
集成学习介绍

那什么是集成学习呢,其实集成学习就是我一个模型解决不了这个问题,那我就使用很多模型一起来解决这个问题,就好像我一个人打不过你,我来找一帮人来揍你,集成学习就是这么干的,哇,感觉很多东西都是相通的呀,哈哈哈。集成学习是包含很多方法的,下面介绍一下其中比较经典的方法:
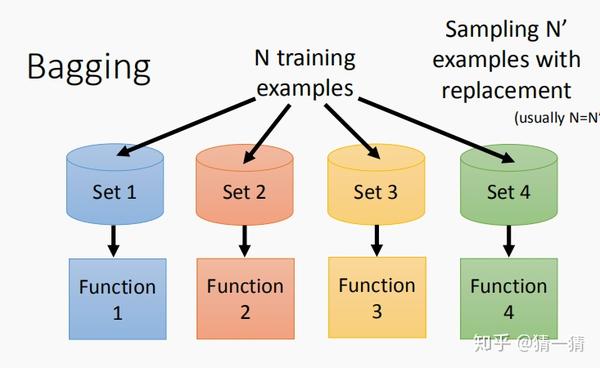

集成学习中的一个方法就是Bagging,Bagging要解决的是方差大的问题,也就是说,由于每一个模型比较复杂,那这样的模型方差就比较大,容易出现过拟合的问题,为了解决这个问题,就使用Bagging的方法,将多个这样的模型联合起来,然后将最后的结果求平均(如果是回归问题)或者进行投票(如果是分类问题)。具体是怎么做的呢,上图中给了一个非常清晰的介绍。其实就是从N个训练样本中进行有放回的抽样,得到样本数为 N^{'} 的训练集Set,通常 N_{} = N^{'} ,然后利用这些数据集分别训练一个模型,然后将训练好的模型的输出结果进行平均或投票,下面这张图说的更为清楚些:
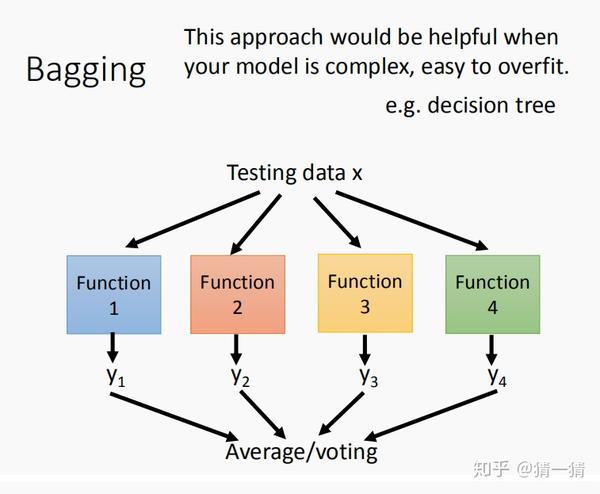

使用Bagging的一个案例就是随机森林,因为决策树容易出现过拟合的情况,也就是方差比较大,为了解决这个问题就使用了Bagging的方法,让很多决策树组成了随机森林,这样就能很好的解决方差大的问题。一个模型方差比较大,那我就联合多个这样的模型,经过联合后的模型方差就比较小了,就不会出现过拟合情况了,Bagging就是干这样的事。下面介绍一下集成学习中的另一个方法那就是Boosting,请看下图:


Boosting与Bagging是不一样的,Boosting做的是将多个比较弱的模型联合起来,联合起来后模型就变得比较强了,有一句话非常适合Boosting干的事,那就是三个臭皮匠,顶个诸葛亮。我每一个模型都比较菜,但是我用Boosting的方法联合起来就比较强了。上图中说的内容为,Boosting有一个很强的保证就是,如果单个模型在训练集上的错误率是小于50%,那我用Boosting的方法,能获得错误率为零模型,错误率为零我的理解是在训练数据集上的错误率。而且每一个训练出的模型不能是相似的,要是互补的,和Bagging不同的是每个模型都是按一定顺序找出的,而Bagging并不需要按顺序找到各个模型。Boosting是有很多方方法的,其中最经典的就是Adaboost,那下面我们看下Adaboost是如何找到这些互补的模型。请看下面的介绍:


它是这么做的,以分类模型为例,通过一组带有权重的的数据进行训练一个模型 f_{1} ,使 f_{1} 模型在这组数据上的错误率小于0.5,然后再重新给这组数据赋一个权重,让这组新的训练数据在 f_{1} 上的错误率为0.5,就是 f_{1} 在这组数据上已经不起作用,然后用这组新的数据进行训练另一个模型 f_{2} ,让 f_{2} 在这组新的数据上的错误率小于0.5,这样两个模型就是互补的,持续做这样的事,就得到很多互补的模型,然后将这些模型联合起来,就成了一个强的模型。那这里有一个问题,就是这个新得到的权重是怎么来的,请看下面介绍:


这张图结合图1就比较容易理解其中的内容。关键的东西就是什么时候乘,什么时候除。那如何算出这个 d_{1} 呢?请看下图:


画蓝色的部分就是所求 d_{1} 的公式, \alpha_{t} 是为了后面公式书写的简便进行了一个转化。那我们得到这些模型后怎么联合它们呢?请看下图介绍:


其实Adaboost的做法就是根据单个模型的错误率的大小来赋不同的权重,错误率小的赋予较大的权重,错误率大的赋予较小的权重,就好比你能力越小,说话的分量就越小。
有关集成学习的东西就先介绍到这里吧,后面如果需要再进行深入的研究。