
中文分词是否有必要?来自ACL 2019的论文提出了这个疑问

Is Word Segmentation Necessary for Deep Learning of Chinese Representations?
来自ACL 2019,https://www.aclweb.org/anthology/P19-1314.pdf
Introduction
在中文自然语言处理领域,分词已经被认为是一个基本的预处理手段。但是作者对分词的必要性提出了质疑。作者认为分词后的模型天生就有一些缺点,主要有如下三点:
- 分词会带来数据稀疏的问题,同时普遍存在的OOV词限制了模型的学习能力——作者使用jieba分词对CTB数据集进行了处理,发现词表里有48.7%的词只出现了一次,同时有77.4%的词出现了不到4次,可见分词后的语料库是非常稀疏的。数据稀疏的问题会导致过拟合。同时由于不可能维护一个太大的词表,很多词都被当做OOV处理,这进一步限制了模型的学习能力。
- 目前最好的分词工具的分词效果也远远谈不上完美。分词带来的错误会影响到下游的NLP任务。同时,中文分词本身就是一个又难又复杂的任务,主要是因为中文词语之间的边界很模糊。不同的语言视角对中文分词有不同的标准,同一个句子很容易被分成不同的结果。
- 如果我们问一个基本的问题,即分词可能带来多少好处,那就完全取决于标记的CWS数据集中存在多少附加的语义信息。毕竟,词模型和字符模型之间的根本区别在于,是否利用了来自CWS标记数据集的teaching信号。
在神经网络的模型流行之前,关于分词是否有必要这一问题已经有很多讨论。大家发现,在信息检索、机器翻译和文本分类问题上,分词处理带来的效果提升并不是很显著。而且,在认知科学的实验中,研究人员发现中文读者的注意力不会更多地落在中文单词的中心。这意味着字符应该成为中文阅读理解的基本单元,而不是分词后的词组。
在这篇文章中,作者提出了一个基本的问题——深度学习技术中的中文分词是否有必要?作者在四种NLP任务(语言建模、机器翻译、文本分类和句子匹配)上比较了分词模型和未分词模型的效果。作者观察到,未分词的模型普遍比分词模型的效果好,同时作者比较了混合模型和纯未分词模型的表现,发现纯未分词模型的效果至少不比混合模型的效果差。
实验对比
语言建模
作者在语言建模的任务上进行了实验。语言建模的目标是,给定上下文,预测出下一个将要出现的词。作者使用LSTM来编码词语和字符得到词向量和字符向量。作者同时尝试了混合编码,将词向量表示和字符向量表示相加。一个词的混合表示是通过组合其组成词的向量和其余字符的向量来获得。然后使用CNN来组合字符向量,使其维度相等。得到的结果如下图所示:
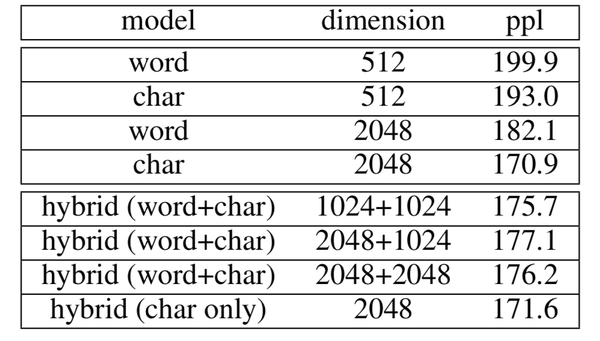

观察结果可以发现,使用字符向量的模型不仅超越了词向量模型,而且超越了混合模型。而使用了混合编码向量和模型也超越了基于词向量的模型。这意味着,字符的词向量已经编码所有必要的语义信息,增加词向量会适得其反。同时,只使用字符的混合编码模型的表现与只使用字符的模型相似,表明分词不会增加额外的信息。它也超越了基于词向量的模型,可以解释为它只在字符上计算词向量表示,不会有数据稀疏和OOV的问题,也就减少了过拟合。
机器翻译
作者实验了Ch-En和En-Ch两种翻译任务。作者使用了标准的Seq2Seq+Attention模型,然后在训练阶段分别使用整个句子和BOW作为目标,两种翻译任务得到的结果分别如下:
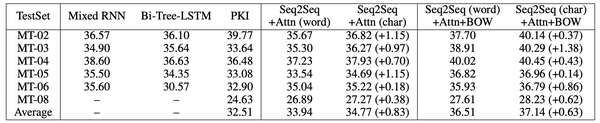

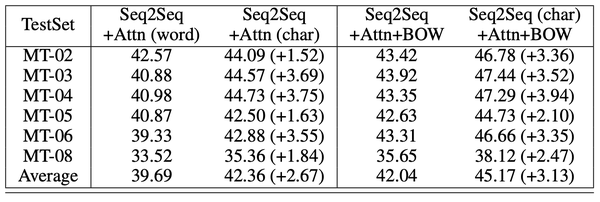

在Ch-En的任务上,对于传统的Seq2Seq+Attention模型,使用字符向量在所有的数据集上都超越了词向量,平均提升了0.83。而在使用BOW作为目标时,字符向量模型比词向量模型平均提升了0.63。
在En-Ch的任务上,字符向量模型比词向量模型大幅提升了3.13,比Ch-En任务的提升要显著。这主要是因为,在Ch-En任务上,字符向量模型和词向量模型的主要差异在编码阶段,而在En-Ch任务上,编码和解码阶段都是不同的。
导致词向量模型较差的另一个主要原因是解码时的UNK词。作者还在En-Ch任务上实现了BPE subword模型,它超越了词向量模型的效果,但还是低于字符向量模型的效果。
因此,作者认为,在中文深度学习解码中,生成字符比生成单词具有优势。
句子匹配
有两个类似于SNLI语料库的中文数据集——BQ和LCQMC。他俩的目标是不同的,BQ的目标是给定两个句子,判断两者的语义是否相同。而LCQMC的目标是判断两者的意图是否相同。例如,对于如下两个句子“我的手机丢了”和“我想买个新手机”,两者的语义是不同的,但意图是相同的。
作者在这两个数据集上比较了基于词的模型和基于字符的模型的效果。结果如下:


可见,基于字符的模型在两个数据集上都超越了基于词的模型,分别取得了1.34和2.90的提升。于是作者认为,基于字符的模型显著地优于基于词的模型。
文本分类
作者在四个数据集上使用了biLSTM模型来处理文本分类任务。结果如下:
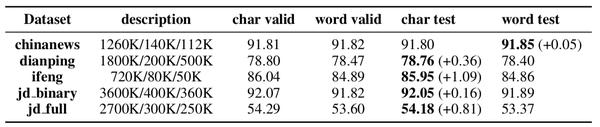

可见,基于词的模型只在chinanews这一个数据集上超越了基于字符的模型,而且只有很小的0.05的提升。而在其余的四个数据集上,基于字符的模型都显著地超越了基于词的模型。
分析
作者试图找出为何基于字符的模型优于基于词的模型。当然不可能完全审查其内部机制,但作者尽可能发现主要的影响因素来解释基于词的模型的劣势。
数据稀疏
避免词汇量变得太大的一种常见方法是设置词频阈值,并使用特殊的UNK标记来表示词频低于阈值的所有单词。词频阈值与词汇量密切相关,因此与参数大小密切相关。下图展示了词频阈值和词汇量的关系,同时也展示了词频阈值和模型表现的关系。
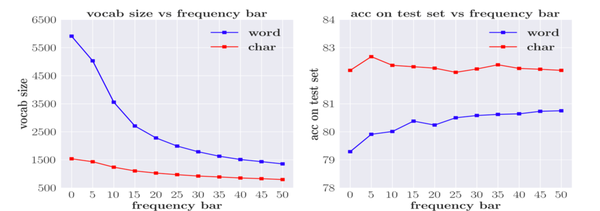

由结果可见,对于两个模型而言,当词频阈值为0(使用全部词语/字符)时效果较差。而对基于字符的模型而言,当词频阈值为5时,词表大小为1432,平均词频为72,此时能取得最佳效果。而对基于词的模型而言,当阈值为50,词表大小为1355,平均词频为83,取得最佳效果。这就意味着,给定一个数据集,为了充分地学习到语义表示,两个模型所见到的数据量应该大致相同。而由于基于词的模型的稀疏性,这一目标通常很难达到。
OOV词
关于基于词的模型表现较差,一种可能的解释就是,它包含了太多的OOV词。如果是这样的话,我们可以通过减少OOV词的数量来减少基于词的模型和基于字符的模型之间的差距。然而,通过这种方式来减少OOV词的数量,也会导致数据稀疏的问题。于是作者采取了一种替代的方式——作者从数据集中删除了所有包含OOV词的句子。下图展示了在词频增加时效果的改变和训练集大小的改变。


可见,在增加词频阈值后,两者的差距逐渐缩小。注意到,基于字符的模型在增加词频阈值后,一开始效果有略微地上升,然后缓慢减小。这是因为对于基于字符的模型而言,OOV问题并不严重,因此不会对性能造成太大影响。但是,随着我们删除越来越多的训练样本,不断缩小的训练集会产生很大的问题。相比之下,对于基于词的模型而言,即使将频率阈值设置为50,性能也会继续提高,这意味着删除一些OOV词的积极影响要大于删除一些训练数据带来的消极影响。总之,基于词的模型存在严重的OOV问题。 可以通过减少数据集中的OOV词的数量来缓解此问题。
过拟合
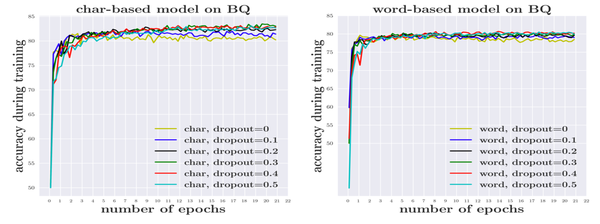
数据稀疏性问题导致基于词的模型需要学习更多参数,因此更容易过拟合。作者在BQ数据集上进行了实验,结果证实了这一观点。为了取得最好的效果,基于词的模型(0.5)需要比基于字符的模型(0.3)使用更大的dropout rate。这意味着对基于词的模型而言,过拟合的问题更加地严峻。作者还发现,与基于字符的模型相比,基于词的模型中具有不同dropout rate的曲线更接近在一起,这意味着dropout 不足以解决它的过拟合问题。 与具有最佳dropout rate的基于词的模型(80.65)相比,没有使用dropout的基于字符的模型已经实现了更好的性能(80.82)。

可视化
BQ语义匹配任务旨在确定两个句子是否具有相同的意图。下图显著地展示了为什么基于字符的模型优于基于词的模型。 由BiPMP模型计算出的热力图表示两个句子的token之间的注意力匹配值。
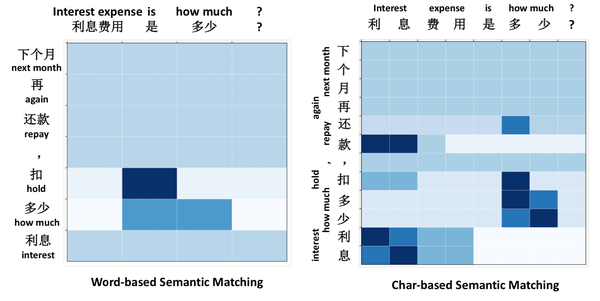

输入的两个句子分别是“利息费用是多少”和“下个月还款要扣多少利息”。分词结果分别是“利息费用”、“是”、“多少”和“下个月”、“还款”、“扣”、“多少”、“利息”。对基于词的模型而言,“利息费用”作为一个单独的词,它没法映射到“利息”上。但是对于基于字符的模型,情况并非如此,因为两个句子中的相同字符更容易映射。
结论
在本文中,作者提出一个基本问题,即中文的深度学习是否需要分词。 作者在四个端到端的NLP任务中将此类基于词的模型与基于字符的模型进行了比较。 作者观察到,基于字符的模型始终优于基于词的模型。 基于这些发现,作者表明基于单词的模型的劣势归因于单词分布的稀疏性,这会导致更多的OOV单词和过拟合的问题。
作者写本文的目的不是要做出一个确定性的结论说,中文分词没有必要,而是希望本文能够促进关于中文分词必要性和其内部机制的探索和讨论。