Google AI - 可配置的推荐系统仿真环境

translate from : RecSim: A Configurable Simulation Platform for Recommender Systems
近日google可真的煞费心思需要建立自己的业界标准和威望,不仅连续推出了语音、新的统一图像dataset和benchmark之外,还连续推出了好几篇相关的文章来刷自己的榜单。今天这篇文章则是建立一个推荐系统的仿真环境,有木有效不知道,但是推荐系统方面走在前沿的仍然是google。
回到正文,用户和推荐系统之间的交方式最近随着包括机器学习、语音识别、自然语言处理、图像识别等任务的发展而快速地变化。另外关于协作交互式推荐引擎(collaborative interactive recommenders,CIR)已经成为在线服务的一个明确的目标,什么是CIR?推荐系统的推荐引擎有意地和用户进行交互,去满足该用户的实际需求。
虽然CIR的概念非常好,但是CIR的对于实际环境中部署和开发推荐模型,仍受到用户与推荐系统交互时序的特征质量的影响。
之所有要翻译这篇文章是因为看到很明显的几个字眼,强化学习(reinfocement learning)。要知道在18年之后Google不满足于使用Deep learning去执行推荐任务,于是连续性地发表了几篇使用Reinforcment learning去执行推荐任务文章。继续回到文章,强化学习(RL)是解决时序决策问题的标准机器学习方法,因此该技术非常合适在推荐系统中应用,其有着自然的建模规范和优化时序交互的能力。
但是!无论实践还是研究方面,CIR技术都没有充分被使用和得到充分的研究。其中一个主要的原因是缺乏用于时序推荐引擎的通用仿真平台,而仿真平台在推荐算法方面的重要性就像在机器人领域中的仿真平台一样。
Google研究者们的这句话确实感同深受,对于研究算法或者尝试新的算法之间,我们很难去预估该推荐算法的有效性,其中最好的办法之一就是分流,17年跟蚂蚁金服的朋友交流的时候,他们一个有用的做法就是分流,不同流量使用不同的推荐算法进行评估,效果不好则回滚版本。但是像在终端没有网络的情况下如何做推荐呢?内置的推荐引擎可能需要几天、甚至几周才会学习到用户有效的行为,这种情况下分流的风险大,且不实际。
为了解决上面提到的问题,Google研究者们提出了RᴇᴄSɪᴍ,一个为强化学习在推荐系统中应用而生的可配置仿真平台(戳这里)。RᴇᴄSɪᴍ平台可以让研究者或者开发者在综合推荐平台去测试他们的推荐算法的限制。那么RᴇᴄSɪᴍ的目标是什么吗?文章指出,RᴇᴄSɪᴍ旨在模拟真实推荐系统中用户的实际行为,并作为受控环境去开发、测试、评估、比较推荐引擎的算法那,尤其是伟时序系统交互二设计的强化学习推荐引擎。
作为一个开源的仿真平台,RᴇᴄSɪᴍ可以1)促进推荐系统和强化学习之间的交叉研究;2)鼓励算法模型的共享和可复制;3)帮助使用强化学习推荐引擎的用户可以在非实际环境下,快速地测试和调整算法模型;4)通过仿真的用户行为模型,在没有泄露用户数据和行业敏感策略的情况下,充当学术和产业合作的资源。
Reinforcement Learning and Recommendation Systems
好了,上面说了这么多都是背景交代,没办法,每篇论文都要说很多背景,做很多背景研究才可以提出自己的想法,下面来关注一下实际的RᴇᴄSɪᴍ仿真平台。
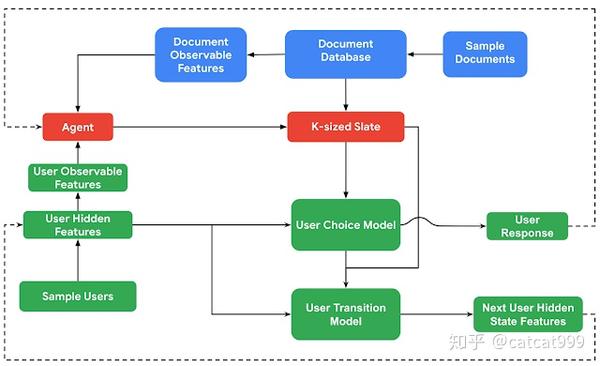
RᴇᴄSɪᴍ模拟推荐agent和用户模型、文档模型和用户选择模型组成的环境的交互。 该推荐agent通过向用户推荐文档集或列表来与环境进行交互,并且可以通过访问单用户和文档的察特征,并提供回推荐引擎。
其中,用户模型从可配置的用户特征中对用户进行分布式采样,这些可配置的用户特征可以有:潜在特征,例如兴趣或满意度;可观察特征,例如用户统计;以及行为特征,例如访问频率或时间预算。文档模型则从先验的文档特征分布中进行采样。与RᴇᴄSɪᴍ的所有其他组件一样,该先验文档特征可以由开发者指定,并可能从应用程序数据中得到(学习到)。
当然啦,上面提及到的用户特征和文档特征都是可定制的。当agent向用户推荐文档时,推荐结果则由用户选择模型提供,该用户选择模型可以访问文档特征和所有的用户特征。对于用户的反馈则由潜在的文档特征决定,例如文档的主体和质量。当一个文档被消费之后,用户满意度和兴趣则会发生变化,因此用户状态可以通过可配置的用户转换模型进行转变。
RᴇᴄSɪᴍ为研究者或从业者提供了感兴趣的用户行为的特定方面的能力的简单配置方式,这可以为用户新的兴趣点和新的行为,去进行建模和设计新的算法提供关键能力。这类型的抽象成都对于科学建模是很重要的!因此,对用户行为的所有要素进行高保真模拟并不是RᴇᴄSɪᴍ的目标。话虽如此,Google研究者仍然希望RᴇᴄSɪᴍ在某种程度下可以用作支持“模拟到真实”仿真平台。

Applications
Google研究者已经使用RᴇᴄSɪᴍ研究了强化学习在推荐系统中应用的几个关键问题点。例如,slate推荐会引起在强化学习中,因为动作空间随着slate的大小呈现指数增长,这给探索和动作优化问题带来巨大的挑战。对于这些问题,Google研究者利用RᴇᴄSɪᴍ平台提出了一个算法SlateQ: A Tractable Decomposition for Reinforcement Learning with Recommendation Sets,该技术充分地利用用户行为选择去精确地估计推荐名单中的Q值(Q value),并应用在Youtobe上面啦。另外,RᴇᴄSɪᴍ可以用于测试研究的实验结果,例如算法的实际表现和鲁棒性。
后话了,不知道抖音的视频推荐算法与Google 的Youtobe推荐算法哪家强?各有什么差一点?有待分析