深度学习入门-深度学习(一)

深度学习是加深了层的深度神经网络。基于之前介绍的网络,只需通过叠加层,就可以创建深度网络。
我们来创建一个如图8-1所示的网络结构的CNN(一个比之前的网络都深的网络)。如图8-1所示,这个网络的层比之前实现的网络都更深。这里使用的卷
积层全都是3 × 3的小型滤波器,特点是随着层的加深,通道数变大(卷积层的通道数从前面的层开始按顺序以16、16、32、32、64、64的方式增加)。


这个网络有如下特点。
• 基于3×3的小型滤波器的卷积层。
• 激活函数是ReLU。
• 全连接层的后面使用Dropout层。
• 基于Adam的最优化。
• 使用He初始值作为权重初始值。
图8-1的网络的错误识别率只有0.62%。这里我们实际看一下在什么样的图像上发生了识别错误。图8-2中显示了识别错误的例子。


题外话:Data Augmentation(数据扩充)方法
集成学习、学习率衰减、Data Augmentation(数据扩充)等都有助于提高识别精度。尤其是Data Augmentation,虽然方法很简单,但在提高识别精度上效果显著。Data Augmentation基于算法“人为地”扩充输入图像(训练图像)。具体地说,如图8-4所示,对于输入图像,通过施加旋转、垂直或水平方向上的移动等微小变化,增加图像的数量。这在数据集的图像数量有限时尤其有效。


除了变形之外,Data Augmentation还可以通过其他各种方法扩充图像,比如裁剪图像的 “crop处理”、将图像左右翻转的“flip处理”对于一般的图像,施加亮度等外观上的变化、放大缩小等尺度上的变化也是有效的。
加深层的动机
关于加深层的重要性,现状是理论研究还不够透彻。但是有几点可以从过往的研究和实验中得以解释:
优点1)网络层越深,识别性能也越高。加深层的其中一个好处就是可以减少网络的参数数量。说得详细一点,就是与没有加深层的网络相比,加深了层的网络可以用更少的参数达到同等水平(或者更强)的表现力。
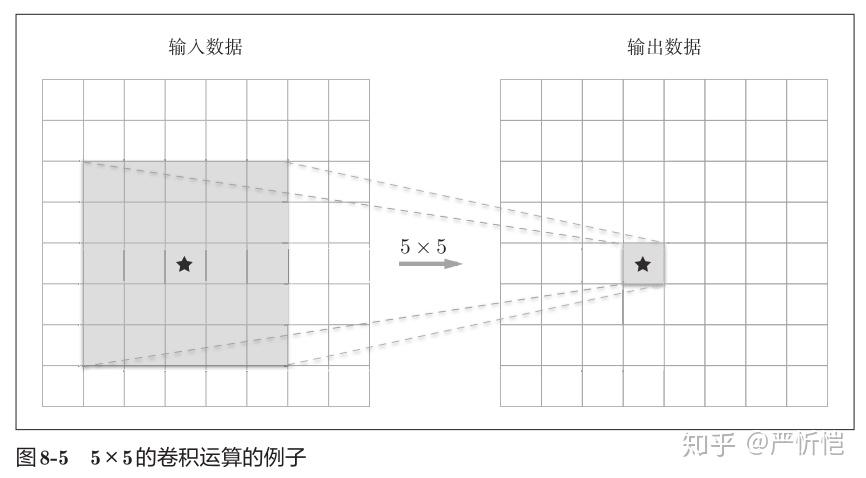



图8-5和图8-6的输出数据是“观察”了输入数据的某个5 × 5的区域后计算出来的。可以看到一次5 × 5的卷积运算的区域可以由两次3 × 3的卷积运算抵充。并且,相对于前者的参数数量25(5 × 5),后者一共是18(2 × 3 × 3),通过叠加卷积层,参数数量减少了。而且,这个参数数量之差会随着层的加深而变大。
叠加小型滤波器来加深网络的好处是可以减少参数的数量,扩大感受野(receptive field,给神经元施加变化的某个局部空间区域)。并且,通过叠加层,将ReLU等激活函数夹在卷积层的中间,进一步提高了网络的表现力。这是因为向网络添加了基于激活函数的“非线性”表现力,通过非线性函数的叠加,可以表现更加复杂的东西。
优点2)使学习更加高效。与没有加深层的网络相比,通过加深层,可以减少学习数据,从而高效地进行学习。通过加深网络,就可以分层次地分解需要学习的问题。因此,各层需要学习的问题就变成了更简单的问题。通过加深层,可以分层次地传递信息,这一点也很重要。
不过,这里需要注意的是,近几年的深层化是由大数据、计算能力等即便加深层也能正确地进行学习的新技术和环境支撑的。
深度学习在类别分类”(classification)比赛中最近的发展趋势
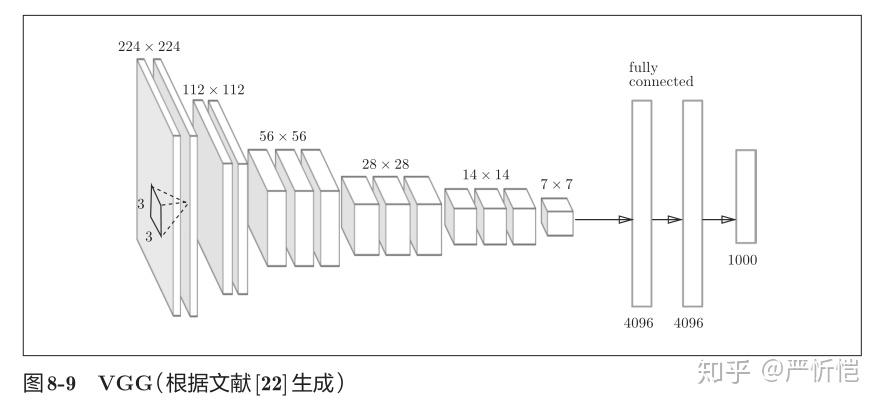
1)VGG
VGG是由卷积层和池化层构成的基础的CNN。不过,如图8-9所示,它的特点在于将有权重的层(卷积层或者全连接层)叠加至16层(或者19层),具备了深度(根据层的深度,有时也称为“VGG16”或“VGG19”)。

2)GoogLeNet
GoogLeNet的网络结构如图8-10所示。图中的矩形表示卷积层、池化层等。
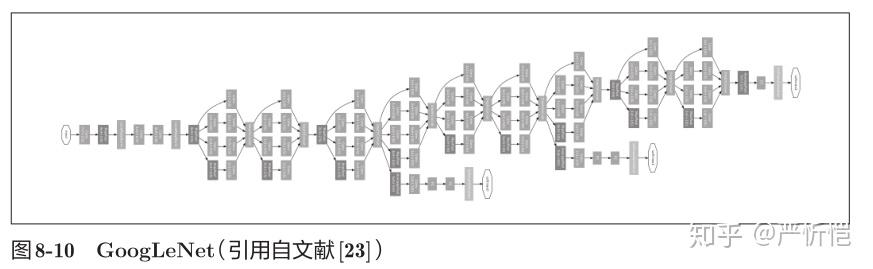

GoogLeNet在横向上有“宽度”,这称为“Inception结构”,以图8-11所示的结构为基础。Inception结构使用了多个大小不同的滤波器(和池化),最后再合并它们的结果GoogLeNet的特征就是将这个Inception结构用作一个构件(构成元素)。


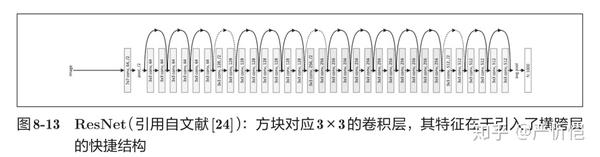
3)ResNet
ResNet 是微软团队开发的网络。它的特征在于具有比以前的网络更深的结构。由于在深度学习中,过度加深层的话,很多情况下学习将不能顺利进行,导致最终性能不佳。ResNet中为了解决这类问题,导入了“快捷结构”。如图8-12所示,快捷结构横跨(跳过)了输入数据的卷积层,将输入 x 合计到输出。
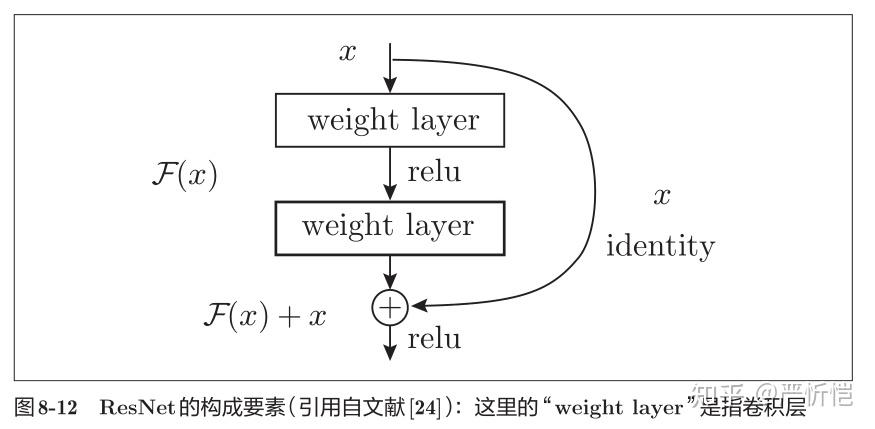

因为快捷结构只是原封不动地传递输入数据,所以反向传播时会将来自上游的梯度原封不动地传向下游。重点是不对来自上游的梯度进行任何处理,将其原封不动地传向下游。通过这个快捷结构,之前因为加深层而导致的梯度变小的梯度消失问题就有望得到缓解。
ResNet以前面介绍过的VGG网络为基础,引入快捷结构以加深层,其结果如图8-13所示。

深度学习的高速化
我们先来看一下深度学习中什么样的处理比较耗时。图8-14中以AlexNet的 forward 处理为对象,用饼图展示了各层所耗费的时间。


从图中可知,AlexNex中,大多数时间都被耗费在卷积层上。实际上,卷积层的处理时间加起来占GPU整体的95%,占CPU整体的89%!因此,如何高速、高效地进行卷积层中的运算是深度学习的一大课题。
1)基于GPU的高速化
深度学习中需要进行大量的乘积累加运算(或者大型矩阵的乘积运算)。这种大量的并行运算正是GPU所擅长的,图8-15是基于CPU和GPU进行AlexNet的学习时分别所需的时间。


通过之前介绍的 im2col 可以将卷积层进行的运算转换为大型矩阵的乘积。这个im2col 方式的实现对GPU来说是非常方便的实现方式。
2)分布式学习
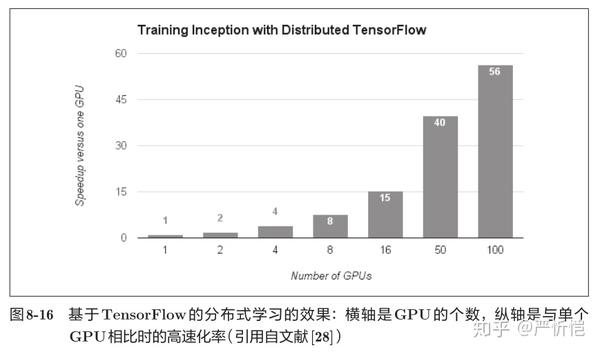
为了进一步提高深度学习所需的计算的速度,可以考虑在多个GPU或者多台机器上进行分布式计算。现在的深度学习框架中,出现了好几个支持多GPU或者多机器的分布式学习的框架。以大型数据中心的低延迟·高吞吐网络作为支撑,基于这些框架的分布式学习呈现出惊人的效果。图8-16中显示了基于TensorFlow的分布式学习的效果。

3)运算精度的位数缩减
在深度学习的高速化中,除了计算量之外,内存容量、总线带宽等也有可能成为瓶颈。关于内存容量,需要考虑将大量的权重参数或中间数据放在内存中。关于总线带宽,当流经GPU(或者CPU)总线的数据超过某个限制时,就会成为瓶颈。所以我们希望尽可能减少流经网络的数据的位数。
关于数值精度(用几位数据表示数值),我们已经知道深度学习并不那么需要数值精度的位数。这是神经网络的一个重要性质。这个性质是基于神经网络的健壮性而产生的。这里所说的健壮性是指,比如,即便输入图像附有一些小的噪声,输出结果也仍然保持不变。
在深度学习中,即便是16位的半精度浮点数(half float),也可以顺利地进行学习。
