
K近邻,最简单的预判

1,K近邻通俗一点说:
你周围的大多数人的选择,影响着或主导着你的选择;
你周围的大多数人的色彩,渲染着和体现着你的色彩;
你周围的大多数人的品行,反映着和彰显着你的品行;
这种用大多人的普遍性来预判另一个陌生人的方式从古至今一直沿用,
比如:“人以类聚,物以群分”,“近朱者赤,近墨者黑”;
不可否认古人的经验智慧虽有偏颇,但是有价值。
近邻就是你周围的人, 大多数就是K个人或物中具有的普遍多数的属性,高概率的预判你也拥有这种普遍多数的属性。
2,核心的问题
那么核心问题来了,一是,怎么定义近邻,有人定义为物理距离:“远亲不如近邻”;有人定义为精神上的距离:“海内存知己天涯若比邻”;二是,选择几个近邻,最方便最准确的代表自己呢,最简单粗暴的是就选一个近邻,是K=1的预判算法,选多选少都对预判的准确率有影响,可以说这是一个需要权衡择中的技术活。
3,扬长避短
其实K近邻预判,也有致命的缺点,一是样本类别间数量的不均衡,比如,你有十个近邻,有3个是好人,7个是坏人;其中两个好人离你最近;如果选择最近的两个你是好人,但是如果选择超过7个人呢,我们不用考虑远近,就可以武断你不是个好人,你肯定决定荒谬;其实通过使用距离加权,来消弱类别间数量失衡带来的消极预判;二是计算量超大,样本数量大,属性太多都需要计算,消耗计算资源和计算时间,其实可以偷懒减少或归并属性,简约样本属性,减少计算维度,计算效率;
简单而言,K近邻需要兼顾效率(节省时间,及时响应需求)与公平(预判要准确,真实反映现实)。
4,实战练兵
数据:脱敏后的天猫4个月的部分用户的消费行为数据,包含用户编码,品牌编码,消费行为编码(浏览点击,商品收藏,商品加购物车,下单成交),消费日期;数据分成两部分:3个月为训练数据集(产出模型),1个月为测试数据集(测评模型);
太活跃的人基本上都是“看热闹”的闲人,她们经常在犹豫不决的左顾右盼中消耗自己。
1,转化数据,多属性归纳出新属性:
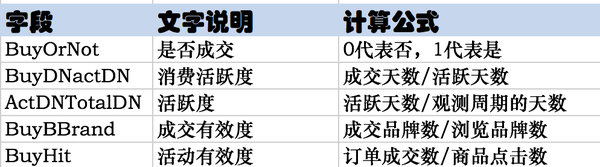

2,R实战,K的选择从1~30的效果如下:兼顾稳健型K不能太小,兼顾预判误差不能太大的原则,选择K=7,测试样本的误差为:3.3%,已经很低了,效果还是可以的。
library("class")
Tmall_train<-read.table(file="天猫_Train_1.txt",header=TRUE,sep=",")
head(Tmall_train)
BuyOrNot BuyDNactDN ActDNTotalDN BuyBBrand BuyHit
1 1 6.38 51.09 2.83 1.57
2 1 8.93 60.87 3.20 2.17
3 1 16.13 33.70 11.63 6.36
4 1 16.22 40.22 11.29 6.25
5 1 3.85 56.52 1.89 1.45
6 1 4.00 54.35 2.13 1.28
Tmall_train$BuyOrNot<-as.factor(Tmall_train$BuyOrNot)
Tmall_test<-read.table(file="天猫_Test_1.txt",header=TRUE,sep=",")
Tmall_test$BuyOrNot<-as.factor(Tmall_test$BuyOrNot)
set.seed(123456)
errRatio<-vector()
for(i in 1:30){
KnnFit<-knn(train=Tmall_train[,-1],test=Tmall_test[,-1],cl=Tmall_train[,1],k=i,prob=FALSE)
CT<-table(Tmall_test[,1],KnnFit)
errRatio<-c(errRatio,(1-sum(diag(CT))/sum(CT))*100)
}
plot(errRatio,type="b",xlab="近邻个数K",ylab="错判率(%)",main="天猫成交顾客分类预测中的近邻数K与错判率", family="SimSun")
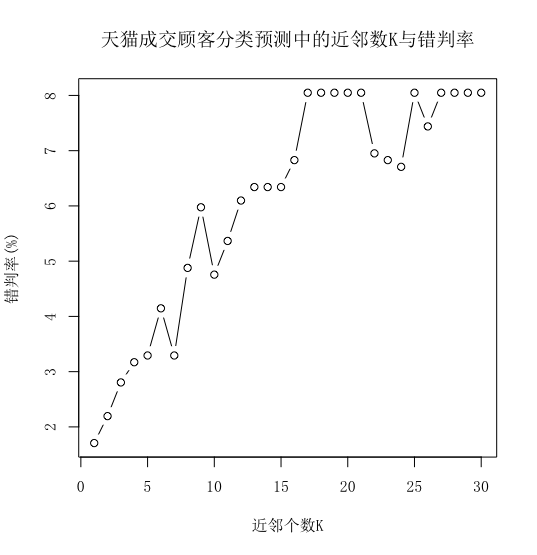

3,主要特征的选择,在K=7的基础上,我们依次剔除某一特征,观测误差的变化,依据FI计算每一个特征的重要性,并确定响应的权重值,来弥合次要特征对模型预判的影响;
####天猫数据KNN分类讨论变量重要性
library("class")
par(mfrow=c(2,2), family="SimSun")
set.seed(123456)
errRatio<-vector()
for(i in 1:30){
KnnFit<-knn(train=Tmall_train[,-1],test=Tmall_test[,-1],cl=Tmall_train[,1],k=i,prob=FALSE)
CT<-table(Tmall_test[,1],KnnFit)
errRatio<-c(errRatio,(1-sum(diag(CT))/sum(CT))*100)
}
plot(errRatio,type="l",xlab="近邻个数K",ylab="错判率(%)",main="近邻数K与错判率")
errDelteX<-errRatio[7]
for(i in -2:-5){
fit<-knn(train=Tmall_train[,c(-1,i)],test=Tmall_test[,c(-1,i)],cl=Tmall_train[,1],k=7)
CT<-table(Tmall_test[,1],fit)
errDelteX<-c(errDelteX,(1-sum(diag(CT))/sum(CT))*100)
}
plot(errDelteX,type="l",xlab="剔除变量",ylab="剔除错判率(%)",main="剔除变量与错判率(K=7)",cex.main=0.8)
xTitle=c("1:全体变量","2:消费活跃度","3:活跃度","4:成交有效度","5:活动有效度")
legend("topright",legend=xTitle,title="变量说明",lty=1,cex=0.6)
FI<-errDelteX[-1]+1/4
wi<-FI/sum(FI)
GLabs<-paste(c("消费活跃度","活跃度","成交有效度","活动有效度"),round(wi,2),sep=":")
pie(wi,labels=GLabs,clockwise=TRUE,main="输入变量权重",cex.main=0.8)
ColPch=as.integer(as.vector(Tmall_test[,1]))+1
plot(Tmall_test[,c(2,4)],pch=ColPch,cex=0.7,xlim=c(0,50),ylim=c(0,50),col=ColPch,
xlab="消费活跃度",ylab="成交有效度",main="二维特征空间中的观测",cex.main=0.8)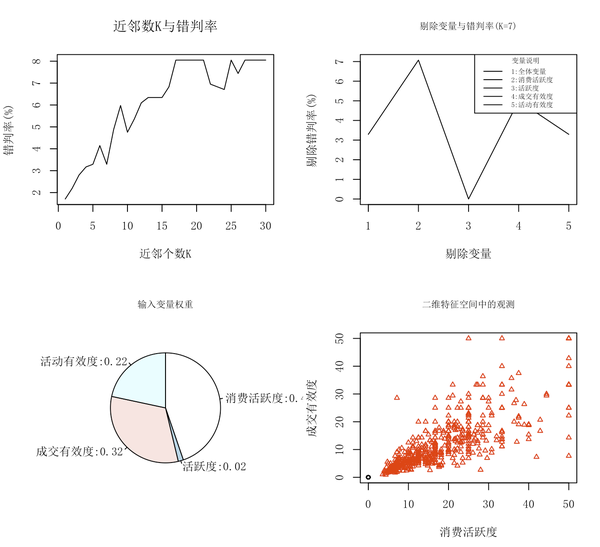

加权后,我们再一次看看KNN预判天猫用户是否购买的模样准确率明显提升了;
install.packages("kknn")
library("kknn")
par(mfrow=c(2,1), family="SimSun")
Tmall_train<-read.table(file="天猫_Train_1.txt",header=TRUE,sep=",")
Tmall_train$BuyOrNot<-as.factor(Tmall_train$BuyOrNot)
fit<-train.kknn(formula=BuyOrNot~.,data=Tmall_train,kmax=11,distance=2,kernel=c("rectangular","triangular","gaussian"),na.action=na.omit())
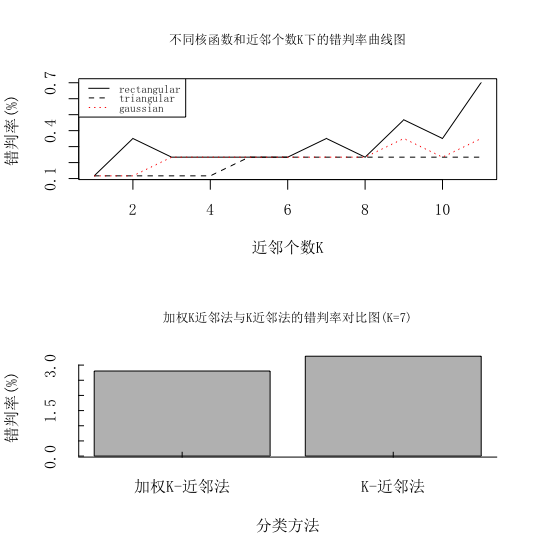
plot(fit$MISCLASS[,1]*100,type="l",main="不同核函数和近邻个数K下的错判率曲线图",cex.main=0.8,xlab="近邻个数K",ylab="错判率(%)")
lines(fit$MISCLASS[,2]*100,lty=2,col=1)
lines(fit$MISCLASS[,3]*100,lty=3,col=2)
legend("topleft",legend=c("rectangular","triangular","gaussian"),lty=c(1,2,3),col=c(1,1,2),cex=0.7) #给出图例
Tmall_test<-read.table(file="天猫_Test_1.txt",header=TRUE,sep=",")
Tmall_test$BuyOrNot<-as.factor(Tmall_test$BuyOrNot)
fit<-kknn(formula=BuyOrNot~.,train=Tmall_train,test=Tmall_test,k=7,distance=2,kernel="gaussian",na.action=na.omit())
CT<-table(Tmall_test[,1],fit$fitted.values)
errRatio<-(1-sum(diag(CT))/sum(CT))*100
library("class")
fit<-knn(train=Tmall_train,test=Tmall_test,cl=Tmall_train$BuyOrNot,k=7)
CT<-table(Tmall_test[,1],fit)
errRatio<-c(errRatio,(1-sum(diag(CT))/sum(CT))*100)
errGraph<-barplot(errRatio,main="加权K近邻法与K近邻法的错判率对比图(K=7)",cex.main=0.8,xlab="分类方法",ylab="错判率(%)",axes=FALSE,family="SimSun")
axis(side=1,at=c(0,errGraph,3),labels=c("","加权K-近邻法","K-近邻法",""),tcl=0.25)
axis(side=2,tcl=0.25)

至此,我们简单的掌握了KNN的基础理论和简单的R实战方法,结合业务情况,结合“道”和“术”灵活应变,发挥出KNN在商业预测上的价值吧。
至此也感谢你的认真拜读,喜欢点个赞就好
感谢你的阅读,关注公.众.号:趣味数据周刊,后台回复:idw007,可以获取文章数据。 和志同道合的伙伴一起学习统计学,数据分析,机器学习,走向人生巅峰,有问题可以撩我;很乐意为你效劳。
