以被归为两类:Spectral(基于频域)卷积和Spatial(基于空域)卷积。前者主要基于Spectral Graph Theory将图信号变换到谱域与滤波器系数进行相乘再做逆变换[1, 2],这种方法处理的图结构常常是固定大小的(节点个数固定)并且主要解决的是节点分类问题。然而现实中图数据的大小往往不固定,例如生物信息数据中的蛋白质结构、社交网络中的用户关系等,基于Spatial策略的图卷积操作可以直接定义在邻居节点上,通过采样或排序的方式将邻居节点聚合从而学习图的拓扑特征。尽管如此,Spatial策略的GCN在将卷积层学习到的不同大小图的多尺度特征输入给分类器之前仍要将其转换为固定大小表示,常见的方法就是将图的各节点特征进行加和池化得到图的全局特征,这会造成图局部特征信息的损失,因此这类Spatial策略的GCN方法在图分类上具有相对较差的性能。
这篇论文提出了一种空间对齐(Aligned-Spatial)图卷积网络ASGCN,用于解决图分类问题,将任意大小的图通过传递的对齐方法(Transitive Alignment)转化为固定大小的图结构,并定义了一个与之相关的图卷积运算方式。ASGCN不仅减少了局部信息的损失,还可以自适应指定不同邻居节点在信息聚合中的重要性,因此在很多图分类数据集上都展现出了很好的分类性能。
任意大小图的传递对齐
论文提出一种图匹配方法用于节点的传递对齐,算法框架分3步,如图1所示。
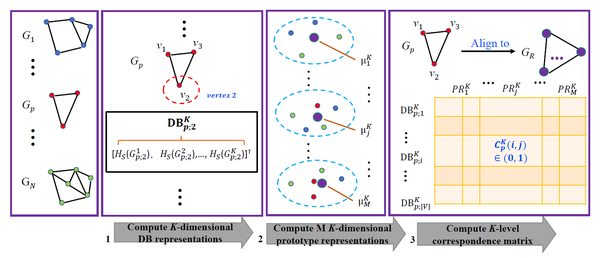

假设数据集所有图共包含n个节点,算法框架第1步:使用一种Node Embedding方法将所有节点嵌入到K维空间进行向量化表示,所有向量可用集合 \mathbf{{R}}^K=\{\mathrm{R}_1^K,\mathrm{R}_2^K,\ldots,\mathrm{R}_n^K\} 表示;第2步:使用一种聚类方法从集合 \mathbf{{R}}^K 中计算出M个聚类中心节点 \mathbf{PR}^K=\{\mu_1^K,\ldots,\mu_j^K,\ldots,\mu_M^K \} (M为超参数)构成一个模板图;第3步,将所有图结构与M个节点的模板图进行传递对齐,对齐后任意大小的图都被转化为M个节点的固定大小。
具体而言,论文中第1步使用的Node Embedding方法是作者于2014年提出的基于深度的特征表示算法[3] Depth-Based(DB) Representation,该方法是一种无监督的Node Embedding方法,并已被证实可以有效地表征节点从局部到全局的拓扑信息,第p个图结构第i个节点的K层深度特征向量记作 \mathrm{{DB}}_{p;i}^K 。
第2步论文中使用的是常见的Kmeans算法,则关于全部节点的M个聚类中心\mathbf{PR}^K=\{\mu_1^K,\ldots,\mu_j^K,\ldots,\mu_M^K \} 可通过最小化以下目标函数得到:
\arg\min_{\Omega} \sum_{j=1}^M \sum_{\mathrm{R}_i^K \in c_j} \|\mathrm{R}_i^K- \mu_j^K\|^2
论文第3步首先计算原始图结构与模板图结构的节点集合计算距离矩阵,设第p个原始图结构与模板图结构的K维节点向量距离矩阵为 A^K_p,则原始图的第i个节点与模板图的第j个节点距离可由以下公式计算:
\begin{equation} A^K_p(i,j)=\|\mathrm{{DB}}_{p;i}^K - \mu_j^K\|_2 \end{equation}
如果距离矩阵中的第i行、第j列元素在整个i行中最小,说明原始图的第i个节点与模板图的第j个节点最相似,论文将这种关系称为原始图的第i个节点与模板图的第j个节点是对齐的。基于上述规则,可以从距离矩阵中得到原始图与模板图的对齐矩阵:
\begin{equation} C^K_p(i,j)=\left\{ \begin{array}{cl} 1 & \small{\mathrm{if} \ A^K_p(i,j) \ \mathrm{is \ the \ smallest \ in \ row } \ i} \\ 0 & \small{\mathrm{otherwise}}. \end{array} \right. \end{equation}
其中每行仅有一个元素为1其余元素为0,表示原始图的每个节点都对应一个模板图中的节点,反过来与模板图中特定节点对应的原始图节点可能有多个。值得注意的是,当两个原始图结构中的节点都与相同的模板图结构中的节点对齐时,这两个原始图结构中的节点也是相互对齐的,因此这种对齐关系是传递的。
得到对齐矩阵后,假设第p个图结构的带self-loop的邻接矩阵为 \tilde{A}_{p},节点的属性特征矩阵为 X_p,则将原始图结构通过对齐转化为M节点固定大小的图结构的公式如下:
\begin{equation} \bar{A}_{p}^{K}= (C^K_p)^T (\tilde{A}_{p}) (C^K_p) \end{equation}
\begin{equation} \bar{X}_{p}^{K}= (C^K_p)^T X_p \end{equation}
上述传递对齐算法流程与作者在2016年提出的针对模式空间的节点匹配算法[4]类似。(篇幅限制本文介绍传递对齐算法略有缩减,具体细节请参考论文原文)
新的Spatial图卷积运算操作
经过传递对齐后的所有图结构均有M个节点,且任意对齐后的图结构的邻接矩阵所对应的节点都与模板图节点共享相同排序,即无论原始图结构节点在邻接矩阵中的排列顺序是否改变,对齐后图结构的邻接矩阵都保持了相同的节点排列顺序,这种节点的置换不变性(Permutation Invariance)使得后面设计的新图卷积运算成为可能。对于第h个滤波器,新的Spatial图卷积运算公式如下:
\begin{equation} Z^h= \mathrm{Relu}( \bar{D}^{-1} \bar{A} \sum_{j=1}^c{(\bar{X} \odot W^h)}_{:,j}) \end{equation}
其中 Z^h 是M个维度为c的节点信号 \bar{X} 在通过第h个滤波器后得到的M个维度为1的节点信号, \odot 是元素位乘积(Element-wise Hadamard Product), W^h 是M个维度为c的可训练权重矩阵。假设输入的图结构有5个节点,单个节点信号维度为3,则针对节点 v_2 ,节点特征信号在通过单一滤波器进行上述图卷积操作时的具体计算示意图如下:
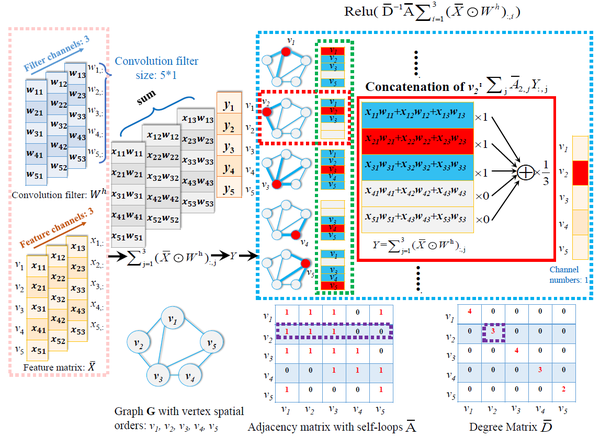

论文提出的图卷积运算与大部分现有的图卷积运算最大的区别,即图中任意节点都被分配了相应不同的可训练权重,使得训练过程中网络可以自适应地区分指定节点之间的重要性。
空间对齐的图神经网络
基于上述提出的传递对齐算法框架以及与之对应的新型Spatial图卷积运算,论文给出了一个空间对齐的图神经网络结构,结构如下图所示:
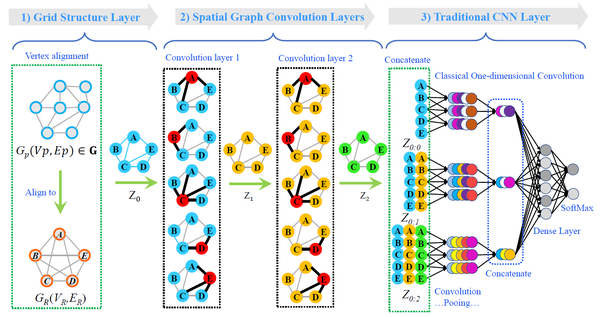

首先网络的第1部分进行的是无监督学习,通过传递对齐将所有大小不一的原始图结构转化为相同大小的图结构;网络的第2部分是将转化后的图结构输入给新型Spatial图卷积层;网络的第3部分首先将第2部分各图卷积层的输出进行拼接组合,再将拼接后的节点信号输入给传统的1D卷积层、池化层,最后经过全连接层输出分类结果。
实验
论文选择了在图分类问题中常见的标准数据集[5],其中包含生物信息图结构以及社交网络图结构,具体数据集信息如下:


对比的方法包括传统的Graph Kernel方法以及基于深度学习的方法。
与Graph Kernel的实验对比效果如下:


与深度学习的实验对比效果如下:


实验证明提出的ASGCN方法在大部分数据集中都显著优越于其他方法,无论是Graph Kernel还是深度学习的方法。值得注意的是,在对比实验中,论文提出的ASGCN方法在处理所有不同数据集时,都使用了相同的网络结构(卷积层数、输出维度)及模板图大小设置(M取值)。对于不同数据集,实验变化的超参数只有学习率(learning rate)以及迭代次数(epoch),因此论文认为如果针对不同数据集,网络结构以及模板图大小也做出相应的调整优化,会得到比当前更好的实验效果。
总结
论文提出了一种新的基于空间的GCN模型ASGCN,将任意大小的图转换为固定大小的对齐结构,并在对齐图结构上执行新的Spatial图卷积操作。与大多数现有的基于Spatial的GCN不同,ASGCN可以在图卷积操作的过程中自适应地区分指定节点之间的重要性,这也解释了ASGCN相比大部分现有GCN在实验上表现更好的原因。
参考文献:
[1] Bruna, J., Zaremba, W., Szlam, A., & LeCun, Y. (2013). Spectral networks and locally connected networks on graphs. arXiv preprint arXiv:1312.6203.
[2] Henaff, M., Bruna, J., & LeCun, Y. (2015). Deep convolutional networks on graph-structured data. arXiv preprint arXiv:1506.05163.
[3] Bai, L., & Hancock, E. R. (2014). Depth-based complexity traces of graphs. Pattern Recognition, 47(3), 1172-1186.
[4] Bai, L., Rossi, L., Zhang, Z., & Hancock, E. (2015, June). An aligned subtree kernel for weighted graphs. In International Conference on Machine Learning (pp. 30-39).
[5] Kersting, K., Kriege, N., Morris, C., Mutzel, P., & Neumann M. (2016). Benchmark Data Sets for Graph Kernels. (2016). http://graphkernels.cs.tu-dortmund.de
论文作者主页:
Graph Kernel相关答案:
