
多实例学习-入门篇

多实例学习-入门篇
翻译自
当涉及到在医学领域中应用计算机视觉时,大多数任务涉及到(1)用于诊断的图像分类或者(2)识别和分离病变的分割。然而,在病理学癌症检测中,这并不总是可能的。获取标签既费时又费力。此外,病理切片的分辨率最高可达200000 x 100000像素,并且它们不适合在内存中进行分类,因为例如,ImageNet仅使用224 x 224像素进行训练。下采样通常不是一个选项,因为我们试图检测一个微小的区域,例如从300×300像素区域(图1中的几个点)变化的癌区域。
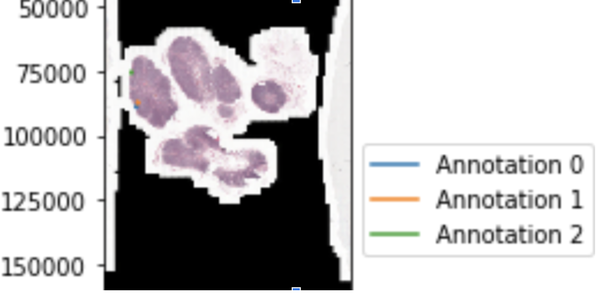
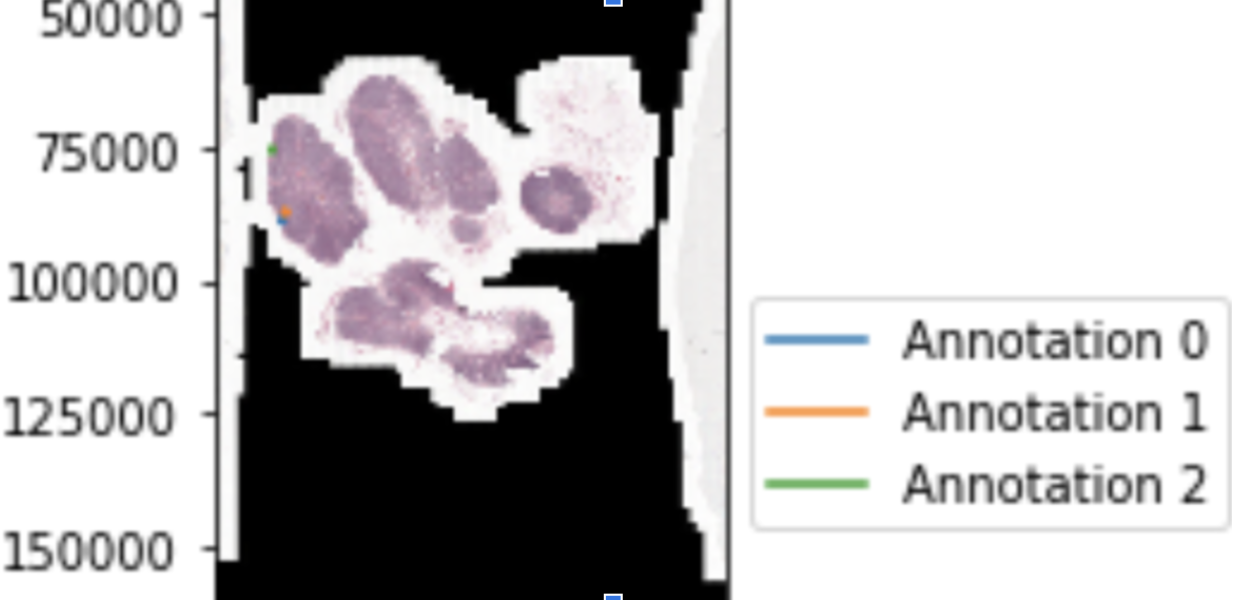
在这种情况下,我们可以使用多实例学习(Multiple Instance Learning),这是一种弱监督学习方法,它采用一组包含许多实例的标记包,而不是接收一组标记实例。
假设我们有病理切片和每张切片的标签。因为我们不能在整个幻灯片上训练分类器,所以我们将每个幻灯片分成小块,在GPU上一次只处理几个小块。然而,我们不知道每个图块的标签,因此我们需要多实例学习。在MIL框架中,幻灯片是“包”,切片是“实例”。通过使用它,我们能够节省标记工作,并利用弱标记数据。
当我们有患者的病理切片时,我们希望预测大切片是否包含癌细胞,或者缩小患者是否有恶性细胞,多实例学习是一个很好的选择,因为医生不需要分割单个细胞或标记每个切片。只有整张幻灯片需要标签。
一般来说,多实例学习可以处理分类问题、回归问题、排序问题和聚类问题,但我们这里主要关注分类问题。
在这篇博客中,我将通过一个基于 MNIST 数据集的简单示例来解释 MIL 如何工作。如果你不熟悉 MNIST 数据集,这里有一个关于 MNIST 数据集的Kaggle 竞赛的链接,你可以看看。
在下一篇博客中,我将详细讨论 MIL 关于乳腺癌挑战 Camelyon17。
MNIST数据集简介
MNIST数据集是一个手写数字的大型数据库,每个图像都有一个从0到9的标签。它有6万张图像的训练集和1万张图像的测试集。每个的尺寸是28 x 28的灰度图。
多实例学习的问题简述
一个袋子里的xi每个实例都有一个标签yi。我们将包的标签定义为: Y = 1,如果存在 yi ==1 Y = 0,如果对于每个yi,yi == 0
在MNIST数据集上应用多元线性回归的流程
作为概述,我们将首先在实例标记的数据集上预训练 ResNet 模型,然后将袋子标记的数据集馈送到模型中并提取特征。最后,我们对它们应用 MIL。
步骤 1:将原始 MNIST 数据集拆分为袋标记集以进行适当的 MIL 训练和实例标记集。
创建 MIL-MNIST 玩具数据集:
MNIST 数据集是分类任务的标准基准。为了使它成为一个 MIL 问题,我们需要首先通过将几个数字(实例)分组到一个包中来构建 MIL-MNIST 数据集。
在我们的 MNIST 示例中,如果一个实例的标签为“1”,我们会将袋子标签分配为“1”;如果除“1”之外的所有实例标签都是“0-9”,那么我们将袋子标签分配为“0”。
如下图所示,红色填充的袋子的袋子标签为“1”,蓝色填充的袋子的袋子标签为“0”。
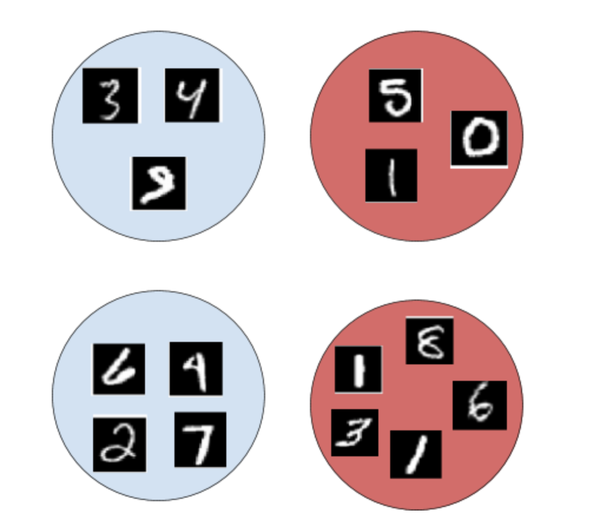
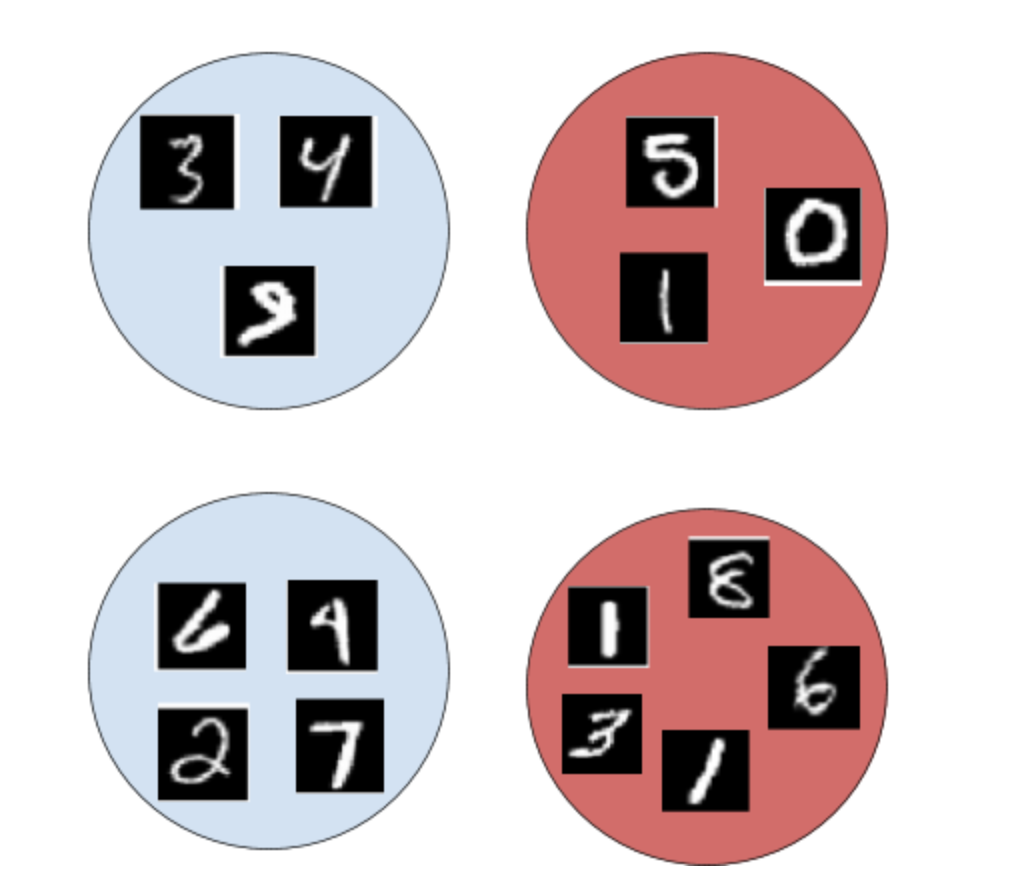
图 3:袋子和实例标签
我们将每个图像随机放入一个包中,每个包包含 3 到 7 个实例。为了节省内存,我们使用索引来表示图像(如下图)。
def data_generation(instance_index_label: List[Tuple]) -> List[Dict]:
"""
bags: {key1: [ind1, ind2, ind3],
key2: [ind1, ind2, ind3, ind4, ind5],
... }
bag_lbls:
{key1: 0,
key2: 1,
... }
"""
bag_size = np.random.randint(3,7,size=len(instance_index_label)//5)
data_cp = copy.copy(instance_index_label)
np.random.shuffle(data_cp)
bags = {}
bags_per_instance_labels = {}
bags_labels = {}
for bag_ind, size in enumerate(bag_size):
bags[bag_ind] = []
bags_per_instance_labels[bag_ind] = []
try:
for _ in range(size):
inst_ind, lbl = data_cp.pop()
bags[bag_ind].append(inst_ind)
# simplfy, just use a temporary variable instead of bags_per_instance_labels
bags_per_instance_labels[bag_ind].append(lbl)
bags_labels[bag_ind] = bag_label_from_instance_labels(bags_per_instance_labels[bag_ind])
except:
break
return bags, bags_labels图 4:生成 MIL-MNIST 数据的代码
生成包标签:
def bag_label_from_instance_labels(instance_labels):
return int(any(((x==1) for x in instance_labels)))图 5:生成袋子标签的代码
第 2 步:对 MNIST 数据集的 2 个部分进行预训练
- 构造一个2D卷积神经网络,kernel_size=(7, 7), stride=(2, 2), padding=(3, 3)
- 训练 5 个 epoch,批大小为 256
- 保存模型
import torch
from torchvision.models.resnet import ResNet, BasicBlock
class MnistResNet(ResNet):
def __init__(self):
super(MnistResNet, self).__init__(BasicBlock, [2, 2, 2, 2], num_classes=10)
self.conv1 = torch.nn.Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
def forward(self, x):
return torch.softmax(super(MnistResNet, self).forward(x), dim=-1)第 3 步:加载预训练模型并从最后一层提取特征
- 将其余数据拆分为训练、验证和测试集
- 获取训练、验证和测试集的特征
- 获取 bag_indices 和 bag_labels
- 使用基于索引的特征映射 bag_indices 并创建 bag_features
为了摆脱最后一层:
model = MnistResNet()
model.load_state_dict(torch.load('mnist_state.pt'))
body = nn.Sequential(*list(model.children()))
# extract the last layer
model = body[:9]
# the model we will use
model.eval()提取特征:
下面的代码展示了我们如何从数据生成函数中获取包索引和包特征:
bag_indices, bag_labels = data_generation(instance_index_label)
bag_features = {kk: torch.Tensor(feature_array[inds]) for kk, inds in bag_indices.items()}图 6:生成包特征的代码
袋子索引、袋子标签和袋子特征如下所示:
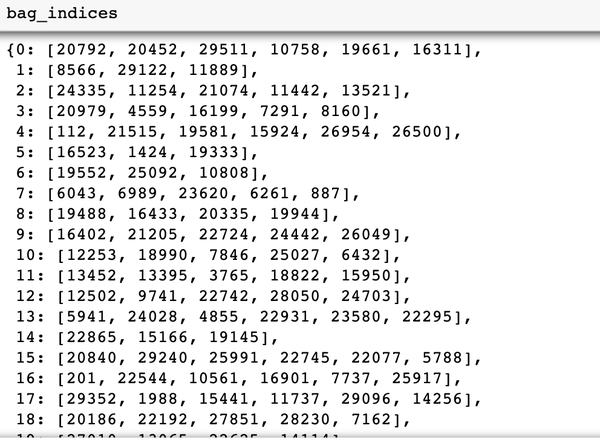
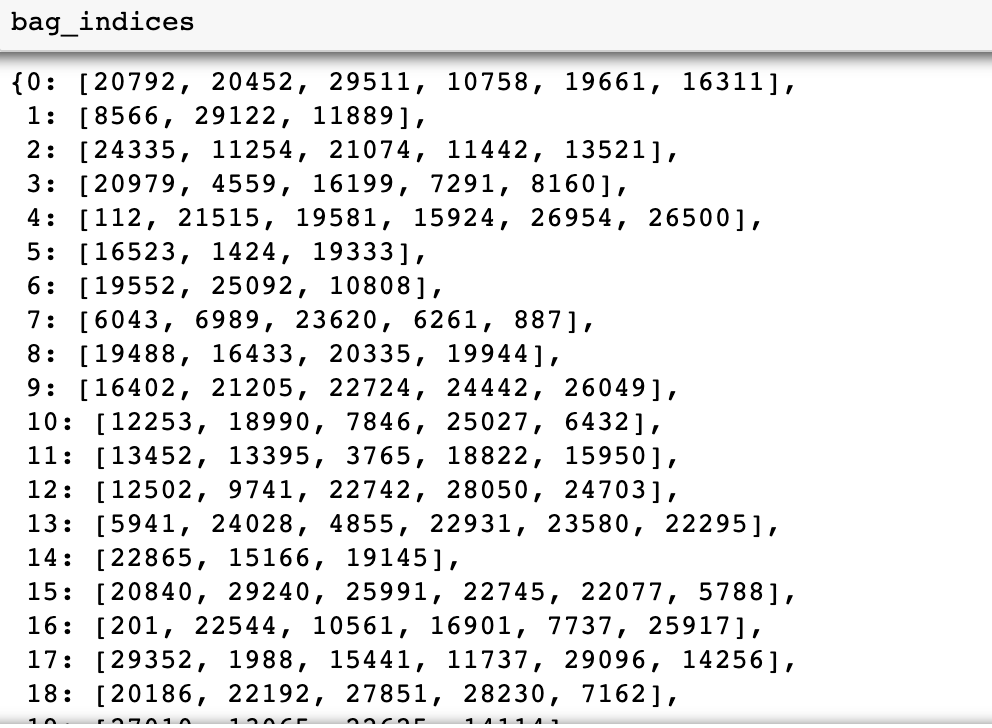
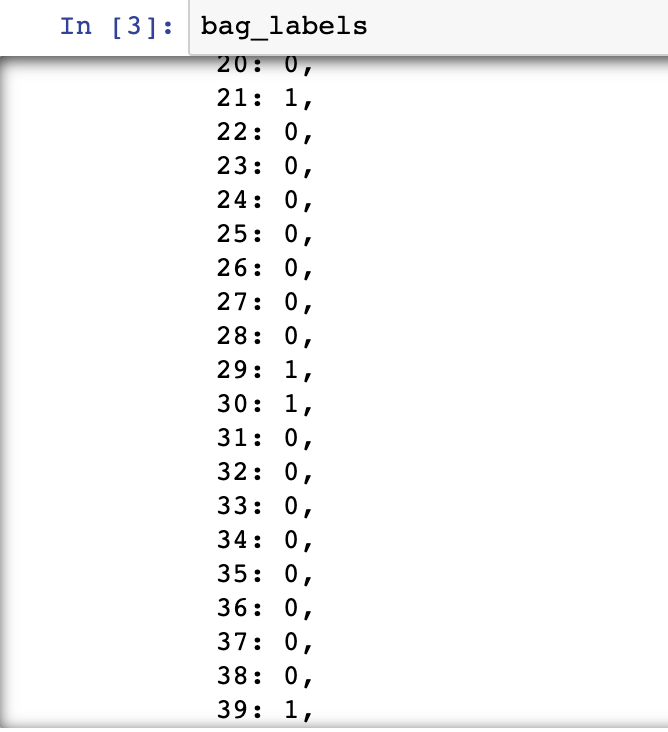
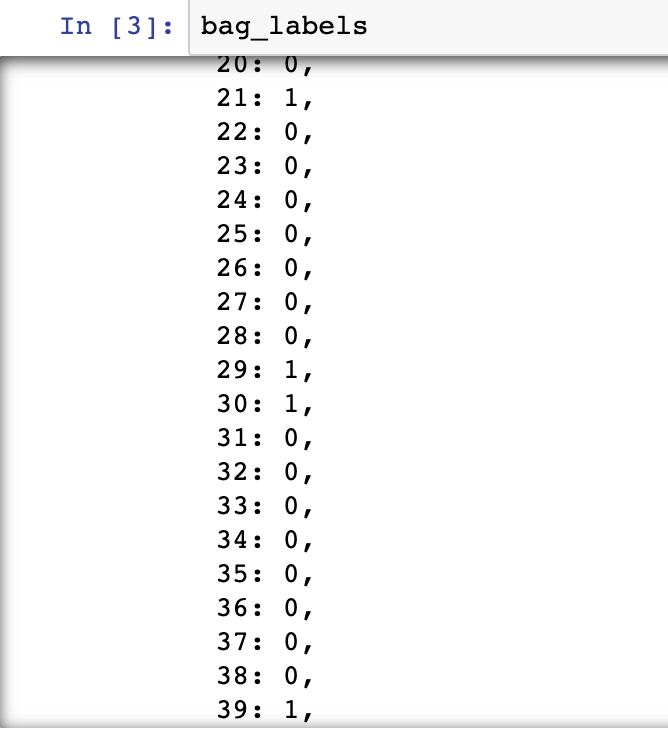


第 4 步:在 bag_features 和 bag_labels 上训练 MIL 模型并在测试集上进行评估
由于每个包都有不同数量的实例,我们需要在将张量放入模型之前将它们填充到相同的大小。
多实例学习模型:
该算法执行三个步骤。它们中的任何一个都可以是固定函数或可优化函数(神经网络):
- 将实例转换为低维嵌入。(固定的)
- 通过置换不变聚合函数传递嵌入。(可优化)
- 转化为包概率。(可优化)

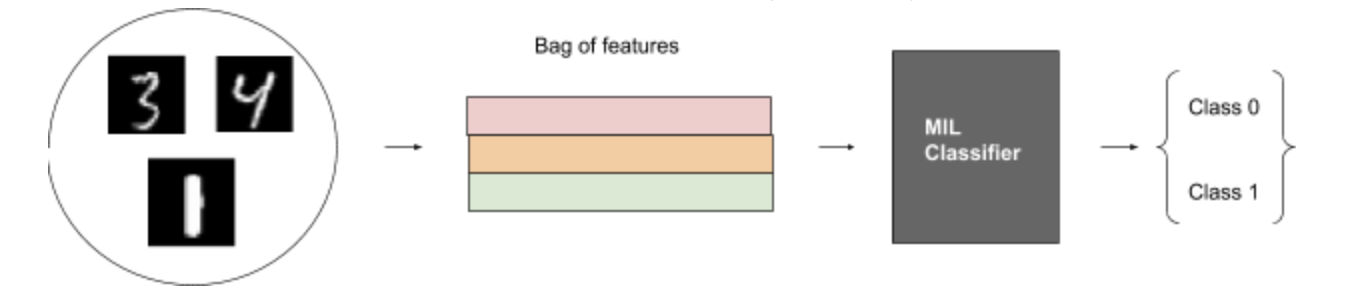
一般来说,工作流程如下:
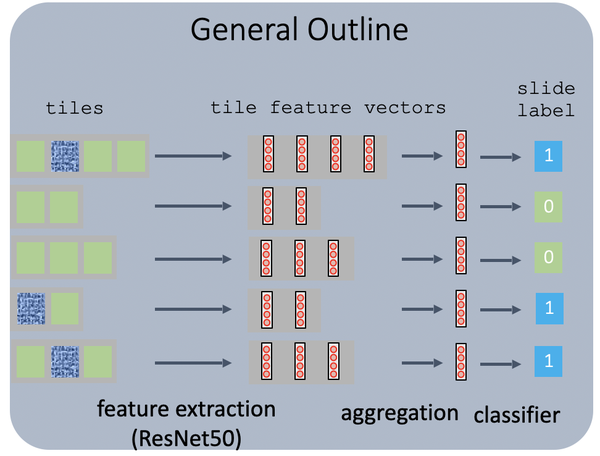
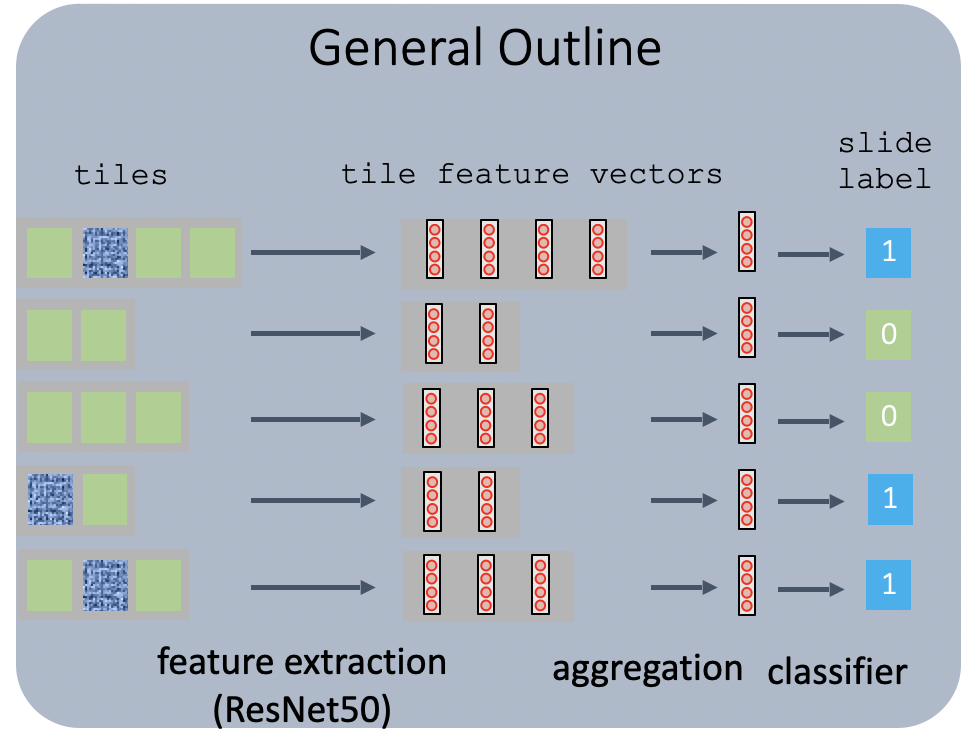
为简单起见,我们将步骤 1 固定为固定。对于第 2 步,虽然我们仍然可以使用固定函数,例如 max 或 mean,但为了启用可以通过反向传播端到端学习的参数优化,我们使用神经网络作为聚合函数。对于第 3 步,我们还希望使用反向传播来优化参数。
- 线性层和 LeakyReLu
class NoisyAnd(torch.nn.Module):
def __init__(self, a=10, dims=[1,2]):
super(NoisyAnd, self).__init__()
# self.output_dim = output_dim
self.a = a
self.b = torch.nn.Parameter(torch.tensor(0.01))
self.dims =dims
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# h_relu = self.linear1(x).clamp(min=0)
mean = torch.mean(x, self.dims, True)
res = (self.sigmoid(self.a * (mean - self.b)) - self.sigmoid(-self.a * self.b)) / (
self.sigmoid(self.a * (1 - self.b)) - self.sigmoid(-self.a * self.b))
return res
class NN(torch.nn.Module):
def __init__(self, n=512, n_mid = 1024,
n_out=1, dropout=0.2,
scoring = None,
):
super(NN, self).__init__()
self.linear1 = torch.nn.Linear(n, n_mid)
self.non_linearity = torch.nn.LeakyReLU()
self.linear2 = torch.nn.Linear(n_mid, n_out)
self.dropout = torch.nn.Dropout(dropout)
if scoring:
self.scoring = scoring
else:
self.scoring = torch.nn.Softmax() if n_out>1 else torch.nn.Sigmoid()
def forward(self, x):
z = self.linear1(x)
z = self.non_linearity(z)
z = self.dropout(z)
z = self.linear2(z)
y_pred = self.scoring(z)
return y_pred
class LogisticRegression(torch.nn.Module):
def __init__(self, n=512, n_out=1):
super(LogisticRegression, self).__init__()
self.linear = torch.nn.Linear(n, n_out)
self.scoring = torch.nn.Softmax() if n_out>1 else torch.nn.Sigmoid()
def forward(self, x):
z = self.linear(x)
y_pred = self.scoring(z)
return y_pred
def regularization_loss(params,
reg_factor = 0.005,
reg_alpha = 0.5):
params = [pp for pp in params if len(pp.shape)>1]
l1_reg = nn.L1Loss()
l2_reg = nn.MSELoss()
loss_reg =0
for pp in params:
loss_reg+=reg_factor*((1-reg_alpha)*l1_reg(pp, target=torch.zeros_like(pp)) +\
reg_alpha*l2_reg(pp, target=torch.zeros_like(pp)))
return loss_reg注意:我们设置 n = 7*512,其中 7 是一个包中的实例数,512 是每个特征的大小。
- 聚合函数:AttensionSoftmax
class SoftMaxMeanSimple(torch.nn.Module):
def __init__(self, n, n_inst, dim=0):
"""
if dim==1:
given a tensor `x` with dimensions [N * M],
where M -- dimensionality of the featur vector
(number of features per instance)
N -- number of instances
initialize with `AggModule(M)`
returns:
- weighted result: [M]
- gate: [N]
if dim==0:
...
"""
super(SoftMaxMeanSimple, self).__init__()
self.dim = dim
self.gate = torch.nn.Softmax(dim=self.dim)
self.mdl_instance_transform = nn.Sequential(
nn.Linear(n, n_inst),
nn.LeakyReLU(),
nn.Linear(n_inst, n),
nn.LeakyReLU(),
)
def forward(self, x):
z = self.mdl_instance_transform(x)
if self.dim==0:
z = z.view((z.shape[0],1)).sum(1)
elif self.dim==1:
z = z.view((1, z.shape[1])).sum(0)
gate_ = self.gate(z)
res = torch.sum(x* gate_, self.dim)
return res, gate_
class AttentionSoftMax(torch.nn.Module):
def __init__(self, in_features = 3, out_features = None):
"""
given a tensor `x` with dimensions [N * M],
where M -- dimensionality of the featur vector
(number of features per instance)
N -- number of instances
initialize with `AggModule(M)`
returns:
- weighted result: [M]
- gate: [N]
"""
super(AttentionSoftMax, self).__init__()
self.otherdim = ''
if out_features is None:
out_features = in_features
self.layer_linear_tr = nn.Linear(in_features, out_features)
self.activation = nn.LeakyReLU()
self.layer_linear_query = nn.Linear(out_features, 1)
def forward(self, x):
keys = self.layer_linear_tr(x)
keys = self.activation(keys)
attention_map_raw = self.layer_linear_query(keys)[...,0]
attention_map = nn.Softmax(dim=-1)(attention_map_raw)
result = torch.einsum(f'{self.otherdim}i,{self.otherdim}ij->{self.otherdim}j', attention_map, x)
return result, attention_map- 中间以LeakyReLu为激活函数,dropout,sigmoid为最终激活函数的神经网络:
class MIL_NN(torch.nn.Module):
def __init__(self, n=512,
n_mid=1024,
n_classes=1,
dropout=0.1,
agg = None,
scoring=None,
):
super(MIL_NN, self).__init__()
self.agg = agg if agg is not None else AttentionSoftMax(n)
if n_mid == 0:
self.bag_model = LogisticRegression(n, n_classes)
else:
self.bag_model = NN(n, n_mid, n_classes, dropout=dropout, scoring=scoring)
def forward(self, bag_features, bag_lbls=None):
"""
bag_feature is an aggregated vector of 512 features
bag_att is a gate vector of n_inst instances
bag_lbl is a vector a labels
figure out batches
"""
bag_feature, bag_att, bag_keys = list(zip(*[list(self.agg(ff.float())) + [idx]
for idx, ff in (bag_features.items())]))
bag_att = dict(zip(bag_keys, [a.detach().cpu() for a in bag_att]))
bag_feature_stacked = torch.stack(bag_feature)
y_pred = self.bag_model(bag_feature_stacked)
return y_pred, bag_att, bag_keys- 优化器:SGD
- 损失函数:BCELoss
- 准确度:~0.99
结论:
我们使用 MIL 在 MNIST 数据集上获得了大约 0.99 的准确率,这是一个令人满意的结果。如果我们愿意,我们可以使用更复杂的聚合函数作为我们的中间转换,并构建更复杂的 NN 模型用于最终转换到包级别。结果还表明,MIL 是一个很好的工具,可以节省标记工作并利用弱标记数据。
Jupyter 笔记本演示链接:
https://github.com/lsheng23/Practicum/blob/master/MIL_MNIST/end_to_end_mnist_MIL.ipynb
# -*- coding: utf-8 -*-
"""end_to_end_mnist_MIL.ipynb
Automatically generated by Colaboratory.
Original file is located at
https://colab.research.google.com/github/lsheng23/Practicum/blob/master/MIL_MNIST/end_to_end_mnist_MIL.ipynb
"""
import os
import datetime
import copy
import re
import yaml
import uuid
import warnings
import time
import inspect
import numpy as np
import pandas as pd
from functools import partial, reduce
from random import shuffle
import random
import torch
from torch import nn, optim
from torch import nn
from torch.nn import functional as F
from torch.utils.data.dataset import Dataset
from torch.utils.data import DataLoader
from torch.utils.data import DataLoader
from torchvision.models import resnet
from torchvision.transforms import Compose, ToTensor, Normalize, Resize
from torchvision.models.resnet import ResNet, BasicBlock
from torchvision.datasets import MNIST
import tensorflow as tf
from tqdm.autonotebook import tqdm
from sklearn.metrics import precision_score, recall_score, f1_score, accuracy_score
from sklearn import metrics as mtx
from sklearn import model_selection as ms
"""> # 1. Pretrain"""
def get_data_loaders(train_batch_size, val_batch_size):
mnist = MNIST(download=True, train=True, root=".").train_data.float()
data_transform = Compose([ Resize((224, 224)),ToTensor(), Normalize((mnist.mean()/255,), (mnist.std()/255,))])
train_loader = DataLoader(MNIST(download=True, root=".", transform=data_transform, train=True),
batch_size=train_batch_size, shuffle=True)
val_loader = DataLoader(MNIST(download=False, root=".", transform=data_transform, train=False),
batch_size=val_batch_size, shuffle=False)
return train_loader, val_loader
train_batch_size = 256
val_batch_size = 256
train_loader, valid_loader = get_data_loaders(train_batch_size, val_batch_size)
"""> ### 1.1 define model"""
class MnistResNet(ResNet):
def __init__(self):
super(MnistResNet, self).__init__(BasicBlock, [2, 2, 2, 2], num_classes=10)
self.conv1 = torch.nn.Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
def forward(self, x):
return torch.softmax(super(MnistResNet, self).forward(x), dim=-1)
"""> ### 1.2 helper function"""
def calculate_metric(metric_fn, true_y, pred_y):
# multi class problems need to have averaging method
if "average" in inspect.getfullargspec(metric_fn).args:
return metric_fn(true_y, pred_y, average="macro")
else:
return metric_fn(true_y, pred_y)
def print_scores(p, r, f1, a, batch_size):
# just an utility printing function
for name, scores in zip(("precision", "recall", "F1", "accuracy"), (p, r, f1, a)):
print(f"\t{name.rjust(14, ' ')}: {sum(scores)/batch_size:.4f}")
"""> ### 1.3 train"""
start_ts = time.time()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# model:
model = MnistResNet().to(device)
# params you need to specify:
epochs = 5
train_loader, val_loader = get_data_loaders(train_batch_size, val_batch_size)
loss_function = nn.CrossEntropyLoss() # your loss function, cross entropy works well for multi-class problems
# optimizer, I've used Adadelta, as it wokrs well without any magic numbers
optimizer = optim.Adadelta(model.parameters())
losses = []
batches = len(train_loader)
val_batches = len(val_loader)
# loop for every epoch (training + evaluation)
for epoch in range(epochs):
total_loss = 0
# progress bar (works in Jupyter notebook too!)
progress = tqdm(enumerate(train_loader), desc="Loss: ", total=batches)
# ----------------- TRAINING --------------------
# set model to training
model.train()
for i, data in progress:
X, y = data[0].to(device), data[1].to(device)
# training step for single batch
model.zero_grad() # to make sure that all the grads are 0
"""
model.zero_grad() and optimizer.zero_grad() are the same
IF all your model parameters are in that optimizer.
I found it is safer to call model.zero_grad() to make sure all grads are zero,
e.g. if you have two or more optimizers for one model.
"""
outputs = model(X) # forward
loss = loss_function(outputs, y) # get loss
loss.backward() # accumulates the gradient (by addition) for each parameter.
optimizer.step() # performs a parameter update based on the current gradient
# getting training quality data
current_loss = loss.item()
total_loss += current_loss
# updating progress bar
progress.set_description("Loss: {:.4f}".format(total_loss/(i+1)))
# releasing unceseccary memory in GPU
if torch.cuda.is_available():
torch.cuda.empty_cache()
# ----------------- VALIDATION -----------------
val_losses = 0
precision, recall, f1, accuracy = [], [], [], []
# set model to evaluating (testing)
model.eval()
with torch.no_grad():
for i, data in enumerate(val_loader):
X, y = data[0].to(device), data[1].to(device)
outputs = model(X) # this get's the prediction from the network
val_losses += loss_function(outputs, y)
predicted_classes = torch.max(outputs, 1)[1] # get class from network's prediction
# calculate P/R/F1/A metrics for batch
for acc, metric in zip((precision, recall, f1, accuracy),
(precision_score, recall_score, f1_score, accuracy_score)):
acc.append(
calculate_metric(metric, y.cpu(), predicted_classes.cpu())
)
print(f"Epoch {epoch+1}/{epochs}, training loss: {total_loss/batches}, validation loss: {val_losses/val_batches}")
print_scores(precision, recall, f1, accuracy, val_batches)
losses.append(total_loss/batches) # for plotting learning curve
print(f"Training time: {time.time()-start_ts}s")
"""> ### 1.4 save model"""
torch.save(model.state_dict(), 'mnist_state.pt')
"""> # 2. Data Generation
> ### 2.1 load data
"""
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train.shape
x_train = x_train[:30001]
y_train = y_train[:30001]
x_test = x_test[:9000]
y_test = y_test[:9000]
# Making sure that the values are float so that we can get decimal points after division
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
# Normalizing the RGB codes by dividing it to the max RGB value.
x_train /= 255
x_test /= 255
print('x_train shape:', x_train.shape)
print('Number of images in x_train', x_train.shape[0])
print('Number of images in x_test', x_test.shape[0])
"""> ### 2.2 Create tuple (index, label) for train and test"""
instance_index_label = [(i, y_train[i]) for i in range(x_train.shape[0])]
instance_index_label_test = [(i, y_test[i]) for i in range(x_test.shape[0])]
# find the index if label is 1
find_index = [instance_index_label[i][0] for i in range(len(instance_index_label)) if instance_index_label[i][1]==1]
# find the index if label is 1
find_index_test = [instance_index_label_test[i][0] for i in range(len(instance_index_label_test))
if instance_index_label_test[i][1]==1]
print('index:', instance_index_label[0][0]) #index
print('label:', instance_index_label[0][1]) #label
"""> ### 2.3 load pretrained model"""
import torch
from torchvision.models.resnet import ResNet, BasicBlock
class MnistResNet(ResNet):
def __init__(self):
super(MnistResNet, self).__init__(BasicBlock, [2, 2, 2, 2], num_classes=10)
self.conv1 = torch.nn.Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
def forward(self, x):
return torch.softmax(super(MnistResNet, self).forward(x), dim=-1)
model = MnistResNet()
model.load_state_dict(torch.load('mnist_state.pt'))
body = nn.Sequential(*list(model.children()))
# extract the last layer
model = body[:9]
# the model we will use
model.eval()
"""> ### 2.4 get features"""
train_batch_size = 1
val_batch_size = 1
train_loader, val_loader = get_data_loaders(train_batch_size, val_batch_size)
loss_function = nn.CrossEntropyLoss() # your loss function, cross entropy works well for multi-class problems
# optimizer
optimizer = optim.Adadelta(model.parameters())
losses = []
batches = len(train_loader)
val_batches = len(val_loader)
"""> #### 2.4.1 get features for train"""
# loop for every epoch (training + evaluation)
meta_table = dict()
feature_result = []
# progress bar
progress = tqdm(enumerate(train_loader), desc="Loss: ", total=batches)
model.eval()
for i, data in progress:
if i==30001:
break
X, y = data[0], data[1]
# training step for single batch
model.zero_grad()
outputs = model(X)
feature_result.append(outputs.reshape(-1).tolist())
meta_table[i] = outputs.reshape(-1).tolist()
feature_array = np.array(feature_result)
np.save('feature_array_full',feature_array )
# load
feature_array = np.load('feature_array.npy', allow_pickle=True)
"""> #### 2.4.2 get features for test"""
# loop for every epoch (training + evaluation)
meta_t_table = dict()
feature_t_result = []
# progress bar
progress = tqdm(enumerate(val_loader), desc="Loss: ", total=batches)
model.eval()
for i, data in progress:
if i==9000:
break
X, y = data[0], data[1]
# training step for single batch
model.zero_grad()
outputs_t = model(X)
feature_t_result.append(outputs_t.reshape(-1).tolist())
meta_t_table[i] = outputs_t.reshape(-1).tolist()
feature_test_array = np.array(feature_t_result)
# save
np.save('feature_test_array_full',feature_test_array )
#load
feature_test_array = np.load('feature_t_array.npy', allow_pickle=True)
"""> ### 2.5 generate data
> #### 2.5.1 generate data for train
"""
from typing import List, Dict, Tuple
def data_generation(instance_index_label: List[Tuple]) -> List[Dict]:
"""
bags: {key1: [ind1, ind2, ind3],
key2: [ind1, ind2, ind3, ind4, ind5],
... }
bag_lbls:
{key1: 0,
key2: 1,
... }
"""
bag_size = np.random.randint(3,7,size=len(instance_index_label)//5)
data_cp = copy.copy(instance_index_label)
np.random.shuffle(data_cp)
bags = {}
bags_per_instance_labels = {}
bags_labels = {}
for bag_ind, size in enumerate(bag_size):
bags[bag_ind] = []
bags_per_instance_labels[bag_ind] = []
try:
for _ in range(size):
inst_ind, lbl = data_cp.pop()
bags[bag_ind].append(inst_ind)
# simplfy, just use a temporary variable instead of bags_per_instance_labels
bags_per_instance_labels[bag_ind].append(lbl)
bags_labels[bag_ind] = bag_label_from_instance_labels(bags_per_instance_labels[bag_ind])
except:
break
return bags, bags_labels
def bag_label_from_instance_labels(instance_labels):
return int(any(((x==1) for x in instance_labels)))
bag_indices, bag_labels = data_generation(instance_index_label)
bag_features = {kk: torch.Tensor(feature_array[inds]) for kk, inds in bag_indices.items()}
# save
import pickle
pickle.dump(bag_indices, open( "bag_indices", "wb" ) )
pickle.dump(bag_labels, open( "bag_labels", "wb" ) )
pickle.dump(bag_features, open( "bag_features", "wb" ) )
import pickle
bag_indices = pickle.load( open( "bag_indices", "rb" ) )
bag_labels = pickle.load( open( "bag_labels", "rb" ) )
bag_features = pickle.load( open( "bag_features", "rb" ) )
"""> #### 2.5.2 generate data for test"""
bag_t_indices, bag_t_labels = data_generation(instance_index_label_test)
bag_t_features = {kk: torch.Tensor(feature_test_array[inds]) for kk, inds in bag_t_indices.items()}
pickle.dump(bag_t_indices, open( "bag_t_indices", "wb" ) )
pickle.dump(bag_t_labels, open( "bag_t_labels", "wb" ) )
pickle.dump(bag_t_features, open( "bag_t_features", "wb" ) )
bag_t_indices = pickle.load( open( "bag_t_indices", "rb" ) )
bag_t_labels = pickle.load( open( "bag_t_labels", "rb" ) )
bag_t_features = pickle.load( open( "bag_t_features", "rb" ) )
"""> # 3. Multiple Instance Learning
> ### 3.1 Prepare data for model
"""
from torch.utils.data import Dataset
class Transform_data(Dataset):
"""
We want to 1. pad tensor 2. transform the data to the size that fits in the input size.
"""
def __init__(self, data, transform=None):
self.transform = transform
self.data = data
def __getitem__(self, index):
tensor = self.data[index][0]
if self.transform is not None:
tensor = self.transform(tensor)
return (tensor, self.data[index][1])
def __len__(self):
return len(self.data)
train_data = [(bag_features[i],bag_labels[i]) for i in range(len(bag_features))]
bag_features[0]
def pad_tensor(data:list, max_number_instance) -> list:
"""
Since our bag has different sizes, we need to pad each tensor to have the same shape (max: 7).
We will look through each one instance and look at the shape of the tensor, and then we will pad 7-n
to the existing tensor where n is the number of instances in the bag.
The function will return a padded data set."""
new_data = []
for bag_index in range(len(data)):
tensor_size = len(data[bag_index][0])
pad_size = max_number_instance - tensor_size
p2d = (0,0, 0, pad_size)
padded = nn.functional.pad(data[bag_index][0], p2d, 'constant', 0)
new_data.append((padded, data[bag_index][1]))
return new_data
max_number_instance = 7
padded_train = pad_tensor(train_data, max_number_instance)
test_data = [(bag_t_features[i],bag_t_labels[i]) for i in range(len(bag_t_features))]
padded_test = pad_tensor(test_data, max_number_instance)
def get_data_loaders(train_data, test_data, train_batch_size, val_batch_size):
train_loader = DataLoader(train_data, batch_size=train_batch_size, shuffle=True)
val_loader = DataLoader(test_data, batch_size=val_batch_size, shuffle=False)
return train_loader, val_loader
train_loader,valid_loader = get_data_loaders(padded_train, padded_test, 1, 1)
train_batch_size = 1
val_batch_size = 1
"""> ### 3.2 Define model
> #### 3.2.1 Aggregation Funtion model
"""
# aggregation functions
class SoftMaxMeanSimple(torch.nn.Module):
def __init__(self, n, n_inst, dim=0):
"""
if dim==1:
given a tensor `x` with dimensions [N * M],
where M -- dimensionality of the featur vector
(number of features per instance)
N -- number of instances
initialize with `AggModule(M)`
returns:
- weighted result: [M]
- gate: [N]
if dim==0:
...
"""
super(SoftMaxMeanSimple, self).__init__()
self.dim = dim
self.gate = torch.nn.Softmax(dim=self.dim)
self.mdl_instance_transform = nn.Sequential(
nn.Linear(n, n_inst),
nn.LeakyReLU(),
nn.Linear(n_inst, n),
nn.LeakyReLU(),
)
def forward(self, x):
z = self.mdl_instance_transform(x)
if self.dim==0:
z = z.view((z.shape[0],1)).sum(1)
elif self.dim==1:
z = z.view((1, z.shape[1])).sum(0)
gate_ = self.gate(z)
res = torch.sum(x* gate_, self.dim)
return res, gate_
class AttentionSoftMax(torch.nn.Module):
def __init__(self, in_features = 3, out_features = None):
"""
given a tensor `x` with dimensions [N * M],
where M -- dimensionality of the featur vector
(number of features per instance)
N -- number of instances
initialize with `AggModule(M)`
returns:
- weighted result: [M]
- gate: [N]
"""
super(AttentionSoftMax, self).__init__()
self.otherdim = ''
if out_features is None:
out_features = in_features
self.layer_linear_tr = nn.Linear(in_features, out_features)
self.activation = nn.LeakyReLU()
self.layer_linear_query = nn.Linear(out_features, 1)
def forward(self, x):
keys = self.layer_linear_tr(x)
keys = self.activation(keys)
attention_map_raw = self.layer_linear_query(keys)[...,0]
attention_map = nn.Softmax(dim=-1)(attention_map_raw)
result = torch.einsum(f'{self.otherdim}i,{self.otherdim}ij->{self.otherdim}j', attention_map, x)
return result, attention_map
"""> #### 3.3.2 MIL_NN model"""
class NoisyAnd(torch.nn.Module):
def __init__(self, a=10, dims=[1,2]):
super(NoisyAnd, self).__init__()
# self.output_dim = output_dim
self.a = a
self.b = torch.nn.Parameter(torch.tensor(0.01))
self.dims =dims
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# h_relu = self.linear1(x).clamp(min=0)
mean = torch.mean(x, self.dims, True)
res = (self.sigmoid(self.a * (mean - self.b)) - self.sigmoid(-self.a * self.b)) / (
self.sigmoid(self.a * (1 - self.b)) - self.sigmoid(-self.a * self.b))
return res
class NN(torch.nn.Module):
def __init__(self, n=512, n_mid = 1024,
n_out=1, dropout=0.2,
scoring = None,
):
super(NN, self).__init__()
self.linear1 = torch.nn.Linear(n, n_mid)
self.non_linearity = torch.nn.LeakyReLU()
self.linear2 = torch.nn.Linear(n_mid, n_out)
self.dropout = torch.nn.Dropout(dropout)
if scoring:
self.scoring = scoring
else:
self.scoring = torch.nn.Softmax() if n_out>1 else torch.nn.Sigmoid()
def forward(self, x):
z = self.linear1(x)
z = self.non_linearity(z)
z = self.dropout(z)
z = self.linear2(z)
y_pred = self.scoring(z)
return y_pred
class LogisticRegression(torch.nn.Module):
def __init__(self, n=512, n_out=1):
super(LogisticRegression, self).__init__()
self.linear = torch.nn.Linear(n, n_out)
self.scoring = torch.nn.Softmax() if n_out>1 else torch.nn.Sigmoid()
def forward(self, x):
z = self.linear(x)
y_pred = self.scoring(z)
return y_pred
def regularization_loss(params,
reg_factor = 0.005,
reg_alpha = 0.5):
params = [pp for pp in params if len(pp.shape)>1]
l1_reg = nn.L1Loss()
l2_reg = nn.MSELoss()
loss_reg =0
for pp in params:
loss_reg+=reg_factor*((1-reg_alpha)*l1_reg(pp, target=torch.zeros_like(pp)) +\
reg_alpha*l2_reg(pp, target=torch.zeros_like(pp)))
return loss_reg
class MIL_NN(torch.nn.Module):
def __init__(self, n=512,
n_mid=1024,
n_classes=1,
dropout=0.1,
agg = None,
scoring=None,
):
super(MIL_NN, self).__init__()
self.agg = agg if agg is not None else AttentionSoftMax(n)
if n_mid == 0:
self.bag_model = LogisticRegression(n, n_classes)
else:
self.bag_model = NN(n, n_mid, n_classes, dropout=dropout, scoring=scoring)
def forward(self, bag_features, bag_lbls=None):
"""
bag_feature is an aggregated vector of 512 features
bag_att is a gate vector of n_inst instances
bag_lbl is a vector a labels
figure out batches
"""
bag_feature, bag_att, bag_keys = list(zip(*[list(self.agg(ff.float())) + [idx]
for idx, ff in (bag_features.items())]))
bag_att = dict(zip(bag_keys, [a.detach().cpu() for a in bag_att]))
bag_feature_stacked = torch.stack(bag_feature)
y_pred = self.bag_model(bag_feature_stacked)
return y_pred, bag_att, bag_keys
"""> #### 3.3.3 helper function"""
def calculate_metric(metric_fn, true_y, pred_y):
# multi class problems need to have averaging method
if "average" in inspect.getfullargspec(metric_fn).args:
return metric_fn(true_y, pred_y, average="macro")
else:
return metric_fn(true_y, pred_y)
def print_scores(p, r, f1, a, batch_size):
# just an utility printing function
for name, scores in zip(("precision", "recall", "F1", "accuracy"), (p, r, f1, a)):
print(f"\t{name.rjust(14, ' ')}: {sum(scores)/batch_size:.4f}")
"""> # 4. Train & Test"""
import numpy as np
start_ts = time.time()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
lr0 = 1e-4
# model:
model = MIL_NN().to(device)
# params you need to specify:
epochs = 10
train_loader, val_loader = get_data_loaders(padded_train, padded_test, 1, 1)
loss_function = torch.nn.BCELoss(reduction='mean') # your loss function, cross entropy works well for multi-class problems
#optimizer = optim.Adadelta(model.parameters())
optimizer = optim.SGD(model.parameters(), lr=lr0, momentum=0.9)
losses = []
batches = len(train_loader)
val_batches = len(val_loader)
# loop for every epoch (training + evaluation)
for epoch in range(epochs):
total_loss = 0
# progress bar (works in Jupyter notebook too!)
progress = tqdm(enumerate(train_loader), desc="Loss: ", total=batches)
# ----------------- TRAINING --------------------
# set model to training
model.train()
for i, data in progress:
X, y = data[0].to(device), data[1].to(device)
X = X.reshape([1,7*512])
y = y.type(torch.cuda.FloatTensor)
# training step for single batch
model.zero_grad() # to make sure that all the grads are 0
"""
model.zero_grad() and optimizer.zero_grad() are the same
IF all your model parameters are in that optimizer.
I found it is safer to call model.zero_grad() to make sure all grads are zero,
e.g. if you have two or more optimizers for one model.
"""
outputs = model(X) # forward
loss = loss_function(outputs, y) # get loss
loss.backward() # accumulates the gradient (by addition) for each parameter.
optimizer.step() # performs a parameter update based on the current gradient
# getting training quality data
current_loss = loss.item()
total_loss += current_loss
# updating progress bar
progress.set_description("Loss: {:.4f}".format(total_loss/(i+1)))
# releasing unceseccary memory in GPU
if torch.cuda.is_available():
torch.cuda.empty_cache()
# ----------------- VALIDATION -----------------
val_losses = 0
precision, recall, f1, accuracy = [], [], [], []
# set model to evaluating (testing)
model.eval()
with torch.no_grad():
for i, data in enumerate(val_loader):
X, y = data[0].to(device), data[1].to(device)
X = X.reshape([1,7*512])
y = y.type(torch.cuda.FloatTensor)
outputs = model(X) # this get's the prediction from the network
prediced_classes =outputs.detach().round()
#y_pred.extend(prediced_classes.tolist())
val_losses += loss_function(outputs, y)
# calculate P/R/F1/A metrics for batch
for acc, metric in zip((precision, recall, f1, accuracy),
(precision_score, recall_score, f1_score, accuracy_score)):
acc.append(
calculate_metric(metric, y.cpu(), prediced_classes.cpu())
)
print(f"Epoch {epoch+1}/{epochs}, training loss: {total_loss/batches}, validation loss: {val_losses/val_batches}")
print_scores(precision, recall, f1, accuracy, val_batches)
losses.append(total_loss/batches) # for plotting learning curve
print(f"Training time: {time.time()-start_ts}s")参考:
[1] Ilse, Maximilian, et al. “Attention-Based Deep Multiple Instance Learning.” http://ArXiv.org, 28 June 2018, https://arxiv.org/abs/1802.04712.
[2] Carbonneau, Marc-André, et al. “Multiple Instance Learning: A Survey of Problem Characteristics and Applications.” http://ArXiv.org, 11 Dec. 2016, https://arxiv.org/abs/1612.03365.
[3] LeCun, Yann, et al. “THE MNIST DATABASE.” MNIST Handwritten Digit Database, Yann LeCun, Corinna Cortes, and Chris Burges, http://yann.lecun.com/exdb/mnist/.
[4] https://www.researchgate.net/figure/Example-images-from-the-MNIST-dataset_fig1_306056875
[5] Dmytro S Lituiev, Sung Jik Cha, Andrew Bishara, Jae Ho Sohn, Eugenia Rutenberg, Dexter Hadley, Zoltan Laszik. “A Deep Learning Model for Identifying Rejection in Transplant Kidney Biopsies”. Poster presentation at USCAP 2020, Los Angeles
