CSIG 3DV专委会 [成果速览] — 利用法向量估计数据集来增强本征图像分解策略 [TVCG 2020 Special Issue]

本征图像分解是一种将自然图像分解为反射率图像与光照量图像的技术,可以应用于图象/视频编辑以及增强现实。然而,本征图像的分解过程是歧义的,如何减少歧义并求得一组符合人眼感知的可能解,是该项任务的主要困难与挑战。在室内场景中,复杂的材质纹理、几何结构、光照环境尤其增加了本征图像分解的难度。近年来,一些方法利用深度神经网络自动学习数据中的先验,一定程度上提升了本征图像分解的性能。但是,这一类数据驱动的方法却面临着本征图像分解领域的另一困境——缺乏训练数据,尤其是具有稠密标签的来源于真实场景的训练数据。目前,没有尚无仪器或者有效方法能够获取到真实场景的本征图像稠密真值,这限制了深度神经网络的性能。为此,一些工作开始探索相关任务的训练数据与标签,期望能够将其用于训练,从而提升本征图像分解网络的性能。今天向大家介绍一篇浙江大学CAD&CG国家重点实验室发表的论文NIID-Net,即通过现有的法向量估计数据集来增强本征图像分解。NIID-Net在场景级的光照量图估计任务上取得了目前最佳的结果,同时在反射率估计任务上也达到了前沿水准。该论文被ISMAR 2020录用,并被推荐发表在IEEE TVCG Special Issue。
[IEEE Transactions on Visualization and Computer Graphics] NIID-Net: Adapting Surface Normal Knowledge for Intrinsic Image Decomposition in Indoor Scenes
罗俊丹*,黄昭阳*,李易瑾,周晓巍,章国锋,鲍虎军
(浙江大学)
*:equal contributions
论文链接:https://ieeexplore.ieee.org/abstract/document/9199573
项目主页:https://zju3dv.github.io/niid/
开源代码:https://github.com/zju3dv/NIID-Net
1. 创新点
本征图像分解的一个难点是,目前没有方法或者设备能够为真实场景提供像素级的本征图像真值。合成数据虽然能够提供稠密真值,但是场景不够丰富且与自然图像存在偏差。相较而言,随着高质量深度传感器的发展,我们能够较为容易地收集到自然图像的稠密深度或法向量真值。因此,本文提出了NIID-Net框架,其目的是利用现有可用的表面法向量数据集来增强本征图像分解。该工作的贡献包括:
- 提出了一个统一的,同时估计表面法向量、反射率和光照量的神经网络框架NIID-Net。该网络从法向量数据集中学习场景的几何结构特征,并通过提出的法向量特征自适应器将这些特征传递到本征图像分解中去。这些几何先验能够帮助本征图像分解子网络更好地理解室内场景复杂的光照环境。
- 提出不直接预测光照量图,而是先预测法向量和集成光,然后再重建光照量图。集成光模型是本文提出的一种轻量级表示模型,其能够建模随空间位置的变化而变化的光照条件。
- 在视觉效果和数值精度上,提出的NIID-Net具有较领先的反射率估计能力,并在室内场景光照量估计方面明显优于之前的所有方法。
2. 相关工作
2.1 基于优化的本征图像分解方法
基于优化的方法[1][2][3][4]向能量方程中引入多种经验性的假设或者先验,比如,单色光照假设,Retinex假设(输入照片的局部区域中,剧烈的强度变化是由反射率的变化导致的,而较平滑的强度变化是由光照量的变化导致的),反射率稀疏性假设和光照量平滑性假设。然而,这些人工设计的约束项难以充分表达复杂的真实世界。并且,这些假设在一些环境中并不成立,比如,光照颜色区域性变化的场景和具有阴影、遮挡的区域。
2.2 基于深度学习的本征图像分解方法
这些由数据驱动的方法[5][6][7][8]利用神经网络自动地从数据中学习各种先验知识。然而,到目前为止,尚没有方法能够为真实场景提供稠密的本征图像标注。IIW[1]数据集是目前使用最为广泛的真实场景数据集。该数据集为每张图像提供由人工标注的反射率对的相对亮度比较结果:反射率像素i比j更亮、更暗或者相似。这种稀疏的标签不利于训练深度神经网络。为此,一些工作[6]提出了合成数据集,从而为反射率和光照量提供稠密的真值。但是如何解决真实数据与合成数据的域偏差,是本征图像分解任务所面临的另一个问题。
2.3 利用场景几何结构信息的本征图像分解方法
一些方法利用几何结构信息(深度或者法向量)来分辨照片的像素值变化来源于反射率变化还是光照量变化。这些方法可以被分为两类:基于几何相似性的方法[9]和基于光照模型的方法[10][11][12][13][14]。其中,基于几何相似性的方法通常采用光照量平滑性假设,并通过几何信息的相似程度来衡量光照量的相似程度。基于光照模型的方法通过某种光照模型来建立法向量与光照量之间的物理关系。由于室内场景的光照环境十分复杂,如何合理表示这种随空间位置的变化而变化的光照条件是该类本征图像分解任务的一个难点。
3. 方法描述
3.1 图像重建
本征图像分解(intrinsic image decomposition)旨在从场景或物体的照片中解析出多层潜在的物理特征,例如物体表面朝向、材质和场景的光照环境。如果假设场景为朗伯(Lambertian)场景,那么我们就可以将输入图像 I 分解为两张本征图像:反射率(reflectance)R,以及物体表面接收到的光照量(shading)S(后文简称光照量图):
I = S \times R \\ 其中表示逐颜色通道相乘。我们的方法假设场景的光照颜色是单一的,即空间中各处光照量的色度(chromaticity)是一样的,但强度(intensity)不同。本文将光照量的全局色度称为光照量颜色,记为c。在该假设下,本征图像分解公式被重写为:
I_i = S_i \times R_i = c \times S_i \times R_i \\ 其中,I、R 和c 都使用三通道的RGB色彩空间表示。S是单通道的光照量强度图。为像素位置索引。本征图像分解公式定义在线性RGB空间中。在后文进行可视化时,我们会模拟一次非线性的伽马矫正,从而将图像转换到sRGB空间:
sRGB(R_i) = R_i^{\frac{1}{\gamma}},\gamma = 2.2 \\ 3.2 集成光模型(Integrated Lighting)
为了利用几何线索,本文不直接估计光照量图,而是通过估计的法向量与光照来绘制出光照量图。本文与一些之前的工作一样,只关注朗伯场景(Lambertian scenes)。在室内场景中,物体表面一点p被来自多个方向的入射光照亮。最终接收到的光照量等于各光线的贡献之和[15]:
s = \int_{0}^{2\pi}\int_{0}^{\frac{\pi}{2}}{<n,l(\theta,\phi)>sin\theta d\theta d \phi} \\
其中n表示p处的法向量,表示穿过上半球处的入射光线。表示点积。由上式可以推导出:
s = n^x \int_{0}^{2\pi}\int_{0}^{\frac{\pi}{2}}{l(\theta,\phi)^xsin\theta d\theta d \phi} +\\ \ \ \ \ \ \ \ n^y \int_{0}^{2\pi}\int_{0}^{\frac{\pi}{2}}{l(\theta,\phi)^ysin\theta d\theta d \phi} +\\ \ \ \ n^z \int_{0}^{2\pi}\int_{0}^{\frac{\pi}{2}}{l(\theta,\phi)^zsin\theta d\theta d \phi} \\ \ \ \ \ =<n,a>\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \
其中,x、y、z 表示向量的三个分量。集成光向量a被定义为:
\left\{ \begin{matrix} a=[a^x,a^y,a^z] & \\ a^c = \int_{0}^{2\pi}\int_{0}^{\frac{\pi}{2}}{l(\theta,\phi)^xsin\theta d\theta d \phi}& c = \in \{x,y,z\} \end{matrix} \right. \\ 场景的光照量可由场景法向量与一个编码场景光照条件的向量a,经由点积运算计算得到。向量a与法向量n关联紧密,因为单位半球与光向量分布函数会随着物体表面朝向的改变而改变。因此,a只有在不改变表面朝向n的条件下,才能被用于重建光照量图。为了建模随空间位置的变化而变化的光照环境,本文提出估计逐像素的集成光向量,即集成光图A。
最终,图像重建方程重写为:
I_i = S_i \times R_i = c \times<N_i,A_i>\times \ R_i \\ 法向量图N,集成光图A,反射率图R由我们提出的NIID-Net估计得到。在图像序列编辑应用中,我们通过优化能量方程的方式估计得到了光照量颜色c。该能量方程描述于NIID-Net论文的补充材料。
3.3 NIID-Net神经网络框架
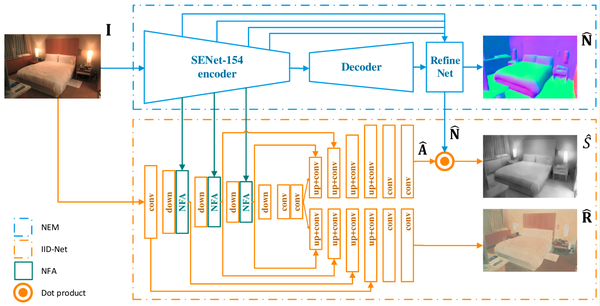

本文提出的NIID-Net,以单张sRGB图像作为输入,预测一张法向量图 \hat N ,一张光照量强度图 \hat S ,和一张反射率图 \hat R 。特别地, \hat S 由法向量 \hat N 与预测的集成光图 \hat A 经过点积运算得到。
如图 1所示,本征图像分解网络NIID-Net由一个法向量估计模块NEM(normal estimation module)和一个本征图像分解子网络IID-Net组成。NEM采用了Hu等人设计的深度估计网络[16],并修改了最后一个卷积层,从而输出三通道的法向量图。IID-Net基于U-Net[17]结构设计而成。与经典U-Net结构不同的是,IID-Net去除了光照量估计分支上,从编码器到解码器的两个最浅层跳跃链接(skip connections)。我们假设输入图像上的高频率变化来源于反射率的变化而不是光照量的变化,因此光照量估计不需要富有图像细节的浅层特征图。
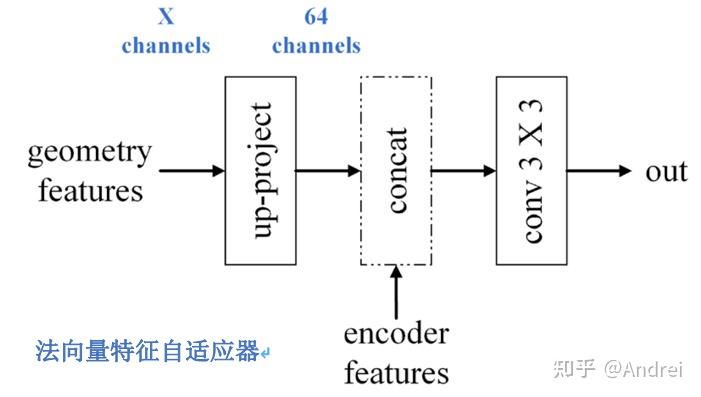

IID-Net通过提出的法向量特征自适应器NFA(normal feature adapters)吸收NEM编码器中的法向量知识。这些三维几何结构知识辅助IID-Net去理解当前场景中复杂的光照环境。IID-Net在编码器中使用了三个NFA,其结构如图 2所示。
3.4 训练
本工作利用更易于获得的、真实的法向量真值,来提升本征图像分解的性能。我们将法向量估计模块与本征图像分解子网络分别在不同的数据集上进行训练。具体而言,首先在真实场景的NYUv2[18]与DIODE[19]数据集上训练法向量估计模块NEM;之后,固定住NEM的参数,再在绘制的CGI[6]数据集上训练本征图像分解子网络IID-Net。凭借本文提出的集成光模型与法向量特征自适应器,法向量估计模块成功将预学习的法向量知识传递给IID-Net。在这些几何信息的辅助下,IID-Net取得了更好的本征图像分解性能。详细的损失函数与训练配置,请见NIID-Net论文原文。
4. 实验结果
4.1 定量对比
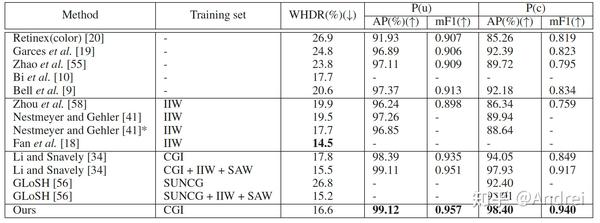

本文在IIW[1]与SAW[20]数据集上,与之前的工作进行了定量与定性的比较。在IIW数据集上,我们使用WHDR(weighted human disagreement rate,加权的人类感知分歧率)指标评估反射率估计,其数值越低越好。在SAW数据集上,我们使用AP(平均精准率)与mF1(最大F1分数)评估光照量估计,其数值越高越好。如表 1所示,与只在合成数据集(CGI 或者SUNCG)上训练的模型相比,我们的模型取得了最佳的反射图与光照量图估计结果。与在真实数据集上进一步训练的模型相比,我们的模型仍然取得了最佳的光照量图估计结果,即使NIID-Net中的IID-Net部分没有在真实数据上训练过。
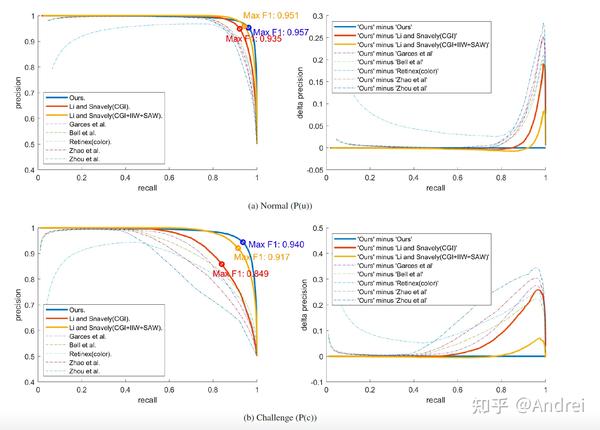

在SAW数据集上,光照量估计被视为一个二分类任务:不同空间位置的光照量是平滑还是不平滑的。不同方法的测试结果如图 3所示:左列为精准率-召回率曲线,右列为我们的方法与其他方法的精准率差值——正数表明我们的方法更优。与表示两种不同的精准率计算方式。其中的指标会降低易于估计的区域(输入图像与对应光照量都平滑的区域)的权重,着重关注具有挑战性的、纹理丰富的区域。我们提出的NIID-Net在高回归率部分(recall > 0.9) 具有显著优势。并且,由最大F1分数可知,NIID-Net在精准率和召回率之间实现了最佳平衡。
4.2 可视化对比


我们与Li 和Snavely(CGI+IIW+SAW)[6]、GLoSH(SUNCG+IIW+SAW)[13]的可视化对比,如图 4所示。对于每一个样例,第一、二行分别是估计的光照量图与估计的反射图。
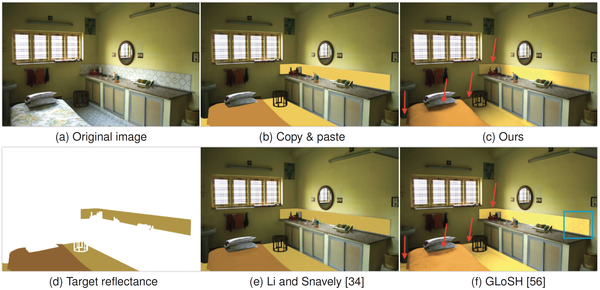

为了进一步对比视觉效果,我们实现了“反射率替换”这一图像编辑应用,如图 5所示。直接复制、粘贴反射图到输入图像上会失去光照效果。基于GLoSH[13]方法的编辑结果,受到了光照量图中残留的纹理的损害(由蓝色框圈出),并且缺少阴影效果(由红色箭头指出)。基于Li 和Snavely(CGI+IIW+SAW)[6]工作的编辑结果,几乎没有什么光影效果。相较而言,基于本文的结果所合成的图像,其光影效果最明显且纹理错误少,因此更具有视觉真实感。
5. 应用




6. 参考文献:
- Bell S, Bala K, Snavely N. Intrinsic images in the wild[J]. ACM Transactions on Graphics (TOG), 2014, 33(4): 1-12.
- Bi S, Han X, Yu Y. An L1 image transform for edge-preserving smoothing and scene-level intrinsic decomposition[J]. ACM Transactions on Graphics (TOG), 2015, 34(4): 1-12.
- Garces E, Munoz A, Lopez‐Moreno J, et al. Intrinsic images by clustering[C]//Computer graphics forum. Oxford, UK: Blackwell Publishing Ltd, 2012, 31(4): 1415-1424.
- Grosse R, Johnson M K, Adelson E H, et al. Ground truth dataset and baseline evaluations for intrinsic image algorithms[C]//2009 IEEE 12th International Conference on Computer Vision. IEEE, 2009: 2335-2342.
- Fan Q, Yang J, Hua G, et al. Revisiting deep intrinsic image decompositions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 8944-8952.
- Li Z, Snavely N. Cgintrinsics: Better intrinsic image decomposition through physically-based rendering[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 371-387.
- Narihira T, Maire M, Yu S X. Learning lightness from human judgement on relative reflectance[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2015: 2965-2973.
- Zhou T, Krahenbuhl P, Efros A A. Learning data-driven reflectance priors for intrinsic image decomposition[C]//Proceedings of the IEEE International Conference on Computer Vision. 2015: 3469-3477.
- Chen Q, Koltun V. A simple model for intrinsic image decomposition with depth cues[C]//Proceedings of the IEEE International Conference on Computer Vision. 2013: 241-248.
- Barron J T, Malik J. Shape, illumination, and reflectance from shading[J]. IEEE transactions on pattern analysis and machine intelligence, 2014, 37(8): 1670-1687
- Sengupta S, Kanazawa A, Castillo C D, et al. SfSNet: Learning Shape, Reflectance and Illuminance of Facesin the Wild'[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 6296-6305.
- Barron J T, Malik J. Intrinsic scene properties from a single rgb-d image[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2013: 17-24.
- Zhou H, Yu X, Jacobs D W. Glosh: Global-local spherical harmonics for intrinsic image decomposition[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 7820-7829.
- Jeon J, Cho S, Tong X, et al. Intrinsic image decomposition using structure-texture separation and surface normals[C]//European Conference on Computer Vision. Springer, Cham, 2014: 218-233.
- Basri R, Jacobs D W. Lambertian reflectance and linear subspaces[J]. IEEE transactions on pattern analysis and machine intelligence, 2003, 25(2): 218-233.
- Hu J, Ozay M, Zhang Y, et al. Revisiting single image depth estimation: Toward higher resolution maps with accurate object boundaries[C]//2019 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 2019: 1043-1051.
- Ronneberger O, Fischer P, Brox T. U-net: Convolutional networks for biomedical image segmentation[C]//International Conference on Medical image computing and computer-assisted intervention. Springer, Cham, 2015: 234-241.
- Silberman N, Hoiem D, Kohli P, et al. Indoor segmentation and support inference from rgbd images[C]//European conference on computer vision. Springer, Berlin, Heidelberg, 2012: 746-760.
- Vasiljevic I, Kolkin N, Zhang S, et al. Diode: A dense indoor and outdoor depth dataset[J]. arXiv preprint arXiv:1908.00463, 2019.
- Kovacs B, Bell S, Snavely N, et al. Shading annotations in the wild[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 6998-7007.
- Li Z, Snavely N. Learning intrinsic image decomposition from watching the world[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 9039-9048.
三维视觉(3DV)专委会定位于推动三维视觉理论、技术与应用的发展,探讨人工智能时代三维视觉的新理论和新技术,通过融合计算机视觉、图形学、大数据以及机器人技术的最新进展,推动三维视觉理论和方法体系的构建和发展、提高三维视觉算法及系统的易用性及效率、加快三维视觉技术的实用化和产业落地。专委会积极建立常态化的学术交流机制,通过相关领域专家学者的思想碰撞,达成研究方向及技术应用上的共识,推动相关领域的研究进展及产学研合作。
成果速览主要聚焦于近年内在3DV领域的高质量原创研究(包括但不局限于论文、竞赛成果、应用展示、研究报告等),旨在为3DV领域的学者提供学术交流平台,增进对相互工作的了解。欢迎大家推荐或自荐优秀研究成果,如您有意成果展示,请与CSIG 3DV秘书处联系。联系方式:武玉伟(wuyuwei@bit.edu.cn),郭裕兰(yulan.guo@nudt.edu.cn)。
