Cyclades - 异步并行机器学习算法
Cyclades之前naive的异步并行算法
ASGD 和 Hogwild! 的想法最直接:既然原来的全局同步造成了等待与低效,干脆取消这个环节,所有节点都可以无锁(无等待)地对全局模型进行访问和更新。
- ASGD 是在多机场景下的算法实现。以parameter server架构为例,负责计算的worker一旦完成了当前节点的计算,可以直接把梯度更新push给储存模型参数的server,server则即刻更新参数,不用管别的worker的情况。
- Hogwild! 是在单机多线程场景下的算法实现。由于多个线程共享内存,按常理某个线程更新时应该给内存加锁以保证模型写入的一致性,但是 Hogwild! 为了提高吞吐率,选择不带锁的多线程的写入。
这种粗暴的做法肯定会导致冲突的出现:ASGD中滞后的梯度更新,或者Hogwild!的写入冲突都会造成优化过程中的抖动甚至收敛失败,但是在一定的约束和补偿下,两者的收敛性都可以得到保障。例如,ASGD的server可能在第t+n次迭代中收到了来自某个worker的第t次迭代的梯度更新结果,此时我们可以对这个滞后的结果进行某种惩罚(AdaDelay对滞后的更新减小布长)或者修正补偿(DC-ASGD对滞后的更新进行泰勒展开,利用近似的二阶信息获得更准确的对实时梯度的估计);而Hogwild!的收敛性需要限定模型访问的稀疏性、还要求损失函数是Lipschitz连续的。这部分内容并非本文重点,因此不展开叙述。
从另一个角度看,在SGD这类算法的优化过程中我们一般都会引入一定的随机变量,减少陷入local optima逃不出来的情况,而异步算法的噪声则恰好起到了这个作用。
Cyclades的改进
Cyclades 是对 Hogwild! 算法的改进,核心目标是减少多线程之间的冲突。其基本假设为:不同的训练样本更新的是模型的不同局部的参数(例如在一个推荐模型中,一个男性用户的输入样本会更新男性相关特征的参数,女性的则会对应另一部分参数)。如果我们能把训练数据首先进行一个预划分,让更新相似位置参数的数据分在同一组,且后续的训练过程中同一组数据放在一个线程里计算更新,那么即使多个线程同时写入更新,由于不同线程更新的参数并不重叠,也就不会产生冲突了。
所以我们关注的核心问题变为:如何分辨训练样本更新的是哪部分模型参数,并对所有样本进行合理的预先的聚类划分?
对于这个问题,我们可以首先构造参数更新的conflict-graph,通过sample获得一系列子图(由更新同一部分参数的update构成),进而反推出conflict的样本组合,从而完成分组训练。
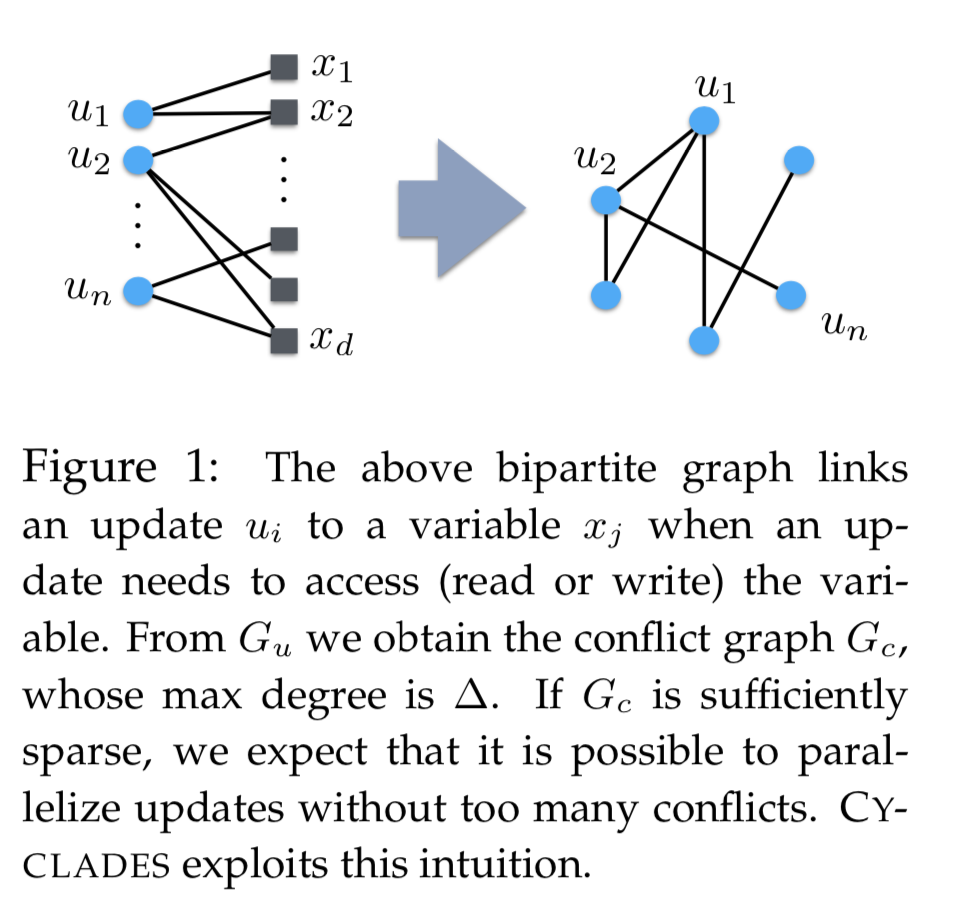
如上图所示的Figure 1展示了conflict-graph的构建过程。左边的二部图描述了梯度更新与参数的依赖关系:\(u_i\)表示一个梯度更新,\(x_i\)表示一个模型的参数,在左边的二部图中,相连的边表示\(u_i\)这个更新需要读/写\(x_i\)这个参数。通过这个二部图我们可以推导出右边的conflict-graph:其顶点表示不同的梯度更新,如果某两个顶点相连,表示这两个更新会读/写至少一个共同参数。
如果在conflict-graph中两个梯度更新是相连的,说明他俩对应的训练样本会更新相同/相似的模型参数子集,那这些样本就应该分到同一组中。值得注意的是,conflict-graph在实际应用中一般不会真实构建出来,而是直接通过sample二部图来获得。
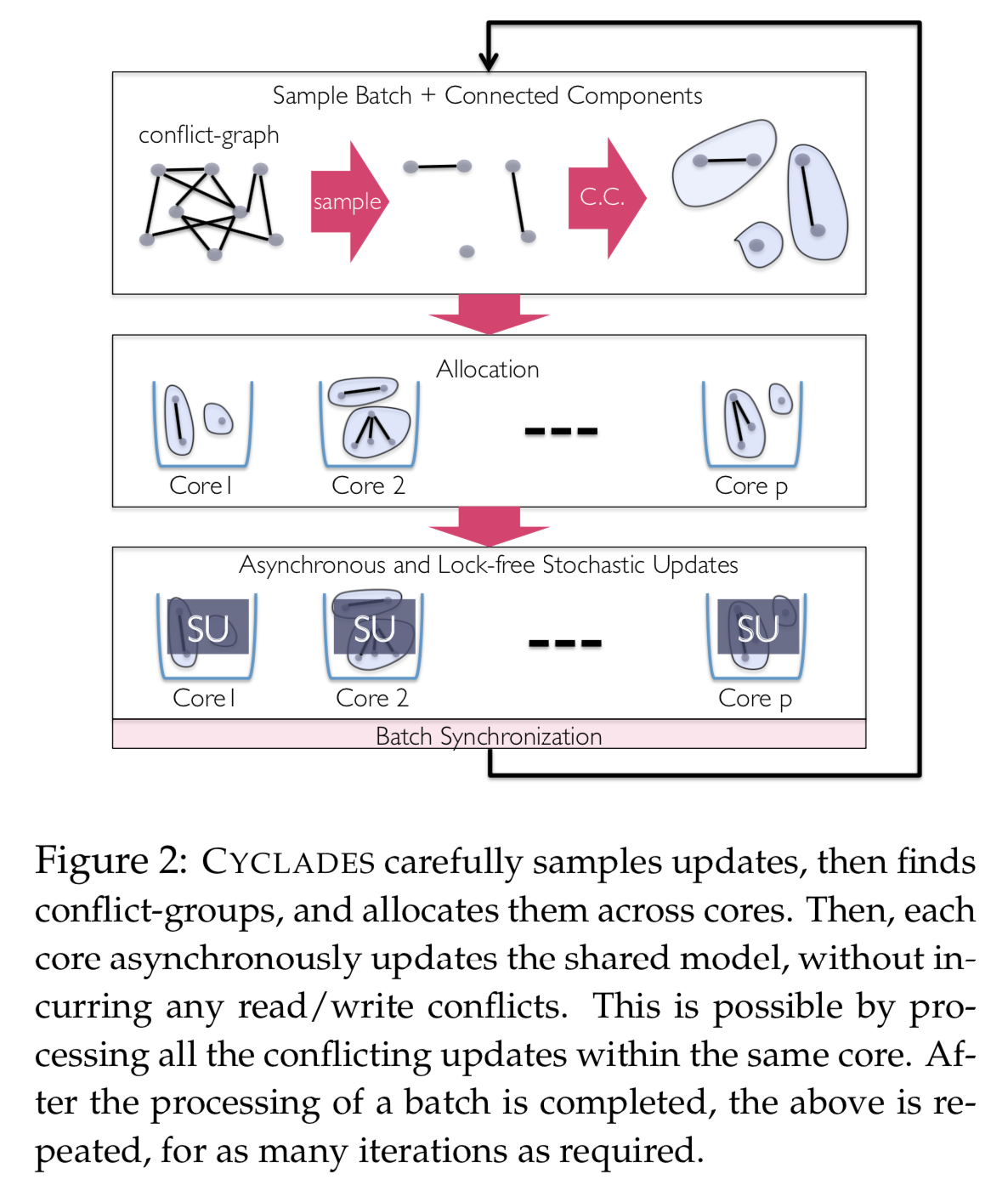
于是我们可以进一步得到如Figure 2所示的算法流程。因为全量分析conflict-graph是不现实的,所以我们会进行sample,根据sample的结果,我们可以获得若干个彼此之间不连通的子图。每个子图分配给一个线程/CPU核去更新计算,所有线程异步并行。然后整个过程循环迭代直到算法收敛。
参考文献:
[1] 《分布式机器学习:算法、理论与实践》刘铁岩 陈薇 王太峰 高飞
[2] CYCLADES: Conflict-free Asynchronous Machine Learning. Pan X, Lam M, Tu S, et al.

