【机器视觉】计算机视觉领域会有哪些新的研究方向值得提前探索
本文选自知乎问答,仅用于学术交流。
侵删
2020年,计算机视觉领域会有哪些新的研究方向值得提前探索?
https://www.zhihu.com/question/330153893
知乎高赞回答
1.作者:罗浩.ZJU
https://www.zhihu.com/question/330153893/answer/721238966




2.作者:育心
https://www.zhihu.com/question/330153893/answer/740254474
结合计算机视觉、机器人领域5大顶会(CVPR/ICCV/IROS/ICRA/ECCV),以及产业界的需求,总结3个当下热门及前沿的研究领域。
三维视觉
三维视觉是传统的研究领域,但最近5年内得到快速发展。三维视觉主要研究内容有:三维感知(点云获取及处理)、位姿估计(视觉SLAM)、三维重建(大规模场景的三维重建、动态三维重建)、三维理解(三维物体的识别、检测及分割等)。

3D视觉在CV顶会上的论文比例,也在逐年增加。
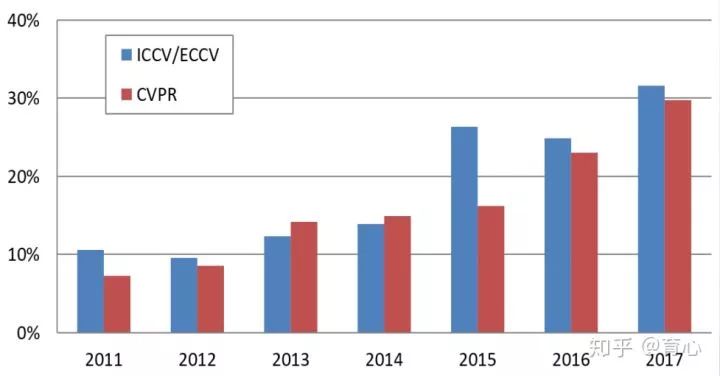
视频理解
随着新型网络媒体的出现,以及5G时代的到来,视频呈现爆炸式增长,已成为移动互联网最主要的内容形式。面对于海量的视频信息,仅靠人工处理是无法完成的,因此实现视频的智能化理解则成为了亟待解决的问题。
自2012年,深度学习在图像理解的问题上取得了较大的突破,但视觉理解比图像的目标检测识别要复杂的多。这是因为视频常有许多动作,动作往往是一个复杂概念的集合,可以是简单的行为,但也可能是带有复杂的情绪、意图。举个简单的例子,对一段视频分类,与对一幅图像分类,哪个更容易一些?
从最近几年知名的计算机视觉竞赛,也可以看出,图像层面的竞赛在减少,视频层面的竞赛在
增加。
多模态融合
多模态融合的知识获取是指从文本、图片、视频、音频等不同模态数据中交叉融合获取知识的过程。
随着计算机视觉越来越成熟之后,有一些计算机视觉解决不了的问题慢慢就会更多地依赖于多个传感器之间的相互保护和融合。
小结
怕什么真理无穷,进一寸有一寸的欢喜!
3.作者:商汤科技SenseTime
https://www.zhihu.com/question/330153893/answer/721471978
谢邀!商汤及联合实验室CVPR 2019论文精选,研究一下?
商汤及商汤联合实验室入选CVPR 2019的代表性论文,从五大方向阐释计算机视觉和深度学习技术最新突破,以下是从论文中提取的精华部分~
高层视觉核心算法——物体检测与分割
代表性论文:基于混合任务级联的实例分割算法
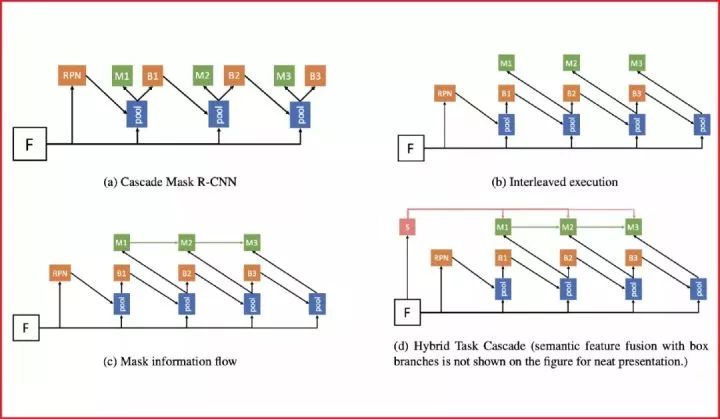
对于很多计算机视觉任务来说,级联是一种经典有效的结构,可以对性能产生明显提升。但如何将级联结构引入实例分割的任务仍然是一个开放性问题。简单地将物体检测的级联结构Cascade R-CNN与经典的实例分割算法Mask R-CNN进行结合,带来的提升比较有限。
在这篇论文中,我们提出了一种新的框架Hybrid Task Cascade (HTC)。该框架是一个多阶段多分支的混合级联结构,对检测和分割这两个分支交替地进行级联预测,除此之外,我们还引入了一个全卷积的语义分割分支来提供更丰富的上下文环境信息。HTC在COCO数据集上相对Cascade Mask R-CNN获得了1.5个点的提升。基于提出的框架,我们获得了COCO 2018比赛实例分割任务的冠军。
代表性论文:基于特征指导的动态锚点框生成算法
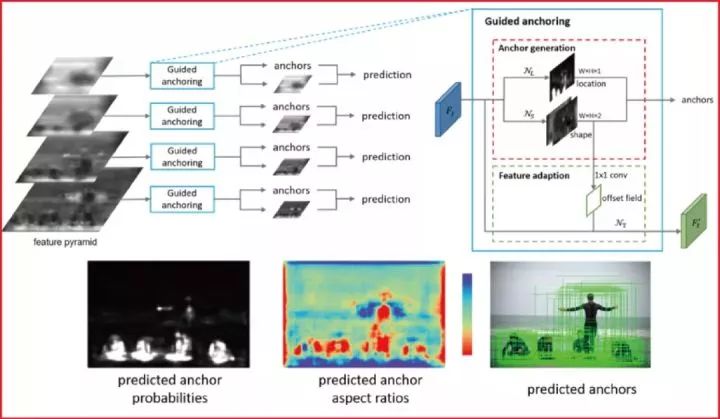
锚点框(Anchor)是现代物体检测技术的基石。目前主流的物体检测方法大多依赖于密集产生静态锚点框的模式。在这种模式下,有着预定义的大小和长宽比的静态锚点框均匀的分布在平面上。
本文反思了这一关键步骤,我们提出了一种基于特征指导的动态锚点框生成算法,该算法利用语义特征来指导锚点框生成的过程,具有高效率和高质量的特点。本算法可以同时预测目标物体中心区域和该区域应产生的锚点框的大小和长宽比,以及根据锚点框的形状来调整特征,使特征与锚点框相吻合,从而产生极高质量的动态锚点框。
本方法可以无缝使用在各种基于锚点框的物体检测器中。实验表明本方法可以显著提高三种最主流的物体检测器(Fast R-CNN, Faster R-CNN, RetinaNet)的性能。
底层视觉核心算法——图片复原与补全
代表性论文:基于网络参数插值的图像效果连续调节

图像效果的连续调节在实际中有着广泛的需求和应用, 但是目前基于深度学习的算法往往只能输出一个固定的结果,缺乏灵活的调节能力来满足不同的用户需求。
针对这个问题, 本文提出了一种简单有效的方式来达到对图像效果的连续光滑的调节,而不需要进一步繁杂的训练过程。该方法能够在许多任务上得到应用, 比如图像超分辨率,图像去噪,图像风格转换,以及其他许多图像到图像的变换。
具体地,我们对两个或多个有联系的网络的参数进行线性插值,通过调节插值的系数,便可以达到一个连续且光滑的效果调节。我们把这个在神经网络的参数空间中的操作方法称为网络参数插值。本文不仅展示了网络参数插值在许多任务中的应用,还提供了初步的分析帮助我们更好地理解网络参数插值。
代表性论文:基于光流引导的视频修复

本文关注视频中的修复问题,虽然近年来图片修复(Image Inpainting)问题取得了很大的进展,可是在视频上完成像素级的修复仍然存在极大的挑战。其困难主要在于:1)保证时序上的连续型;2)在高分辨率下实现修复;3)降低视频对于计算的开销。
本文致力于解决这三个问题,同时尽可能保证视频的清晰度。在研究中我们发现,保证视频的时序一致性,对于视频修复任务来说非常重要,这不仅仅保证了修复后的视频能够有良好的观看体验,同时还帮助我们从视频本身来抽取真实的像素块来实现更加高效地修复。
所以我们的框架主要由两部分组成,第一部分是通过深度神经网络实现光流的补全,之后通过补全的光流在整个视频间做像素的传导,从而形成一条在时序上保持一致的像素链。这样缺失的区域就可以通过它来实现修复,并且还能够保证视频的清晰度。
面向自动驾驶场景的3D视觉
代表性论文:PointRCNN: 基于原始点云的3D物体检测方法
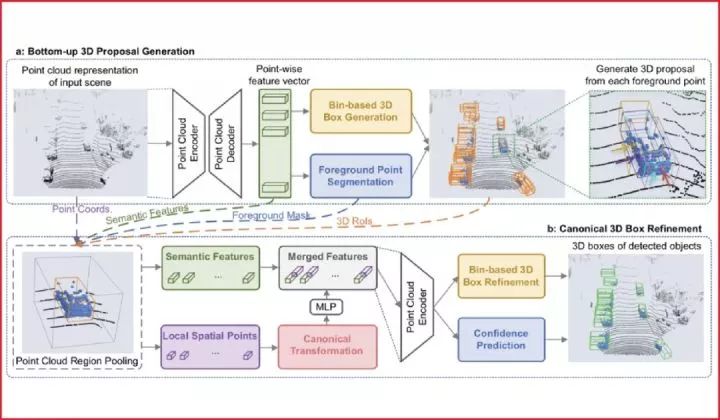
本文首次提出了基于原始点云数据的二阶段3D物体检测框架,PointRCNN。3D物体检测是自动驾驶和机器人领域的重要研究方向,已有的3D物体检测方法往往将点云数据投影到鸟瞰图上再使用2D检测方法去回归3D检测框,或者从2D图像上产生2D检测框后再去切割对应的局部点云去回归3D检测框。而这些方法中,前者在将点云投影到俯视图上时丢失了部分原始点云的信息,后者很难处理2D图像中被严重遮挡的物体。
我们观察到自动驾驶场景中物体在3D空间中是自然分离的,从而我们可以直接从3D框的标注信息中得到点云的语义分割标注。因此本文提出了以自底向上的方式直接从原始点云数据中同步进行前景点分割和3D初始框生成的网络结构,即从每个前景点去生成一个对应的3D初始框(阶段一),从而避免了在3D空间中放置大量候选框。
在阶段二中,前面生成的3D初始框将通过平移和旋转从而规则化到统一坐标系下,并通过点云池化等操作后得到每个初始框的全局语义特征和局部几何特征,我们将这两种特征融合后进行了3D框的修正和置信度的打分,从而获得最终的3D检测框。
在提交到KITTI的3D检测任务上进行官方测试时,我们提出的方法在只使用点云数据的情况下召回率和最终的检测准确率均超越了已有的方法并达到了先进水平。目前我们已将该方法的代码开源到了GitHub上。
面向AR/VR场景的人体姿态迁移
代表性论文:基于人体本征光流的姿态转换图像生成

本文主要关注人体姿态转移问题,即在给定一幅包含一个人的输入图像和一个目标姿态的情况下,生成同一个人在目标姿态下的图像。我们提出利用人体本征光流描述不同姿态间的像素级对应关系。
为此,我们设计了一个前馈神经网络模块,以原始姿态和目标姿态作为输入,迅速对光流场进行估计。考虑到真实光流数据难以获取,我们利用3D人体模型拟合图像中的人体姿态,生成对应姿态变化的光流场数据,用于模型训练。
在该光流预测模块的基础上,我们设计了一个图像生成模型,利用本征光流对人体的外观特征进行空间变换,从而生成目标姿态下的人体图像。我们的模型在DeepFashion和Market-1501等数据集上取得了良好的效果。
无监督与自监督深度学习前沿进展
代表性论文:基于条件运动传播的自监督学习
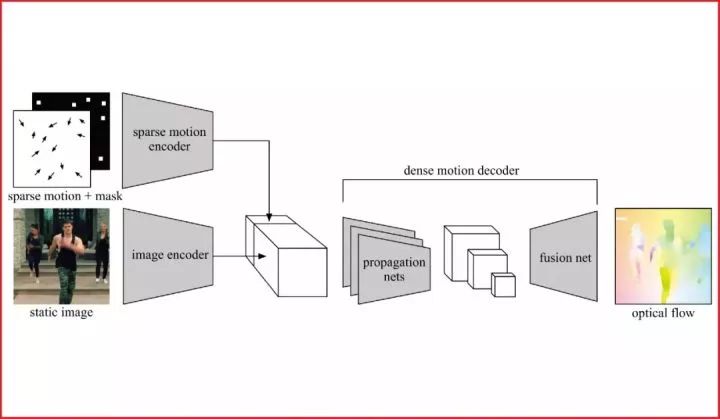
本文提出一种从运动中学习图像特征的自监督学习范式。1)在自然场景中,物体的运动具有高度的复杂性,例如人体和常见动物都具有较高的运动自由度。2)同时,从单张图片中推测物体的运动具有歧义性。现有基于运动的自监督学习方法由于没有很好地解决这两个问题,因而未能高效地从运动中学习到较好的图像特征。
为此,我们提出了条件运动传播这个自监督学习任务。训练时,我们将单张图像作为输入,将目标运动场中抽样出来的稀疏运动场作为条件,训练神经网络去恢复目标运动场。这样训练完的图像编码器可以用来作为其他高级任务的初始化。我们在语意分割、实例分割和人体解析等任务中相比以往自监督学习方法获得了较大提升。
经过分析,我们发现条件运动传播任务从运动中学习到了物体的刚体性、运动学属性和一部分现实世界中的物理规律。利用这些特性,我们将它应用到交互式视频生成和半自动实例标注,获得了令人满意的效果;而整个过程,没有用到任何人工的标注。
4.作者:Shawn Tsien
https://www.zhihu.com/question/330153893/answer/729391245
视觉问题,由三大块组成:图像分割、三维重建、模式识别。目前这个行业的有效进展,离彻底解决视觉,大约只完成了30%左右,所以还有很多事情可做,但真的深入进去,会发现很难找到一个研究方向。比如李飞飞几年前就已经“遥遥领先”地在研究文字转视频了,那你再研究图像分割,是不是有点太落伍了?到时候论文能否发表都成问题,按时毕业、职称晋升,这才是最重要的事。所以选题都把眼光都放在高大上的、能吸引眼球的课题上。
视觉本身是个工程问题,但却成了学术界的热门方向。解决工程问题,需要从头到尾的完整方案,而学术界习惯各自解决一小步。虽然大问题必然由很多小问题组成,但要求这些小问题都在同一条线上,而且中间不能有任何一个环节缺失。显然学术界的无分工、无统一目标、无明确责任的状态,使得研究更像是一场娱乐狂欢。众人像一群野马一样乱跑,新来的马心里没底,很怕落伍,只看哪里马多就往哪里跑,而领头的马本来心里没底,但一看后面跟来这么多,就以为自己跑对了方向。这样的研究方式,在数学、微观、宏观这些极少人涉足、暂时用不到的方向,确实能取得了一些成果。比如古希腊几何学家阿波洛尼乌斯总结了圆锥曲线理论,一千八百年后由德国天文学家开普勒将其应用于行星轨道理论,阿基米德的积分要等两千年才和牛顿、莱布尼茨汇合成完整的微积分,所以谁知道眼前这篇论文啥时候派上用场呢?而视觉不一样,这是眼前急等要下锅的米,等不及下一届蟠桃盛会。
要想彻底解决视觉问题,眼前是指望不上学术界了,真要等学术界进化,可能还得几百年,而工业界又在等学术界的结果,所以似乎还遥遥无期,但不妨碍继续写论文。图像分割是三块中最难的一块,却是听起来最low的一块,当然我所指通用分割,所以选这块来写论文,风险太大。三维重建相对最简单,但已经走过半个多世纪了,SLAM也基本跑到了山穷水尽的悬崖边。而模式识别却是风光独好,因为这块的工作量最大,涉及的方面很多,难度却不大,适合写论文。由于基础缺失,所以不可能获得精确的结果,但也尽量要用最复杂的数学公式,这样更利于论文发表,对啦,还要好好利用深度学习这个炼丹炉。最后祝大家好运,论文按时发表、按时毕业或评上职称。
你对这个问题怎么看呢?可以评论你的想法~
-完-
延展阅读:
目标检测领域还有什么可做的?19个方向给你建议
作者:种树的左耳
来源:知乎
链接:
https://www.zhihu.com/question/280703314/answer/564235579
知乎问题:目标检测领域还有什么可以做的?
感觉已经饱和了,很难再出顶级算法的样子。我所指的饱和是说围绕目标检测感觉没有什么好文章能发出来了,现有算法很难在短时间有突破了。想请教大家有什么好做的点子么?
种树的左耳答案
饱和是相对于占坑来说的,对于去探索未来踩坑来说,目标检测还远远没有达到饱和的地步。只是说想发简单的好论文越来越难了,并不是说不会有什么突破了。单就检测来说,2018年顶会出的目标检测论文也并不算少。
下面是我个人就目标检测算法在深度学习领域未来研究的一些看法:
1.从专注精度的Faster RCNN、RFCN相关系列,以及专注速度的YOLO系列,未来的方向更专注于精度和速度的结合,这也是过去的很多模型在SSD系列上产生的原因,主要代表有RefineDet、RFBNet等。所以SSD系列的研究会成为主流。
2.目标选框从Region Based 和Anchor Based到基于角点,甚至是基于segmentation,包括semantic segmentation 和 instance segmentation 。今年比较有代表的CornerNet和Grid RCNN是一个开拓思路的方向,细节就不用说了吧。。。未来的目标选框方法依旧是研究的一个重要方向。
3.多尺度问题(尺度变换问题),目前常见的三种思路,采用专门设计的尺度变换模块,可以参考STDN: Scale-Transferrable Object Detection。多个scale的目标检测设计,没记错的话之前有在Faster RCNN基础上,做多个scale的rpn。当然最新的SNIP也是多个RPN。还有就是SNIPER,先用SNIPER的模块进行一个粗检测,检测出多个scale关注区域,然后再进行细检测。目前的问题是,如果是才有scale transfer moudle的话,可能会丢失一些信息,也就是多scale融合学习存在问题,那么如何设计一个单scale模型transfer moudle进行有效学习,这一点我是存疑的,总感觉这个多scale融合哪里存在问题。同时,采用多scale的先初步多scale检测再细检测会增加计算时间,如何有效的将两个模块进行结合,进行进一步的再设计是未来一个重点。
4.重新思考目标检测的训练,凯明今年的新作Rethinking imagenet pre-training已经验证了一个问题,pre-training再training和training from scratch这一点在目标检测问题理论上也是适用的。当目标检测数据集达到一定规模,目标选框问题是否可以单独抽离出来,做好更精确的选框预训练,再在具体的数据集上主要进行选框适应性训练和分类训练?另外由于目前的目标检测backbone网络都是从图像分类网络过来的,图像分类网络之前的提法是尺度不变性,而目标检测有尺度变化性,今年清华的一篇文章就是做了这个问题,设计了一个专门针对目标检测问题的backbone,但是还是基于ImgNet进行了预训练,那么不在ImgNet进行预训练是否可行?另外如何从一个小的数据集上进行一个转向任务的无预训练的学习 or 有预训练的小规模数据学习训练。目标检测的小规模数据训练是在实际工程应用中,尤其是工业化场景中一个比较需要关注的问题。
5.重新思考卷积神经网络的旋转不变性和尺度变化,有一些我在上面已经提到了,从一些论文的研究表明,卷积神经网络的旋转不变性似乎是一个伪命题,卷积网络的旋转不变性主要是通过数据的增强和大样本的学习获取的,本身应该不具备旋转不变性。这个问题我看一些研究者提到过,我的感觉是应该是不具备旋转不变性的,可能需要进行进一步的研究进行分析。旋转不变性和尺度变化会影响目标检测算法的基本框架。
6.目标检测以及深度学习的分割、关键点检测、跟踪都需要在数据标注上耗费巨大的成本,如何采用算法进行更有效的标注是一个核心的问题,包括上面4中提到的如何用更少的样本进行学习是关键。如果不能进行无监督的话,那么小规模数据的监督学习如何更有效进行训练达到大幅度精度提升将会是研究的重点。还有就是采用单图像单类别的弱标注,不进行选框标注,通过对大型目标检测数据集进行预训练,然后在这种单类单图像场景进行弱监督多类检测学习,进而泛化到多类单图像检测。
7.IOU的算法设计和阈值的选择,今年比较有特点的是IOUNet和Cascade RCNN。
8.更好的NMS。
9. one shot learning,我看来一个样本和小样本的数据增强和学习,也会有一些有意思的研究。参考评论里面的提到的参考文章:LSTD: A Low-Shot Transfer Detector for Object Detection 发表在AAAI2018。
10.如何实现未知目标类的检测,也就是我们常说的zero shot learning。从结合语义等信息从已知类别的目标检测,迁移到对未知类别的目标进行检测。参考论文Zero-Shot Object Detection(ECCV2018)。
11.如何从已经训练的模型去迁移到新增数据、新增类别的学习,也就是增量学习(Incremental Learning)。可以参考的论文有Incremental Learning of Object Detectors without Catastrophic Forgetting(ICCV2017)目标检测的论文以及End-to-End Incremental Learning(ECCV2018)。
12. CNN、Pooling、Loss 目前都有各种各样的变体,更有效的CNN、Pooling、Loss依旧会出现。
13.将目标检测方法的一些研究迁移到SOT(Single Object Tracking)和MOT(Multiple Object Tracking),可以有效的观察到今年表现比较好的SOT算法和MOT算法都有和检测的结合出现。单目标跟踪可参考商汤和中科院计算所的SiameseRPN:High Performance Visual Tracking with Siamese Region Proposal Network(CVPR2018)以及最新的SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks(刚刚发布)。多目标跟踪可参考清华艾海舟组的REAL-TIME MULTIPLE PEOPLE TRACKING WITH DEEPLY LEARNED CANDIDATE SELECTION AND PERSON RE-IDENTIFICATION(CVPR2018)
14.目标检测的FineGrained问题。
15.模型的轻量级化,从目前的轻量级网络对于计算资源的压缩上,主要是集中在对于backebone的压缩,那么对于模型整体上针对目标检测的考虑进行再设计是否可行?
16.大尺寸图像的目标检测问题,目前很多检测的基本主要集中在512x512和1000x600左右的图像操作,但是在未来,4k图像和视频会成为主流,大尺寸图像的目标检测、跟踪都会成为主流,今年CVPR2018有一篇文章Dynamic Zoom-in Network for Fast Object Detection in Large Images是进行大尺寸图像的目标检测,主要是做的2k,设计了一个粗检测和精细检测的模块。所以针对大尺度的图像如何进行计算资源的压缩、有效的目标检测or跟踪是一个非常有前瞻性的研究工作。尤其是未来的网络电视剧、电影、短视频会出现更多的4k内容。
17.AR场景下的跨类检测融合,这个属于我的想象,一个简单的比如是AR眼镜会跟人类的眼睛一样的视野。那么在这个场景下对于视觉获取内容的有效提取包括图像里面就包括文字、商标、各类目标等等内容的融合检测。
18.3d 激光雷达lidar和深度相机的目标检测,在自动驾驶这一块用的比较多,但是更精细的应用场景还是很多的,还有很多的应用场景比如裁判之类的要求更精细化的检测(包括关键点检测分割之类的)。
19.视频流的检测,主要是应用到移动端场景的手机或者FPGA。由于视频流的图片信息具有时间和空间相关性,相邻帧之间的特城提取网络会输出有冗余的特征图信息,会造成没必要的计算浪费。同时图片的目标检测算法在目标物体运动模糊,拍摄焦距失调,物体部分遮挡,非刚性物体罕见变形姿态的情况下,很难获得较为准确的结果。同时权衡精度、计算时间以及计算资源变得尤为重要。可参考论文包括Towards High Performance Video Object Detection for Mobiles(Arxiv Tech Report 2018)、Towards High Performance Video Object Detection(CVPR2018)、Fully Motion-Aware Network for Video Object Detection(ECCV2018),ECCV2018和CVPR2018都有两三篇,主要贴一下Jifeng Dai的工作,其它就不贴了。

先进制造业+工业互联网
产业智能官 AI-CPS
加入知识星球“产业智能研究院”:先进制造业OT(自动化+机器人+工艺+精益)和工业互联网IT(云计算+大数据+物联网+区块链+人工智能)产业智能化技术深度融合,在场景中构建“状态感知-实时分析-自主决策-精准执行-学习提升”的产业智能化平台;实现产业转型升级、DT驱动业务、价值创新创造的产业互联生态链。

版权声明:产业智能官(ID:AI-CPS)推荐的文章,除非确实无法确认,我们都会注明作者和来源,涉权烦请联系协商解决,联系、投稿邮箱:erp_vip@hotmail.com。




