
Reinforcement Learning: An Introduction Chapter 1

本章撰写: @drjdtc
本章校对: @xyd-shawn @drjdtc
译者注
本文本质上是有选择性的翻译。前段时间老板帮着我改论文,虽然改得我心态有点炸,但是还是教会了我不少写论文的方法,拿那种眼光来审视《Reinforcement Learning: An Introduction》,感觉这本书写得好像也不是很好(我是不是飘了),具体体现在有所重复,以及一个概念没有先定义就直接使用了。水平有限,由于不能保证自己看完之后的总结能够完全表达出原文的意思,因此,主要是边看边翻译,删掉了一些认为确实无关紧要的部分。例如讲强化学习历史之类的。
一般对于强化学习中的专有名词我们保留其英文形式,如action,environment等(前面一小部分还没想这么写,还用的中文,如果看的人多的话以后会改掉),以及一些感觉中文不能很好地表达出原意的也会选择采用英文词汇。另外,有些句子用中文不太好翻,但是感觉句子整句用英文不太好,所以还是强翻了。如果有地方看不太明白,可以在评论区提问~
不过有一说一,感觉这本书有的地方写得确实比较confusing。所以如果有不明白的,不一定是我们的锅,有可能就是原文写得不好哈哈。
Chapter 1 The Reinforcement Learning Problem
谈论学习的本质时,人们往往首先想到的是从与环境的互动中学习。当一个婴儿挥舞手臂,环顾四周时,他没有一个明确的老师,但是与environment通过感觉器官有直接的联系。这些联系能够产生关于起因、影响、动作后果以及为了达到目标应该怎么做等有价值的信息。在我们一生中,这些互动毫无疑问是我们获取我们环境和我们自身信息的主要来源。
这本书探索了从与环境的互动中学习的计算方法:
- 考虑理想情况下的学习,并且对各种学习方法的有效性进行评估。
- 解决科学经济领域相关问题,并且通过计算机实验、数学分析等来评估。
1.1 Reinforcement Learning
强化学习主要是学习what to do,如何将情况与动作对应起来,即在当前情况下该如何选择动作,以达到最大化奖励的目的。
强化学习有三个重要特征:
- 强化学习是一个闭环的问题
learning system的动作也会影响其之后的输入。
2. 没有直接的对于该如何选择action的指示
learner并不直接告知采取哪个行动,而是去发现哪个动作将会产生最大的奖励值。
3. 动作的后果要在一段时间后才得以呈现
在最复杂的情况下,action不光影响直接的reward,还影响接下来的所有state。
强化学习的主体一般被称为agent,其与environment互动以达到某种目的。所有强化学习的agent有明确的目标,能够感知全部或者部分environment,并且选择action执行来影响environment。除此之外,还要假设在最开始,agent需要在对于所面对的environment一无所知的情况下采取行动。
强化学习与传统的监督学习和非监督学习不同:
- 监督学习的训练集是一组标注好的数据。应用到强化学习场景中就是有在某种情形下标注的正确动作的信息。监督学习的目标主要是总结概括,以此推断不在训练集中的情况。但是在与environment互动的场景下,监督学习往往不现实,因为很难获取到足够多并且足够有代表性的标注信息,(在特定场景下,agent应该采取什么action)。在未标注的情况下,agent需要从自己的experience中学习如何使自己利益最大化。
- 非监督学习一般是寻找未标注数据中同一类的结构信息,而强化学习专注于为agent实现reward最大化。
因此监督学习与非监督学习看上去把机器学习分成了两类,但其实并没有。
对于强化学习来说有个问题就是如何平衡exploration和exploitation。为了获取更多的reward,agent一般偏好于过去尝试过的被证明有用的action。但是为了发现这些action,它有需要去尝试那些之前没有选过的。因此,agent一方面需要exploit它已经知道的信息来获取reward,但另一方面也需要explore以此在未来能够作出更好的选择。agent必须尝试各种action并逐渐倾向于那些看上去最好的action。在一个随机任务中,每个action都应该被试很多遍,来获取其期望reward的可靠估计。而在最纯粹的监督学习与非监督学习,并没有这种exploration-exploitation的问题。
1.2 Examples
这部分举了一些例子(不详细说明了)。所有例子都有decision-making agent和其environment之间的interaction。尽管agent可能对于environment并不确定,但其仍然努力追寻达到目标。agent的action能够影响environment,进而影响之后agent的选择。因此正确的选择需要考虑动作的间接的有延迟的后果。因此需要有预见和规划。
与此同时,action所产生的影响并不能被完全预测,因此,agent必须时常监视其environment,然后依此做出反应。有明确目标的例子中,agent可以依据直接感知到的情况来判断其为了目标所取得的进步。例如下棋者知道自己赢或者输,精炼厂的控制器知道已经产出了多少石油。
agent以及environment并不一定与我们通常意义上认为的一致。agent并不一定是一个完整的机器人或者动物,environment也并不一定是机器人的外在environment。比如机器人的电池也可以作为其环境。
agent可以利用其经历来提升performance。
1.3 Elements of Reinforcement Learning
一个强化学习系统一般包括:
- a policy
- a reward signal
- a value function
- a model of environment (optinally)
policy
policy是从感知到的environment的state到在这些state下要执行的action的映射。这对应于心理学中stimulus-response rules or associations。在一些情况下,policy可以是简单的函数或者是查表。而在别的情况下,可能会需要更多的计算,例如暴力搜索。policy是强化学习agent的核心因为一个policy便可以单独决定agent的行为。另外,policy可能是随机的。
reward signal
reward signal定义了强化学习问题的目标(goal)。在每个时间步内,environment给agent发送一个单值,reward。agent唯一的目标便是在长时间运行中最大化接收到的总的reward。reward signal定义了一件事对于agent来说是好是坏。在生物系统中,reward有点类似于开心或者痛苦的情绪。这些非常直接地定义了agent所面对的问题的特征。任一时刻发送给agent的reward取决于agent当前的action以及当前environment的state。agent影响reward signal的唯一方式就是通过action直接影响reward,或者通过改变environment的state间接影响。
reward signal是改变policy的首要基础。如果一个policy选择了低reward的action,则之后在同样情况下,policy可能会改为选其他的action。总的来说,reward signal可能是environment state和采取的action的函数(也可以带有随机性)。
value function
reward signal表示的是在直接感受下哪个是好的。而value function则是表示从长期来看,什么是好的。也就是state的value(价值)是一个agent从当前state开始,在未来期望累积的总的reward。reward定义的是环境state直接的好处,而value是state长期的好处,考虑了之后可能会出现的state以及这些state下的reward。例如一个state可能会产生一个低的reward,但是有着高的value,因为跟着它的通常是一些会产生高reward的state。反之亦然。
reward是首要的,而value是其次的,因为没有reward就没有value。但是当我们做决策并对决策进行评估时,更关注的是value。对于action的选择是基于value来判断的。我们追寻的是带来最高value的state而不是最高的reward,因为这些action从长远上来讲会获得最多的reward。但不幸的是,决定value要比决定reward难得多。reward是由environment直接给出的,但是value是需要对agent的整个执行时间内的状况进行观察,以此对value进行估计和重估计。事实上,强化学习算法中最重要的部分就是如何有效地估计value。
model of the environment
model of the environment是用来模拟真实environment的行径的,或者说是对environment会如何表现的推断。例如,给定一个state和action,这个model会预测因此产生的下一state和下一reward。model一般用在planning(规划)里,可以在真正执行之前通过考虑未来的可能情况来决定一系列动作。利用model和planning用来解决强化学习问题的方法被称为model-based方法,作为更简单的model-free方法的对照。model-free方法主要是指通过trial-and-error学习,是planning的对立。(译者注:就是planning不需要直接执行action与真实的environment互动,可以对environment建模,然后自己跟这个environment模型互动。这样就叫planning)
1.4 Limitations and Scope
这本书讲到的大部分方法都会估计value function,但是其实解决强化学习问题并不严格需要去估计value function。例如遗传算法、模拟退火算法等用来解决强化学习问题却从未关注value function。这些方法对很多没有学习能力的agent的整个存活时间期间的表现进行评估,每一个agent都以不同的policy来与environment进行互动,然后选择能获取最大reward的。这些被称为evolutionary方法。这些方法非常类似于生物的进化过程。如果policy空间足够小,或者有足够的时间进行搜索,这时evolutionary方法比较有效。除此之外,在agent不能准确感知environment的情况下,evolutionary方法也有着优势。
这部分主要是说evolutionary方法没有利用与环境之间的interaction。因此并不认为相关方法能够很好地解决强化学习问题,因此这本书在使用“强化学习方法”这个概念时,不包括evolutionary方法。
不过有些方法也不关注value function,而是直接在通过各种参数定义的policy空间进行搜索,来提升policy的performance。例如policy gradient方法。
我们说一个强化学习agent的目标是最大化数值的reward signal,其实并不固执地必须要真正地达到最大化的目标。尽可能最大化一个量并不意味着这个量一定会被最大化。强化学习的agent主要还是想办法提升它接收到的reward,有很多因素会阻止它获取最大值,即使最大值客观存在。也就是说,优化并不等同于最优。
1.5 An Extended Example: Tic-Tac-Toe
为了说明强化学习的思想,以及与其他方法进行对比,考虑一个简单的例子。
tic-tac-toe游戏。两位玩家依次在一个3\times 3 的表中下棋,一个画X,一个画O。当有一个玩家能够将自己的棋子摆满某一行某一列或者斜对角时,就赢了。例如下表中X玩家获胜:

如果整个表都被填满了而没有人获胜,则平局。由于一个比较熟练的玩家可以保证不败,我们假设我们的对手并不是一个完美的玩家,有时他会下错地方。我们认为输和平局对我们来说是一样坏的,我们该如何构建一个玩家,其能够发现对手的不完美并且学习如何最大化自己获胜的可能性?
这个问题很难通过一些经典的方法来获得一个令人满意的结果。一些经典的序列决策方法,例如动态规划能够对任意对手计算出一个最优的解决办法,但是需要输入对手的所有细节,包括在特定state下,对手具体下到某一点的概率,但假设这些信息不是先验的。但是另一方面,这些信息可以从过往的经验中估计出来,通过与对手对战多次。最好的方法是先学习对手的行为模型,然后给定对手的近似模型下应用动态规划来计算最优的解决方法。这与我们之后在本书中研究的强化学习方法没有什么不同。
evolutionary方法直接搜索可能的policy空间来获取高概率获胜的policy。在这里policy是告诉玩家在这个游戏每种可能的state下,该往哪下棋。对于每个考虑的policy,通过玩多把游戏对于其获胜概率做评估,这些评估决定了哪些policy能够接下来被考虑。一个典型的evolutionary方法就像在policy空间登山一样,接连评估policy,以此获得一些提升。(参考遗传算法的思想,这里不赘述了)
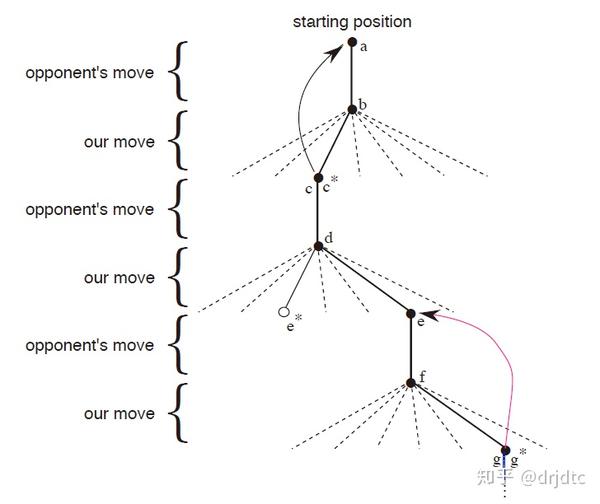

tic-tac-toe示意图。实线表示游戏中实际采取的动作,虚线表示强化学习的learner考虑了但是实际没执行的动作。我们执行的第二个动作其实是exploratory的,即使其他的动作可能value更高。
接下来介绍利用value function来玩tic-tac-toe游戏。首先对这个游戏每个可能的state建立一个数表,每个数都是从这个state开始获胜概率的最新估计。我们把这个估计看做这个state的value。State A有比B更高的value,说明A比B好,也就是当前估计下,从state A开始获胜的概率比从B开始大。
假设我们是下X的,那么所有有三个X在一行(一列,斜对角)的state的获胜概率是1,所有三个O在一行(一列,斜对角)或者填满(平局)的state的获胜概率是0,其余所有state的初始概率是0.5,代表我们猜测我们有一半几率获胜。
与对手玩多轮游戏。为了选择下一步该下在哪,我们检测了我们每一个可能的落子之后产生的state,在表中查询他们当前的value。一般情况下,我们是greedy的,也就是选择那些会导致有最高value的state的地方落子,也就是有最高获胜可能性的地方。偶尔,我们会在其他位置里随机选一个落子。这种叫exploratory的落子,因为这能让我们去经历之前没见过的state。
在玩这个游戏的过程中,不停改变这些state的value,尽可能让它们更准确地估计获胜概率。每一次落子之后,将之前state的value向之后state的value靠近。 s 表示greedy地落子之前的state, s' 表示落子之后地state, V(s) 表示估计 s 的value。对于 V(s) 的更新可以写为
V(s)\leftarrow V(s)+\alpha\left[V(s')-V(s)\right]
\alpha 为步长,是一个小的分数,影响学习率。这种更新规则被称作temporal-difference学习方法。因为其更新是基于两个不同时间对value的估计之差 V(s')-V(s) 的。
如果步长参数随着时间适当减小,对于任意固定的对手,这个方法是可以收敛到每个state下我们真实的获胜概率的。更进一步地,我们所选择的落子的地方(除了exploratory的选择)事实上都是对抗对手最优的选择。也就是说,这种方法能够收敛到最优的policy。
这个例子展示了evolutionary方法和基于value function的方法的不同。evolutionary方法是采用固定的策略,去玩多轮游戏,或者利用给对手建模仿真多轮游戏。获胜的频率是获胜概率的无偏估计。但是这种方法只关心最后的输赢,中间过程都被忽略了。也就是说,只要这次赢了,所有经历过的动作都被认为是可以信任的,即使有些动作其实会使得获胜概率变小。而相反地,value function可以对所有单独的state进行评估。最后evolutionary方法和value function方法都在policy空间搜索最优的policy,但是对于value function的学习利用了对局过程中产生的信息。
这个简单的例子也展示了强化学习方法的一些关键特性。首先是强调与environment的interaction,在这个例子中就是与对手的对局。其次,有明确的目标,想做出正确的选择需要考虑选择所造成的有延迟的影响。
例子说明的是两个人之间的游戏,实际上强化学习方法并不局限于此,其可以应用到没有外部对手对的场景,换句话说,可以“game against nature”。并且也不局限于那些可以分成多个episode的问题。
强化学习也能应用于那些不能分成离散时间步的问题。应用到连续时间问题会变得更复杂,但是在介绍性质的时候会忽略这一点。
tic-tac-toe已经是个相当小的问题了,其state集是有限的。而强化学习是可以被用到state集非常大甚至是无限的场景中的。
在tic-tac-toe例子中,是没有关于游戏规则的先验信息的,但是先验信息其实是可以以不同的方式加入到强化学习方法中以获得有效的学习的。在tic-tac-toe例子中,我们可以获知真实的state,而强化学习也可以应用到state被部分隐藏的情况,或者不同state在agent看来是一样的情况。
tic-tac-toe玩家能够知道因其可能采取的动作(下棋)所引起的state的改变。为了达到这个效果,其需要对于游戏建模,使其能够知道environment对于那些实际没有执行的action如何作出反应。强化学习也可以被应用到那些缺少此类模型的问题。
另一方面,很多强化学习方法根本不需要environment的模型。model-free的系统甚至不知道他们的environment如何对action做出反应。如果把tic-tac-toe看作是model-free的,就是说没有关于对手的模型。由于模型需要准确才有用,因此model-freee的方法比那些瓶颈在建立准确environment模型的方法有优势。model-free方法也可以是model-based方法的组成部分。这本书会先介绍model-free的方法,然后讨论如何将其应用到复杂的model-based方法中。
1.6 Summary
强化学习是一种应用于goal-directed learning和decision-making问题的计算方法。强化学习区别于其他计算方法的主要的点在于其关注点在agent和environment之间的interaction,而不依靠对于environment完全知晓。强化学习是用来解决从与environment之间的interaction学习以达到长期目标的计算问题的。
强化学习中用state,action,reward来正式定义与environment之间的interaction。这种方法用一种简单的方式定义了人工智能问题中一些简单的特征。这些特征包括原因和影响,不确定性以及明确目标的存在性。
大部分强化学习方法中value function是最关键的特征,也是这本书中着重考虑的特征。之所以把value function看得这么重要是因为其对于policy空间的有效搜索非常重要,这也是将强化学习方法与evolutionary方法区别开来的标志。evolutionary方法是对policy进行评估从进而在policy空间搜索最优policy。
