零代码功能富集分析(DAVID数据库、KOBAS数据库使用教程)

本文原发于简书博客(柳叶刀与小鼠标):零代码功能富集分析(DAVID数据库、KOBAS数据库使用教程)
DAVID数据库
简介
DAVID (the Database for Annotation,Visualization and Integrated Discovery)的网址是http://david.abcc.ncifcrf.gov/。 DAVID是一个生物信息数据库,也是一款在线免费分析软件,其整合了生物学数据和分析工具,为大规模的基因或蛋白列表(成百上千个基因ID或者蛋白ID列表)提供系统综合的生物功能注释信息,帮助用户从中提取生物学信息。目前DAVID数据库主要用于差异基因的功能和通路富集分析,对很多科研工作者来说,是个非常好的工具。
DAVID这个工具在2003年发布,目前版本是DAVID 6.8 。和其他类似的分析工具一样,都是将输入列表中的基因关联到生物学注释term上,进而通过统计学方法找出最显著富集的生物学注释。
- 准备输入文件
需要一列类似的含有基因名数据
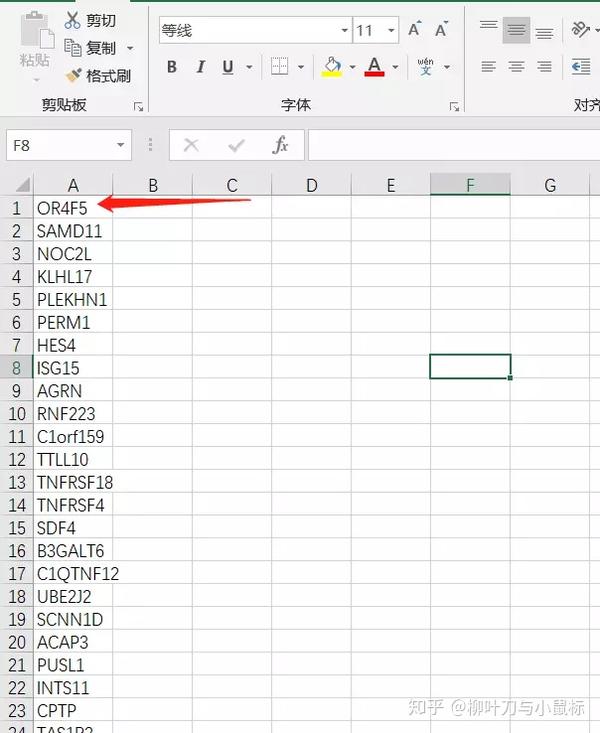

- 开始进入分析
选择functioal annotation选项
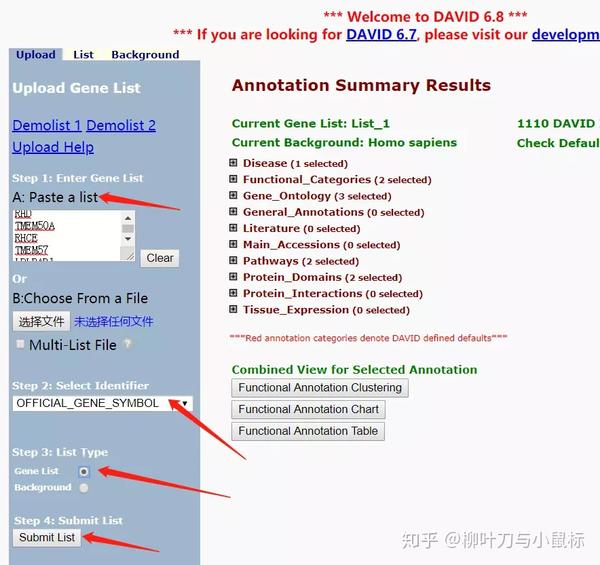

(1)粘贴基因(2)选择official—gene-symbol(3)选择genelist(4)提交list
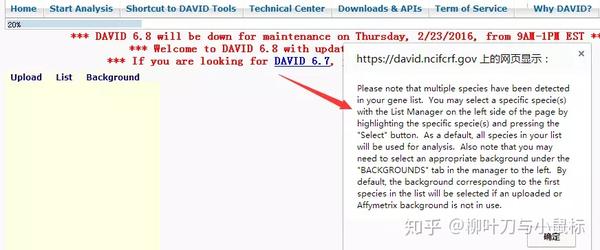

提交完成后,界面会弹出上面所示的提示框 ,按确定即可。
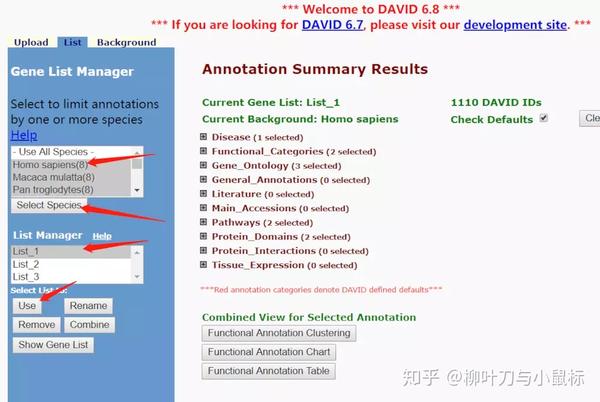

按照如上流程进行,1 list1——2 Use——3选择物种“homo sapines(人类)”——4 点击Select Species


首先把所有默认选项都清空,只选择Gene_Ontology下的GOTERM_BP_DIRECT和CC、MP和Pathways 下的KEGG_PATHWAY ,最后点击 Functional Annotation chart,结果就出来了。
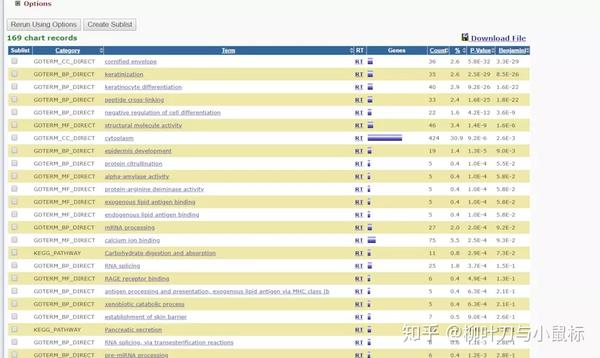

可以点击右上角的Download File 按钮,将结果进行复制保存。其中结果包括功能和通路两部分。
Kobas数据库
简介
KOBAS(KEGG Orthology Based Annotation System)是一个被广泛用于基因/蛋白质功能注释和功能集富集的网页版数据库。使用者在给定一组基因或蛋白质,该数据库可以确定某些通路和基因本体论(GO)是否有统计学显着性。
KOBAS 3.0的输入不支持gene symbol,所以使用者在使用前需将Symbol ID转换成Entrez Gene ID(或者)ensembl格式的ID。
推荐进行基因ID转换的网站:gprofiler : http://biit.cs.ut.ee/gprofiler/gconvert.cgi
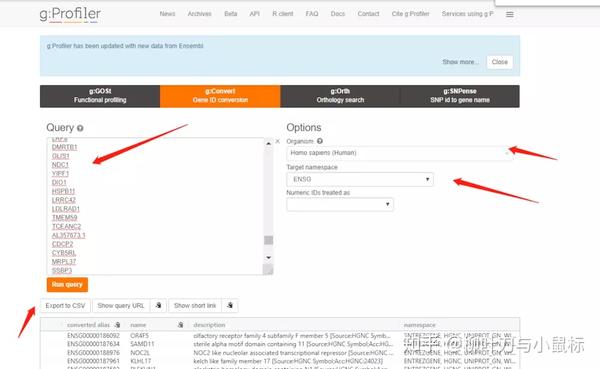

使用者需要(1)上传或者粘贴含有基因列表的数据(2)选择物种为homo sapines(人类)(3)确定输出格式为ENSG(4)点击RUN(5)下载注释后的数据:Export to CSV。下载的注释后的数据如下所示:
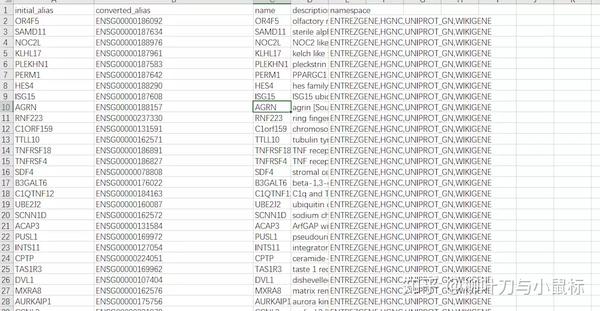

KOBAS注释
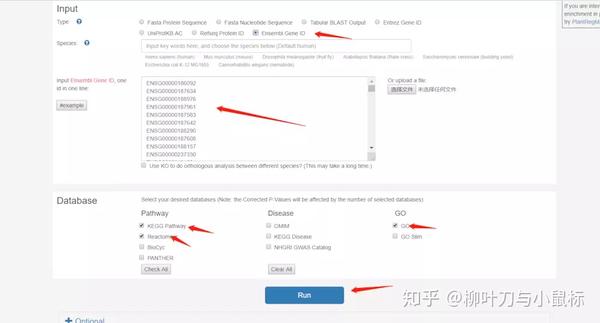
使用者将转换后的ID输入http://kobas.cbi.pku.edu.cn/anno_iden.php,根据研究对象类型,进行相应选择:选择KEGG Pathway与GO,点击Run;

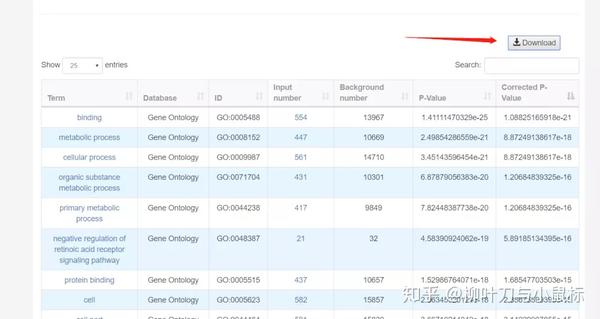
将富集结果下载:

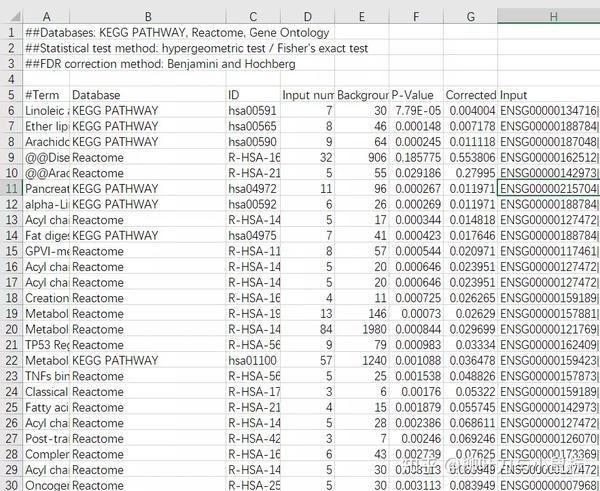
下载得到富集结果如下:

GO与KEGG富集分析,DAVID和KOBAS是比较简单同时受欢迎和认可的选择。
发布于 2019-07-26 02:28
