
EMNLP2020 | 针对少样本知识图谱补全任务的自适应注意力机制模型


作者:刘子仪
Paper:Adaptive Attentional Network for Few-Shot Knowledge Graph Completion
Link:https://arxiv.org/pdf/2010.09638.pdf
注:文末有【深度学习自然语言处理】大群和各个方向小群。关注zenRRan知乎账号和深度学习自然语言处理微信公众号,可以快速了解到最新优质的NLP、推荐、计算广告等前沿技术和相关论文。

知识图谱补全时KG里一个重要研究方向,大多数知识图谱都是稀疏的,因此需要对它进行补充,知识图谱补全主要分成两种:关系预测和实体预测,我们今天看的这篇2020年EMNLP的主会文章,它主要研究的是tail的补全。对于没接触过知识图谱补全的小伙伴简单说明一下,假设有一组三元组(head, relation, tail), 给定head和relation(一个实体和一个关系),KG completion要预测与head匹配指定relation的tail。下面一起看看这篇文章吧。
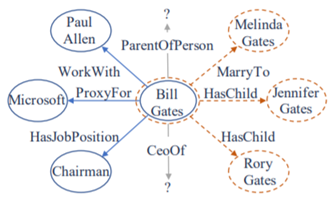
目前知识图谱补全存在的几个问题有:大量的KG relation其实是长尾的,也就是关系很多,但三元组很少,这加大了embedding的难度,也是few-shot learning被重视的原因;所有neighbor entity(如图1中Paul Allen,Melinda Gates)对于预测实体的影响权重相同,但这明显的是,这些实体间是有语义差别的,例如当预测Bill Gates-CeoOf时,关于Company的部分(蓝色部分)应该权重更大;最后是relation可能是多义的,如图2中,同样是SubPartOf,前三个代表的是location-related,后三个是organization-related。

针对以上问题,文章提出了可以自适应的注意力机制模型,它由以下三个部分组成:
a) 自适应neighbor encoder来学习实体表征(Adaptive Neighbor Encoder for Entities)
b) Transformer encoder来学习实体对的关系表征(Transformr Encoder for Entity Pairs)
c) 自适应匹配来比较query和reference(Adaptive Matching Processor) (reference就是已有的实体对,query是要预测的实体对)
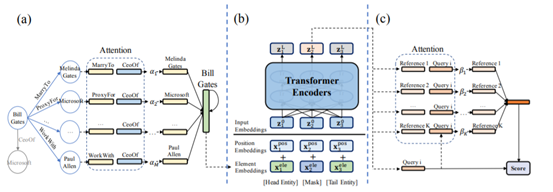

下面我们依次看下这三个部分是怎么工作的~
首先是Adaptive Neighbor Encoder for Entities,这部分要解决的问题是对于不同的neighboring entity要得到可以体现出他们角色的编码。文中使用的假设是,当三元组成立,那么h+r≈t。基于此,可以得到relation的embedding:
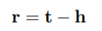
因为relation可以反应neighboring entity的角色,所以这一步骤可以转化为比较task relation和neighboring relation的相关性。比较相关性的公式如下:
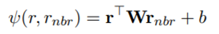
当neighboring relations和task relation更接近时,相关性会更高,那么在下面两个式子中的影响力会更大。
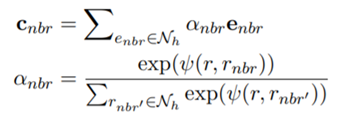
最后同时学习head的预训练embedding和上式中得到的Cnbr. 来增强实体embedding。
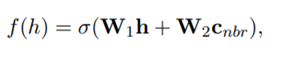
接下来是Transformer Encoder for Entity Pairs,这部分就是向Transformer输入element embedding和position embedding,最终需要的结果是第二个位置也就是relation的hidden state。
最后是Adaptive Matching Processor,这一步首先计算了reference 三元组和query的语义相似度,如下式,非常简单的一个点乘。
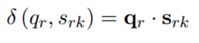
然后通过注意力机制得到一个整体的reference representation,与第一步类似,如果reference和query语义相似,那它会有更高的权重。
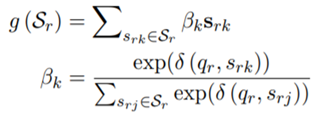
之后就是比较query 和 reference representation来预测实体。
模型在NELL和Wiki两个数据集上测试,并和当前的baseline做了对比,结果如下。
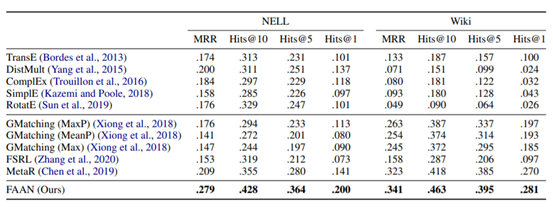

以上就是论文的主要内容啦~如果想了解更多细节可以去看看论文哦
交流群
建了【深度学习自然语言处理】大群和各个方向小群!想要进群的小伙伴,可以直接加微信号:DLNLPer。加的时候备注一下:昵称-学校or公司-研究方向,即可。然后我拉你进群!
关注zenRRan知乎账号和深度学习自然语言处理微信公众号,可以快速了解到最新优质的NLP前沿技术和相关论文。
推荐阅读
AAAI2021 | NLP所有方向论文列表(情感分析、句法、NER、对话/问答、关系抽取、KD等)
COLING2020 | 融合事件上下文信息的重要事件抽取模型
EMNLP2020 | GLRE:通过全局信息到局部语义的提炼进行篇章级关系抽取
AAAI2021 | MELINDA:一篇构建多模态数据集的论文
ACL2020 | IsoBN: 一种新的BN方法,可进一步提高BERT下游任务的性能
ACL2020 | CESTa:将对话中的情感分类任务建模为序列标注任务
IEEE2020 | 基于方面的情感分析的上下文感知嵌入增强BERT表示
ACL2020 | 使用问题图生成解决multi-hop复杂KBQA
EMNLP2019 | KET: 知识增强的Transformer模型,引入外部知识进行情感分类
详解Transition-based Dependency parser基于转移的依存句法解析器
