
CVPR论文ZSL系列(二)

今天介绍一篇关于利用类之间的三种联系,缓解hubness问题的论文。
《Preserving Semantic Relations for Zero-Shot Learning》
思想
- 定义图片的三种联系。作者分别定义了图片之间的三种关系,分别是相同,类似和不同。比如类标签是猫,那么相同类就是猫,类似是狮子,不同是猪等等。
由于利用图片之间的三种联系,可以拉近同类之间的距离,疏远异类之间的关系。相当于在训练过程中,多增加了一层限制,使预测结果更加靠近所属类。 - 利用视觉空间,可缓解hubness问题。在语义空间中寻找相关类,会出现hubness问题,也就是在搜索结果中,会出现多个同级结果,造成误判。比如预测结果为(1,1,1,0),但是搜索到(0,1,1,1),(1,0,1,1)等结果。这些都是可能出现的情况,
但是在视觉空间中,由于每张图片的差异性,不同类之间计算出的结果相同的可能性几乎为0、所以作者提出有语义空间转为视觉空间更为有利。 - encoder-decoder机制,使模型更为精确。sematic space->visiual feature -> sematic spce。共有两次转换,每一次转换,都增加一层限制
方法
1.定义语义关系。将图片之间的关系分为相同、类似和不同。语义关系公式如下。
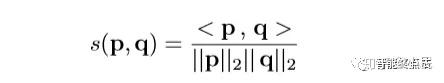

定义联系:
a. s(p,q) = 1,属于同类。
b. s(p,q) > τ 且 s(p,q) < 1,相似类。
c. s(p,q) < τ,不同类。
τ 是设置的阈值,可根据具体数据设置。
2. encoder-decoder空间转换。


sematic space->embedding space,这里embedding space 就是visiual space。
然后找一个三元组(Xi,Xj,Xk)满足相同、类似和不同的关系。比如(0,1,1,1)是代表猫的语义描述,那么encoder会将其转为视觉特征。接着在训练集中寻找三张图片,分别代表(Xi,Xj,Xk)构造损失函数。寻找方法下面会介绍。
embedding space 转为 reconstruction,是利用encoder-decoder的优势,将其再次重构,使结果能更加精确。
损失函数
semetic -> embedding space 相同与不同。


semetic -> embedding space 类似。
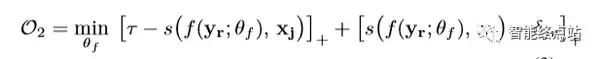

embedding space -> reconstruction 重构。

总损失函数
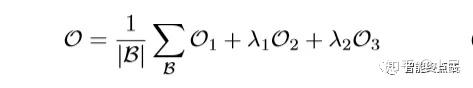

预测函数


寻找三元组
Xi寻找可直接根据标签寻找相同类。Xj和Xk可有多种寻找方法,其中作者选取了最具代表性且保留最大信息的方法。
Xj的寻找。首先在训练集样本中寻找满足关系b的m个样本,然后分别计算损失函数O2,选取损失最大的样本为Xj。
Xk的寻找。首先在训练集样本中寻找满足关系c的m个样本,然后分别计算损失函数O1,选取损失最大的样本为Xj。
