
基于无标签数据Copy-Augmented预训练结构改善语法纠错(2019.06)

论文: Improving Grammatical Error Correction via Pre-Training a Copy-Augmented Architecture with Unlabeled Data
作者: Wei Zhao, Liang Wang
一、简介
神经机器翻译系统已成为语法错误纠正(GEC)任务的最新方法。在本文中,我们为GEC任务提出了一种复制增强的体系结构,通过将未更改的单词从源句子复制到目标句子的方法。由于GEC缺乏足够的带标签训练数据来实现高精度。我们使用无标记的“十亿基准”使用降噪自动编码器,对复制增强的架构进行了预训练,并在完全预训练的模型与部分预训练的模型之间进行了比较。这是第一次从源上下文中复制单词,并在GEC任务上进行了将完全预训练seq2seq模型的实验。此外,我们为GEC任务添加了令牌级和句子级多任务学习。 CoNLL-2014测试集上的评估结果表明,我们的方法大大优于最近发布的所有最新结果。代码和经过预训练的模型在https://github.com/zhawe01/fairseq-gec上发布。
语法错误纠正(GEC)是检测和纠正文本中的语法错误的任务。 由于英语语言学习者的数量不断增加,在过去的十年中,人们对英语GEC的关注日益增加。
以下句子是GEC任务的示例,其中粗体字需要更正为其副词形式。
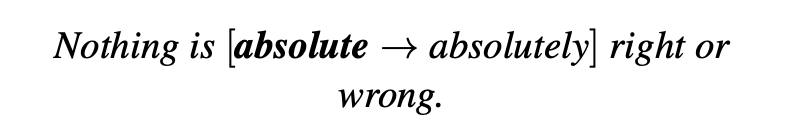

尽管机器翻译系统已成为GEC的最新方法,但是GEC与翻译不同,因为它仅更改源句子的几个单词。 在表1中,我们列出了三个不同数据集中目标句子与源句子的不变词比率。
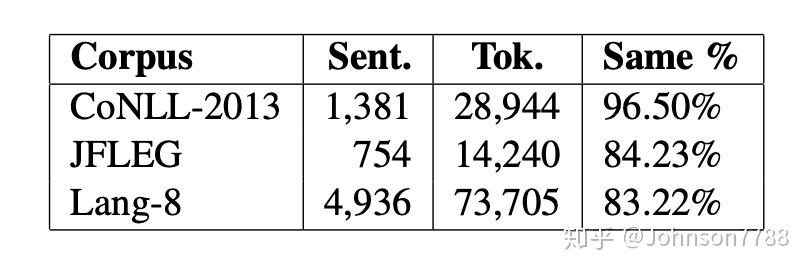

我们可以看到,可以从源句子中复制超过80%的单词。考虑到GEC任务中未更改单词的百分比很高,因此需要更合适的神经体系结构。我们通过使它能够直接从源句子中复制未更改的单词和词汇外的单词来增强当前的神经体系结构,就像人类在纠正句子时所做的一样。据我们所知,这是第一次在GEC上使用神经复制机制。
有了大规模的训练语料库的帮助,包括NUS Corpus of Learner English (NUCLE) (Dahlmeier et al., 2013) 和大规模的 Lang-8 corpus(Tajiri et al., 2012),我们已经取得了很大进展。但是,即使有数百万个带标签的句子,如果要实现更高精度,还需大量带标签的样本,所以GEC仍然具有挑战性。
为了缓解标签数据不足的问题,我们提出了一种利用无标签数据的方法。具体方法是通过利用去噪自动编码器,用无标签的十亿基准测试我们的复制增强模型(Chelba等,2013)。
我们还为复制增强的体系结构添加了两个多任务,包括token-level标签任务和sentence-level复制任务,以进一步提高GEC任务的性能。复制机制是第一次在GEC任务上使用,以前是在文本摘要任务上使用了该机制。在GEC任务上,由于复制机制可以直接从源输入token中复制未更改的单词和out-of-vocabulary的单词,因此可以用很小的词汇量训练模型。此外,通过将工作的恒定部分与GEC任务分开,复制使体系结构的生成部分更加强大。在本文的实验部分,我们证明了复制不仅仅是解决“UNK问题”,而且还可以唤起对GEC问题的更多编辑次数。
通过在CoNLL 2014测试数据集上获得56.42 F0.5分数,副本增强的体系结构在GEC任务上胜过所有其他体系结构。结合去噪自动编码器和多任务功能,我们的体系结构在CoNLL-2014测试数据集上达到了61.15 F0.5,比最新系统提高了+4.9 F0.5分数。
总而言之,我们的主要贡献如下。 (1)针对GEC问题,我们提出了一种更合适的神经体系结构,该体系结构使得可以直接从源输入token中复制未更改的单词和out-of-vocabulary单词。 (2)我们使用降噪自动编码器对大规模无标签数据的复制增强模型进行预训练,从而减轻了标签训练语料库不足的问题。 (3)我们评估了CoNLL-2014测试集的体系结构,这表明我们的方法在很大程度上优于最近发布的所有最新方法。
二、我们的方法
2.1 基础架构
神经机器翻译系统已成为语法错误纠正(GEC)的最新方法。通过将第二语言学习者写的句子作为源句子,并将经过语法纠正的句子作为目标句子。翻译模型学习从源句子到目标句子的映射。
我们使用基于注意力的Transformer(Vaswani et al,2017)架构作为基准。 Transformer用L个相同的块的堆叠对源语句进行编码,并且每个都对源标签使用多头自注意力机制,然后是按position-wise的前馈层,以产生其上下文感知的隐藏状态。解码器具有与编码器相同的架构,将L个相同的多头注意力块与目标隐藏状态的前馈网络堆叠在一起。但是,解码器模块在编码器的隐藏状态上有一个额外的注意力层。
我们的目标是在给定源单词token(x1,...,xN)的情况下,预测下一个单词的索引t,在所有的token序列(y1,...,yT)中,如下所示:
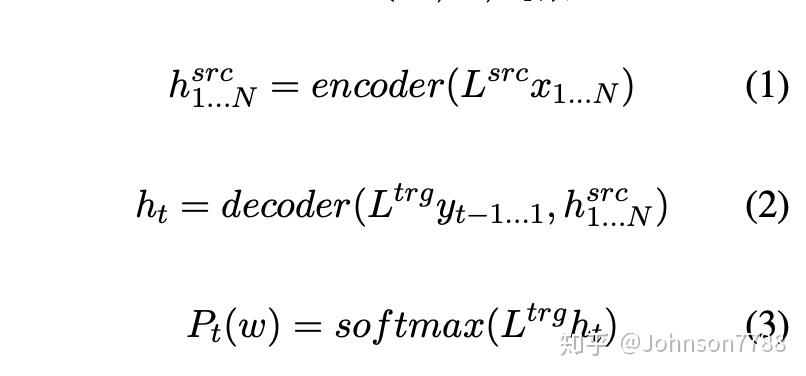

矩阵L∈R dx×| V |是单词嵌入矩阵,其中dx是单词嵌入维数,| V |是词汇量的大小。 hsrc 1 ... N是编码器的隐藏状态,而ht是下一个单词的目标隐藏状态。对目标隐藏状态和嵌入矩阵之间的内积进行softmax运算,得到下一个词的生成概率分布。
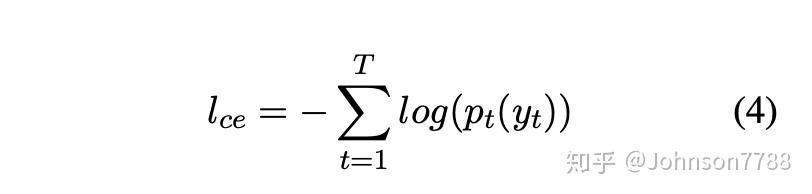

每个训练示例的损失Ice是解码期间每个位置的交叉熵损失的累积。
2.2 复制机制
事实证明,复制机制对文本摘要任务(Gu et al, 2016)和语义解析任务(Jia and Liang,2016)有效。在本文中,我们首次将复制机制应用于GEC任务,使模型能够从源句子复制token。
如图1所示,除了从固定词汇表生成单词外,我们的增强网络还允许从源输入token中复制单词。
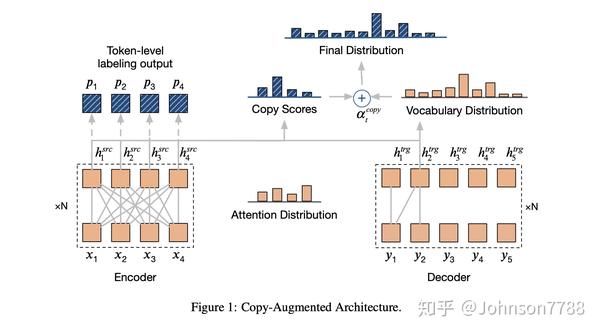

在等式5中定义,最终概率分布Pt是生成分布Pgen和复制分布Pcopy的混合。最终固定单词表被源句中出现的所有单词所扩展。
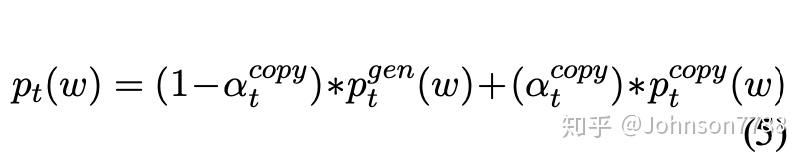

在每个时间步长t,copy和生成之间的平衡由平衡因子αcopyt∈[0,1]控制。
新架构通过生成目标隐藏状态,将生成概率分布作为基本模型输出。 通过在解码器的当前隐藏状态htrg和编码器的隐藏状态Hsrc(与hsrc 1 ... N相同)之间的新注意分布计算源输入token的copy scores。 copy attention的计算与公式6、7、8中列出的编码器-解码器attention相同:
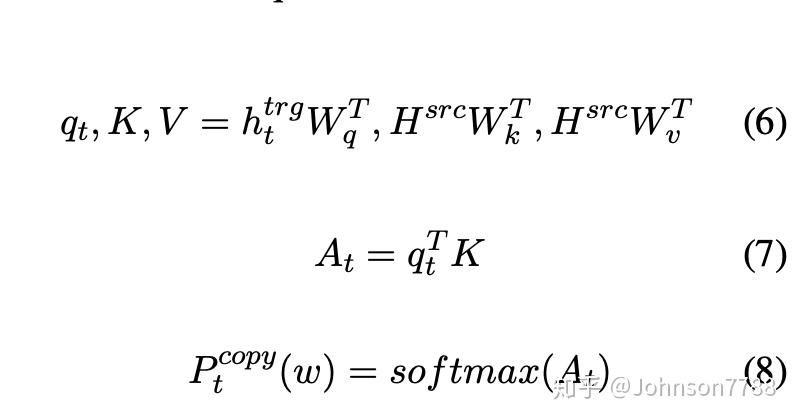

qt,K和V是计算注意力分布和copy隐藏状态所需的query,key和value。 我们使用归一化的注意力分布作为copy scores,并使用copy 隐藏状态来估计平衡因子αtcopy
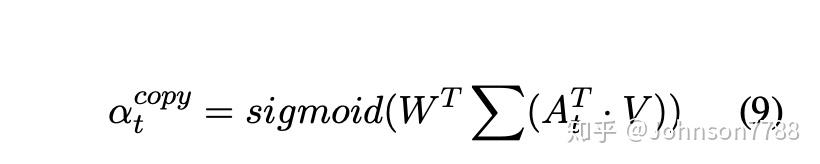

损失函数如公式4中所述,公式5中给出的混合概率分布yt。
三、预训练
缺乏大量训练数据时,预训练在许多任务中显的很有效。在本节中,我们建议对自动编码器进行降噪,从而可以使用大规模无标签语料库对模型进行预训练。我们还介绍了一种部分预训练的方法,和降噪自动编码器进行比较。
3.1 降噪自动编码器
降噪自动编码器(Vincent等,2008)通常用于模型初始化,以从输入中提取和选择特征。 BERT(Devlin等人,2018)使用了预训练的双向transformer模型,并且在许多NLP任务上都大大优于现有系统。与降噪自动编码器相比,BERT仅预测15%的屏蔽字,而不重构整个输入。 BERT随机降噪15%的token, 其中这些token,通过用[MASK]替换80%的token,将10%的token替换为随机单词以及将10%的token保持不变。
受BERT和降噪自动编码器的启发,我们通过对 One Billion Word Benchmark (Chelba et al 2013)加噪声,来预训练我们的copy-augmented的seq2seq模型(Chelba等,2013),这是一个大型的sentence-level英语语料库。在我们的实验中,损坏的句子对是通过以下过程生成的。
- 删除token的可能性为10%。
- 添加token的概率为10%。
- 用从词汇表中随机选择的单词替换单词,概率为10%。
- 通过在单词的位置上增加正态分布偏差来对单词进行排序,然后将单词按照校正后的位置重新排序,标准差为0.5。
通过大量的人工训练数据,seq2seq模型通过信任大多数输入token(但并非总是如此)来学习重建输入句子。由破坏的过程生成的句子对,在某种程度上是GEC句子对,因为它们都通过删除,添加,替换或整理一些token将非“完美”句子翻译为“完美”句子。
3.2预训练解码器
在自然语言处理(NLP)中,模型的预训练部分还可以提高许多任务的性能。 Word2Vec和GloVe(Pennington等,2014; Mikolov等,2013)进行了预训练的词嵌入。 CoVe(McCann等人,2017)对编码器进行了预训练。 ELMo(Peters等人,2018)预训练了深度双向架构等。在所有NLP任务中,所有这些都被证明是有效的。
按照(Ramachandran 2016; Junczys-Dowmunt 2018)所述,我们使用预训练copy-augumented seq2seq架构的解码器,作为典型语言模型进行了实验。我们使用预训练的参数初始化GEC模型的解码器,同时随机初始化其他参数。由于我们在编码器和解码器之间使用绑定词嵌入,因此模型的大多数参数都是预训练模型的,除了编码器,编码器-解码器的注意力和copy注意力之外。
四、多任务学习
多任务学习(MTL)通过联合训练多个相关任务来解决问题,并已在从计算机视觉到NLP许多任务中显示出其优势。在本文中,我们探索了GEC改善性能的两个不同任务。
4.1 token-level Labeling 任务
我们提出一个token-level的标签分类任务,在源句子中为每个token分配一个label,指示该token是对还是错。
假设每个源token xi可以与目标token yj对齐,如果xi = yj,我们定义源token是正确的,否则,则是错误的。每个token的label是通过在经过细微变换后,将编码器的最终状态hsrc通过softmax进行预测的,如公式10所示。
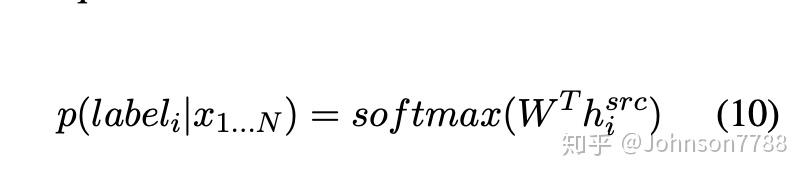

token级别的标签任务显式地增强了编码器输入token的正确性,以后可以由解码器使用。
4.2 sentence-level copying 任务
sentence-level copying 任务背后的主要动机是,当输入句子看起来完全正确时,使模型进行更多copy。在训练期间,我们将相等数量的采样正确句子对,和已编辑句子对发送给模型。输入正确的句子时,我们通过解码器的输出移除解码器的注意力。如果没有编码器/解码器attention,则生成工作会变得很困难。最后模型的copy部分将针对正确的句子而增强。
五、评价
5.1 数据集
根据以前的研究,我们使用公共NUCLE语料库作为并行训练数据。我们使用的无标签数据集是众所周知的One Billion Word Benchmark(Chelba et al,2013)。我们选择CoNLL-2014共享任务的测试集作为我们的测试集,并选择CoNLL-2013测试数据集作为我们的开发基准。对于CoNLL数据集,用的指标是MaxMatch(M 2)分数(Dahlmeier和N,2012),对于JFLEG(Napoles 2017)测试集,指标是GLEU(Sakaguchi2016)。
为了使我们的结果与GEC领域的最新结果具有可比性,我们将训练数据严格限于公共资源。表2和表3列出了本文中使用的所有数据集。
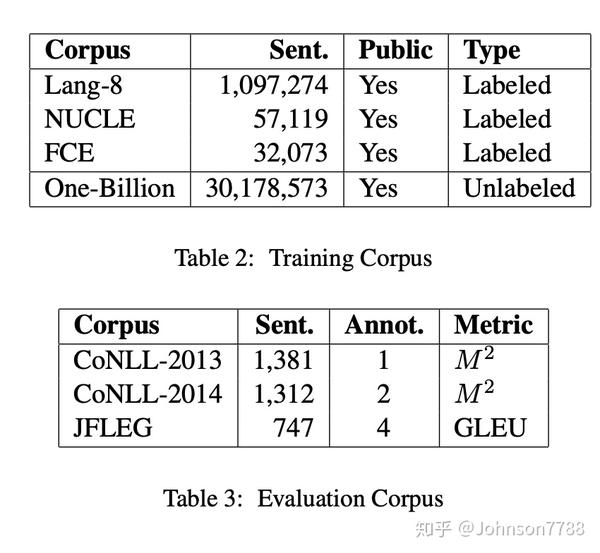

我们建立了一个基于统计的拼写错误纠正系统,并纠正了训练数据中的拼写错误。 按照(Ge2018)等,我们在评估开发/测试数据集之前应用了拼写校正。从经过拼写校正的Lang8数据语料库中提取一个50,000字的字典。像以前的工作一样,我们在训练前从Lang-8语料库中删除了不变的句子对。
5.2 模型和训练设置
在本文中,我们使用了公共FAIR seq2seq工具包代码库中Transformer实现。
对于transformer模型,我们使用token嵌入和512维的hidden size,并且编码器和解码器具有6层和8个attention heads。对于positionwise前馈网络中的内层,我们使用4096 hidden size。类似于以前的模型,我们将Dropout设置为0.2。从训练数据中收集了50,000个用于输入和输出token的词汇表。该模型总共具有97M参数。
使用Nesterovs Accelerated Gradient优化器对模型进行优化。我们将学习率设置为0.002,权重衰减为0.5,patience为0,动量为0.99,最小学习率为10-4。在训练期间,我们会评估每个epoch的性能。我们还使用edit-weighted 的MLE损失,通过用平衡因子Λ缩放更改的单词的损失。
使用无标签的数据进行预训练时,几乎使用相同的体系结构和超参数,但editweighted损失的Λ参数除外。训练降噪自动编码器时,设置Λ= 3,训练GEC模型时,设置Λ∈[1,1.8]。
在解码期间,我们使用beam-size为12,并按长度归一化模型得分。在评估CoNLL-2014数据集时,我们不使用reranking。但是,我们对在Common Crawl上的JFLEG测试集,用语言模型对训练时的前12个候选假设进行rerank。
5.3 实验结果
我们将结果与著名的GEC系统进行比较,如表4所示。
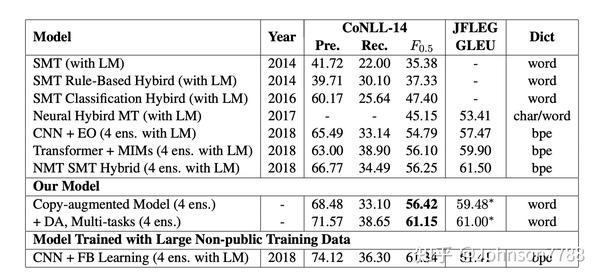

针对GEC任务构建了基于规则,分类,统计机器翻译(SMT)和神经机器翻译(NMT)的系统。我们在表4的顶部列出了著名的模型,在中间列出了我们的结果。几乎所有以前的系统都使用大型语言模型对前12个结果进行rerank,其中一些使用部分预训练的参数,从而将结果提高1.5至5 F0.5分数。我们的copy-augmented架构在CoNLL2014数据集上获得了56.42 F0.5的得分,甚至在没有rerank或未经过预训练的情况下也优于所有以前的架构。结合降噪自动编码器和多任务,我们的模型在CoNLL-2014数据集上获得了61.15 F0.5分数。该结果超过了以前的最新系统+4.9 F0.5点。
在表4的底部,我们列出了(Ge et al。2018)的结果。我们之间无法进行直接比较,因为他们使用了非公开的Cambridge Learner语料库(CLC)(Nicholls,2003)和他们自己收集的非公开的Lang-8语料库,从而使他们标签的训练数据集比我们的大3.6倍。即使这样,我们在CoNLL 2014测试数据集和JFLEG测试数据集上的结果也非常接近他们的结果。
5.4 消融研究
5.4.1 copying消融结果
在本部分中,我们将比较在有无GEC任务的copying机制的情况下Transformer架构的结果。如表5所示,copy-augmented模型将F0.5分数从48.07增加到54.67,绝对增加+6.6。大部分改进来自固定词汇表中的单词,这些单词在基本模型中将被预测为UNK单词,但在copy-augmented模型中将被copy为单词本身。
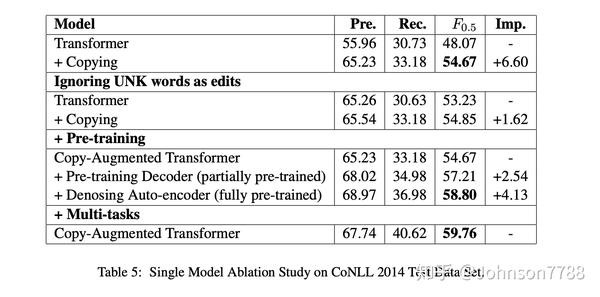

copying通常被称为擅长处理UNK单词。为了验证copying是否比copying UNK单词还多,我们通过忽略所有UNK编辑来进行实验。从表5中,我们可以看到,即使忽略了UNK收益,copy-augmented的模型仍然比基准模型高1.62 F0.5点,并且大多数收益来自召回率的提高。
5.4.2 预训练消融结果
从表5中,我们可以看到,通过对解码器进行部分预训练,F0.5分数从54.67提高到57.21(+2.54)。与未经训练的相比,这显然是一种改进。降噪自动编码器将单个模型从54.67改进为58.8(+4.13)。我们还可以看到,经过预训练后,准确性和召回率都有所提高。
为了进一步研究预训练参数的优良程度,我们在表6中显示了有和没有降噪自动编码器的预训练参数的早期结果。
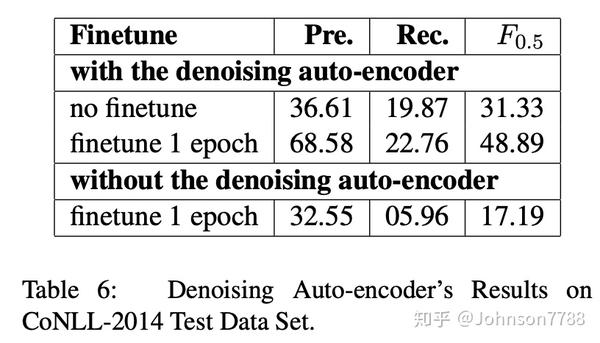

结果表明,如果我们为模型预定义1个epoch,借助有标签的训练数据,模型以较大的差距击败了未经训练的模型(48.89 vs 17.19)。即使没有微调,预训练模型也可以得到31.33的F0.5分数。这证明了预训练为模型提供了比随机选取的模型更好的初始化参数。
5.4.3 sentence-level copying任务消融结果
我们添加了sentence-level级别的copying任务,以鼓励模型在输入正确的句子时不进行任何编辑。为了验证这一点,我们通过从Wikipedia抽取500个句子来创建正确的句子集。此外,我们通过从CoNLL-2013测试数据集中采样500个句子来生成错误句子集,该数据集是一个带error-annotated的数据集。然后,我们计算两组平衡因子αcopy的平均值。
在添加sentence-level copying任务之前,正确和错误句子集的αcopy为0.44 / 0.45。添加sentence-level copying任务后,该值更改为0.81 / 0.57。这意味着最终分数的81%来自正确句子集的copying,而错误句子集只有57%。通过添加sentence-level copying任务,模型可以学习区分正确的句子和错误的句子。
5.5 注意力可视化
分析copying和生成如何划分他们的工作。我们在Figure 2中可视化了copying注意力对齐和编码器-解码器注意力对齐。
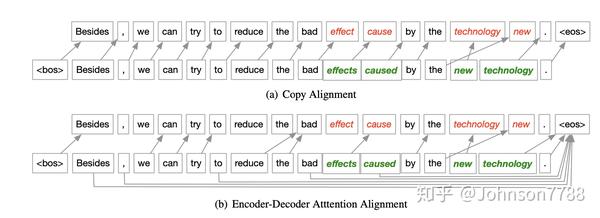

在Figure 2(a)中,copying将权重集中在下一个单词上,而在Figure 2(b)中,生成的注意力转移到其他单词,例如附近的单词,以及句子的结尾。如(Raganato et al,2018)中所述,这意味着生成部分试图找到长期依赖关系,并更多地关注全部信息。
通过将copying任务与生成任务分开,模型的生成部分可以更多地关注“creative”工作。
六、讨论
6.1不同的错误类型的召回率
自动语法错误纠正是一项复杂的任务,因为存在各种错误和不同的纠正方式。在本节中,我们将分析系统在不同语法错误类型上的性能。 (Ng et al,2014)将CoNLL-2014测试集分为28种错误类型,我们在前9种错误类型上列出了召回率。我们在表的最后一行总结了其他19种类型。
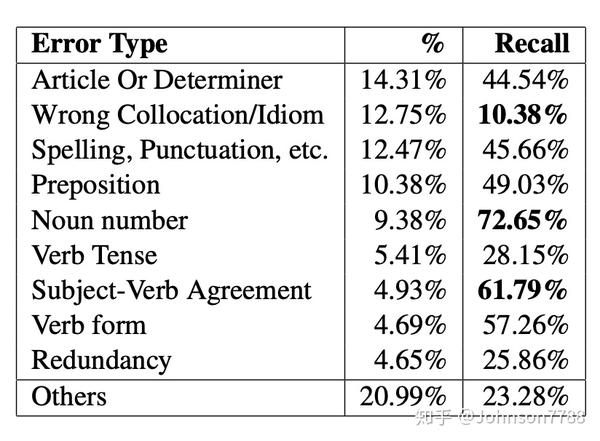

我们的方法的性能是,在“Noun number”类型上,72.65%召回率,在“Subject Verb Agreement”是61.79%召回率。但是,“Wrong Collocation/Idiom”仅10.38%的错误被召回。
计算机善于确定机械错误,但在主观subjective错误和具有文化特征的错误类型上仍与人类有很大差距。
七、相关工作
GEC早期发表的著作为不同的错误类型开发了特定的分类器,然后使用它们来构建混合系统。后来,利用统计机器翻译(SMT)和大规模纠错数据的进展,将GEC系统进一步改进为翻译问题。 SMT系统可以记住基于短语的校正对,但是很难将其泛化到训练中看到的范围之外。 CoNLL14共享任务概述文件(Ng等 2014)对方法进行了比较评估。 (Rozovskaya和Roth 2016年)详细介绍了语法错误纠正问题的分类和机器翻译方法,并结合了这两种方法的优势。
最近,神经机器翻译方法已经显示出非常强大的性能。 (Yannakoudakis et al 2017)开发了一种用于错误检测的神经序列标签模型,以计算句子中每个标签正确或不正确的概率,然后使用错误检测模型的结果作为特征来重新排名N个最佳假设。 (Ji et al。2017)提出了一种混合了单词和字符级别信息的混合神经模型。 (Chollampatt and Ng,2018)使用了多层卷积编码器/解码器神经网络,并且在此任务上优于所有基于现有神经系统和统计系统的系统。 (Junczys-Dowmunt等人 2018)尝试了深度RNN(Barone等人 2017)和transformer(Vaswani等人,2017)编码器解码器模型,并通过使用transformer和一组独立于模型的方法获得了更好的GEC效果。
Ge et al 实现了GEC任务的state-of-the-art最好效果架构,该脚骨基于seq2seq框架和效率提升学习和推理机制。但是他们使用非公共CLC语料库(Nicholls,2003年)和来自Lang-8的自收集的非公共纠错语句对,使它们的训练数据比其他数据大3.6倍,其结果是难以比较的。
八、结论
通过考虑此问题的特征,我们为GEC提供了一种copy-augmented的体系结构。 首先,我们提出了一种增强的copy-augmented架构,该结构通过从源输入中直接copy未更改的单词和 out-of-vocabulary 单词,从而提高了seq2seq模型的能力。其次, 利用降噪自动编码器,使用大规模无标签数据的对copy-augmented架构进行预训练。 第三,我们介绍了两个用于多任务学习的辅助任务。 最后,我们在很大程度上领先于最新的自动语法错误校正系统。 但是,由于GEC问题的复杂性,要使自动GEC系统像人一样可靠,还有很长的路要走。
