论文阅读-LSN-图像篡改检测

《Learning Rich Features for Image Manipulation Detection》阅读翻译
论文链接:
题目:图像篡改检测中的丰富特征学习
摘要
图像篡改检测不同于传统的目标检测, 因为比起图像内容来说,它更注重检测那些人工篡改的部分, 这表明它需要学习更丰富的特征。我们提出了一个双流faster r - cnn 网络 , 并训练它的端到端以检测给定图像被篡改的区域。一种是 RGB 流, 其目的是从 RGB图像输入中提取特征, 以查找被篡改的部分, 如强烈的对比度差、不自然的篡改边界等。另一种是噪声流, 它利用从隐写分析丰富的模型过滤层中提取的噪声特征来发现真实区域和被篡改区域之间的噪声不一致。然后, 我们通过双线性池图层融合两个流中的特征, 以进一步合并这两种模式。在四个标准图像处理数据集上进行的实验表明, 我们的双流框架优于每个单独的流, ,与其他具有调整大小和压缩的鲁棒性的替代方法相比,实现了最先进的性能。
1.简介
随着图像编辑技术和用户友好编辑软件的进步 , 对图像生成过程进行低成本的篡改现象已普遍存在。在篡改技术中, 拼接、复制-移动和删除是最常见的操作。图像拼接是指将区域从一张真实图像复制并粘贴到其他图像中, 复制-移动是复制某一部分副本并粘贴在同一图像中的其他区域,删除操作可从真实图像中删除指定区域, 然后进行图像修补。有时会在进行这些篡改操作之后使用高斯平滑。如图1所示,即使仔细检查, 人类也很难识别被篡改的区域。


因此, 区分真实的图像和被篡改的图像变得越来越具有挑战性。以这一主题为重点的新兴研究-:图像取证,变得非常重要, 它旨在防止一些攻击者将其被篡改的图像肆无忌惮地应用于商业或政治目的。
与当前的对象检测网络 [28、18、10、32、16、31] 旨在检测图像中不同类别的所有对象不同, 图像篡改检测网络的目标是只检测被篡改的区域 (通常是对象)。通过对 RGB 图像内容和图像噪声特征的探索, 探讨如何利用目标检测网络进行图像篡改检测。
最近在图像取证方面的工作主要有:利用了局部噪声特征 [35, 26] 和相机滤波阵列 CFA 模式 [19] 等线索, 检测图像中的某个特定补丁或像素 [11] 是否被篡改, 并本地化已被篡改的区域 [19, 9, 6]。这些方法大多集中在一个单一的篡改技术上。
最近提出关于被篡改部分的基于长短时的网络LSTM 体系结构 [2], 通过学习检测被篡改的边缘来检测图像,该方法对多种篡改的检测都具有鲁棒性。在这里 , 我们提出了一个新的双流操作检测框架 , 它不仅模拟视觉篡改的效果( 例如 , 在目标边缘附近寻找被篡改的部分 ) , 而且还捕获局部噪声特征中的不一致。
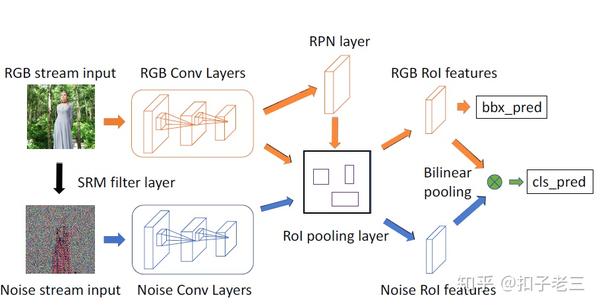

更具体地说, 我们在一个双流网络中采用了faster r-cnn [28], 并执行端到端训练。方法摘要如图2所示。像faster r-cnn [28] 这样的深度学习检测模型在多尺度目标检测方面已经表现出了良好的性能。区域建议网络 RPN是faster r-cnn 中的组件, 负责检测可能包含感兴趣对象的图像区域, 它也可用于图像篡改检测。
为了区分被篡改的区域和真实区域, 我们利用RGB通道中的特征来捕获线索, 例如被篡改边界的视觉的不一致以及被篡改区域和真实区域之间的对比。第二个流分析图像中的局部噪声特征。
第二个流背后的原理是, 当一个对象从一个图像 (源) 中删除并粘贴到另一个 (目标) 时, 源图像和目标图像之间的噪声特征不太可能是匹配的。如果用户之后对被篡改的图像进行压缩处理 [26, 4], 则可以在一定程度上掩盖这些差异。为了利用这些特征, 我们将RGB图像转换为噪声域, 并将局部噪声特征用作第二流的输入。
从图像生成噪声特征的方法有很多种。在最近关于用于操作分类的隐分析丰富模型 SRM 的基础上, 选择 SRM过滤程序来产生噪声特征, 并将其作为第二个faster r-cn 网络的输入通道。
用来判断载体是否含有秘密信息的方法被称为隐写分析(steganalysis)
对于每个感兴趣的区域ROI,都采用基于双流的篡改检测, 这两个流中的特征为进行双线性集合。以前的图像处理数据集 [25、1、12、30] 只包含几百张图像, 不足以训练的深网络。为了克服这一问题, 我们创建了一个综合的基于 coco [22] 的篡改数据集, 用来我们的模型进行预训练, 然后在不同的数据集中对模型进行微调以进行测试。我们的方法在四个标准数据集中的实验结果都展现了很有希望的性能。
我们的贡献有两个方面。首先, 我们展示了如何将faster r-cnn 框架应用于双流模式的图像篡改检测。我们探讨了两种模式, RBG部分的篡改和局部噪声特征的不一致, 将它们聚集在一起, 以识别被篡改的区域。其次, 我们证明了这两个流对于检测不同的篡改技术是互补的, 在四个图像篡改检测数据集上的性能较之于先进水平都有明显提高。
2.相关工作
图像取证的研究包括研究对图像进行低级人工篡改的各种方法, 包括双 jpeg 压缩 [4]、CFA阵列分析 [19] 和局部噪声分析 [7]。具体而言, Banchi 等人 [4] 提出了一个概率模型来估计不同区域的 DCT系数和量化因子的方法。
我们假设被篡改的区域会干扰原有模式,基于CFA的方法使用相机内部滤波模式,引入低级统计数据。Goljan 等人 [19] 提出了一个高斯混合模型GMM, 对 CFA当前区域 (真实区域) 和 CFA缺失区域 (被篡改区域) 进行分类。
近年来, 基于局部噪声特征的方法, 如隐身分析丰富模型 SRM [15], 在图像取证任务中表现出了很有希望的性能。这些方法从相邻像素中提取局部噪声特征, 捕获被篡改区域与真实区域之间的不一致。Cozzolino 等人 [7] 探讨并展示了SRM特征在区分被篡改和真实区域方面的性能。它们还将量化和截断操作与卷积神经网络 CNN结合一起,,以执行局部操作 [8]。Rao 等人 [27] 使用SRM过滤程序作为 CNN的初始化, 以提高检测精度。这些方法大多集中在特定的篡改部分上, 仅限于特定的篡改方法。我们还使用这些SRM程序来提取用作faster r-cnn 网络输入的低级噪声, 并学习从噪声功能中捕获篡改痕迹。此外, 还将训练并行的RGB流, 以模拟中高级的视觉篡改模式。
随着深度学习技术在各种计算机视觉和图像处理任务中的成功, 一些新的技术也采用了深度学习来解决图像处理检测问题。Chen 等人. [5] 在CNN之前添加一个低通滤波器层, 以检测中值滤波的篡改方法。Bayar 等人 [3] 将低通滤波器层改为自适应内核层, 以了解被篡改区域中使用的滤波内核。除了过滤学习, 张等人 [34] 还提出了一个堆叠自动编码器, 以学习用于图像处理检测的上下文功能。Cozzolino 等人 [9] 将此问题视为异常检测任务, 并使用基于提取特征的自动编码器来区分那些难以重建为被篡改区域的区域。Salloum 等人 [29] 使用完全卷积网络 FCN框架直接预测给定图像的篡改掩码。他们还学习了一个边界掩码来指导FCN查看被篡改的边缘, 这有助于他们在各种图像处理数据集中实现更好的性能。这样的方法是, 基于LSTM的网络应用于小图像补丁, 以查找被篡改的补丁和图像补丁之间边界上的被篡改的部分。
他们通过像素级分割的方法来训练这个网络, 以提高性能, 并显示在不同的篡改情况下的结果。然而, 只关注附近的边界, 在不同的情况下只能取得有限的成功, 例如, 删除整个物体可能不会留下边界证据进行检测。相反, 我们使用全局视觉篡改以及局部噪声的方法可以用来模拟更丰富的篡改情况。我们使用基于faster r-inn 的双流网络来学习用于图像篡改检测的丰富功能。该网络显示了对拼接、复制-移动和删除检测的鲁棒性。此外, 该网络使我们能够对可疑的篡改技术进行分类。
3.提出的方法
我们采用了一个多任务框架, 同时执行分类和边界框回归两个操作。RGB 图像在 RGB流中提供 (图2中顶部的流), SRM图像在噪声流中提供 (图2中底层的流)。为了分类,我们将两个流通过双线性池融合在一个全连接层之前。RPN使用RGB流来集中被篡改的区域。
3.1 RGB 流
RGB流是一个单独的faster r-cnn 网络, 同时用于边界框回归和分类。我们使用 resnet 101 网络 [20] 从输入 RGB图像中学习特征。将resNet最后一个卷积层的输出特征用于分类。 RGB 流中的 RPN 网络利用这些特征为边界框回归提供ROI。在形式上, 网络的损失被定义为
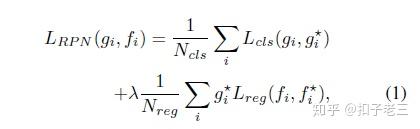
g_{i} 表示在一个小batch中,anchor i是隐藏的潜在被篡改部分的概率
g_{i}^{*} 表示anchor i 的ground truth标签为正。
f_{i} 和 f_{i}^{*} 分别表示anchor i和ground truth的边界框坐标。
L_{cls} 表示RPN网络的交叉熵损失, L_{reg} 表示所提出的边界框的回归平滑 L1 损失。
N_{cls} 表示 RPN网络中的小型batch的大小。
N_{reg} 是anchor位置的数值。
\lambda 是一个超参数, 用于平衡这两个损失, 并设置为10。请注意 , 与传统的目标检测 ( RPN 网络搜索可能是目标的区域 ) 不同 , 我们的 RPN 网络搜索的是可能被篡改的区域。提出的区域不一定是目标, 例如, 删除图像的情况。
3.2 噪声流
RGB通道不足以处理所有不同的操作情况。特别是, 在对那些仔细处理过隐藏了拼接边界和减少对比度差异的篡改图像而言, 只使用RGB 流完成任务具有挑战性。 因此, 我们利用图像的局部噪声分布来提供额外的证据。
与 RGB 流不同的是, 噪声流的设计更注重噪声, 而不是图像内容。这是很新颖的。虽然目前的深度的学习模型在表示 RGB 图像内容的分层特征方面做得很好, 但在深度学习中没有任何工作研究过从检测中的噪声分布中进行学习。受最近图像取证中SRM功能的研究 [15] 的启发, 我们使用SRM滤波器从RGB图像中提取局部噪声特征 (如图3所示的示例), 作为噪声流的输入。
在我们的设置中, 噪声是由像素值与相邻像素的差值估计所产生的残差来建模的。
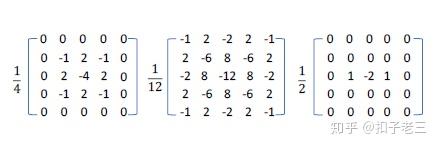
SRM功能从30个基本滤波器开始, 滤波后在输出附近使用最大值和最小值等非线性操作, SRM功能可收集基本的噪声特征,并量化和截断这些筛选器的输出, 并提取附近的同时出现的信息作为最终特征。
从这一过程中获得的特征可以看作是局部噪声描述符 [7]。我们发现, 只有使用3核可以获得较好的性能, 应用所有30核并不会产生显著的性能提升。因此, 我们选择3核 (其权重如图4所示), 并直接将其输入到基于3通道输入的预训练的网络中。我们将噪声流中 SRM滤波器层的内核大小定义为5x5x3。SRM 层的输出通道大小为3。



生成的噪声特征后的 SRM 图层显示在图3的第三列中。很明显, 它们强调的是局部噪声而不是图像内容, 并显示了一些在 RGB 通道中可能无法检测到的被篡改部分。我们直接使用噪声特性作为噪声流网络的输入。噪声流的主干卷积网络体系结构与 RGB 流相同。噪声流与 RGB 流共享相同的 ROI 层。对于边界框回归, 我们只使用 RGB 通道, 因为基于我们的实验, RGB 特征在 RPN 网络中的性能优于噪声特征 (见表 1)。
3.3 双线性池
我们将 RGB 流与噪声流结合起来进行篡改检测。在各种融合方法中, 对两个流的特征应用双线性池。双线性池 [23], 最初被提议进行细粒度分类, 它结合了双流 cnn 网络中的流, 同时保留空间信息, 以提高检测置信度。
我们的双线性池层的输出是 x=f_{RGB}^{T}f_{N} , 其中 f_{RGB}^{T} 是 RGB 流的 ROI 特征,
f_{N} 是噪声流的 ROI 特征。求和池在分类前压缩空间特征。
然后, 我们在全连接层前应用 (x\leftarrow sign(x)\sqrt{|x|}) 和 L2 规范化。
为了在不降低性能的情况下节省内存和加快训练, 我们使用了 [17] 中提出的紧凑型双线性池。 在全连接和softmax层之后, 我们得到了 ROI 区域的预测类, 如图2所示。我们使用交叉熵损失进行分类, 在边界框回归中使用平滑 L1 损失。全损函数为:
L_{total}=L_{RPN}+L_{tamper}(f_{RGB},f_{N})+L_{bbox}(f_{RGB})
其中
L_{total} 表示全部的损失。
L_{RPN} 表示 RPN 网络中的 RPN 丢失。
L_{tamper} 表示基于 RGB 和噪声流的双线性池特征的最终交叉熵分类损失。
L_{bbox} 表示最终的边界框回归损失。 f_{RGB} 和 f_{N} 是来自 RGB 和噪声流的 ROI 功能。所有项的求和产生总损失函数
3.4 实验信息
提出的网络是端到端训练的。输入图像以及提取的噪声特征都会相应调整大小, 使较短的长度等于600像素。使用从82、162、322到642大小的四个anchor尺度, 纵横比为 1: 2、1和2:1。ROI 池后的特征大小为 7x7x1024, 适用于 RGB 和噪声流。紧凑型双线性池的输出特性尺寸设置为16384。RPN 方案的batch大小为64用于训练, 300 用于测试。
使用图像翻转来做数据增强。RPN 正样本示例 ( 潜在被篡改区域 ) IOU 阈值为 0 . 7正 和 0 . 3 , 负样本示例 ( 真实区域 ) 。学习率最初设置为 0.001, 然后在40k 步后降低到0.0001。我们训练我们的模型迭代110k次 。在测试时, 采用标准的非最大抑制 (NMS) 来减少提出局域的重叠冗余。NMS 阈值设置为0.2。
4 实验
我们在四个标准的图像处理数据集上演示了我们的双流网络, 并将结果与最先进的方法进行了比较。我们还比较了不同的数据增强, 并测量了我们的方法对大小调整和 jpeg 压缩的鲁棒性。
4.1 预训练模型
当前标准数据集没有足够的数据用于深层神经网络培训。为了在这些数据集中测试我们的网络, 我们在合成数据集上预先训练我们的模型。我们使用 coco [22] 中的图像和注释自动创建合成数据集。我们使用分段注释从 coco [22] 中随机选择对象, 并将其复制粘贴到其他图像中。按照训练集(90%) 和测试集 (10%) 拆分, 并确保相同的背景和被篡改的对象不会同时出现在训练和测试集中。最后, 我们创建42k 个被篡改和真实的图像的对比。我们将发布此数据集以供研究使用。模型的输出是带置信度分数的边界框 , 指示检测到的区域是否已被篡改。
为了在感兴趣的区域 ROI 中包含一些真实区域, 以便进行更好的比较, 我们在训练期间将默认边界框稍微放大了20个像素, 以便 RGB 和噪声流都能很好学习到被篡改区域和真实区域之间的不一致。
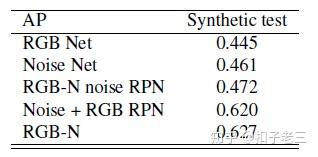
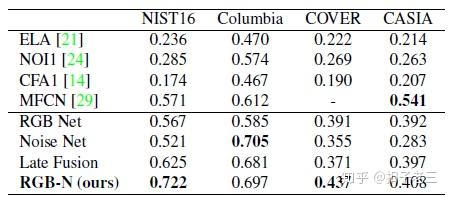
我们在此合成数据集上对模型进行端到端训练。在faster r- cnn 中使用的 resnet 101 在 imagenet 上进行了预训练。我们使用平均精度 AP进行评估, 其度量值与 coco [22] 检测评估相同。我们将双流网络的结果与表1中的每个流进行了比较。
下表显示我们的双流网络比每个流都有更好的性能。此外, 在RGB-N、RGB-使用噪声特征 和 RPN使用两种特征这三种情况下比较,显示出RGB 特征比噪声特征更适合生成可能的篡改区域。
4.2 在标准数据集上测试
我们将我们的方法与 Columbia 数据集、NIST16、CASIA、COVER等进行了比较。
NIST16是一个具有挑战性的数据集,包含了所有的三种篡改手段。该数据集中的篡改部分有经过后期处理来掩盖痕迹。数据也提供了被篡改部分的ground truth 来验证
CASIA数据集提供许多不同种类的经过了拼接和复制-移动两种篡改手段处理后的图片。被篡改的区域是经过精心选择的,有一些也应用了过滤和模糊的处理过程。Ground truth取的是真实区域和被篡改区域的不同的临界阈值。我们使用CASIA 2.0 进行训练, 使用 CASIA 1.0 进行测试。
COVER 是一个专注于复制-移动篡改技术的相对较小的数据集,它为了隐蔽被篡改区域涵盖了一些相似的目标,如图1第二行,提供了ground truth
Columbia数据集关注点为一些未经压缩的拼接图片,也提供了ground truth
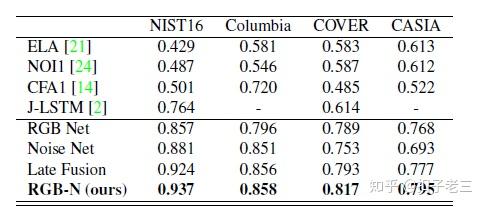
为了在这些数据集中微调我们的模型, 我们从ground truth中提取边界框。我们比较了其他方法相同的训练和测试拆分协议 [2]请参见表2。
评估指标
我们使用像素级 F_{1} 分数和AUC 作为性能比较的评估指标。 F_{1} 分数是用于图像篡改检测的像素级评估指标, 如 [33, 29] 中所述。我们使用了不同的阈值, 并使用最高的 F_{1} 分数作为每个图像的最终分数, 这遵循和 [33, 29]相同的协议。我们将置信度得分分配给检测到的边界框中的每个像素, 用于像素级AUC评估。
基准模型
我们将我们提出的方法与如下所述的各种基线模型进行了比较:
•ELA:一种错误级别分析方法,旨在通过不同的JPEG压缩等级找出篡改区域和真实区域之间的压缩误差。
•NOI1:基于噪声不一致的方法,使用高通小波系数来模拟局部噪声。
•CFA1:CFA模式估计方法,它使用附近的像素来近似相机滤波器阵列模式,然后产生每个像素的篡改概率。
•MFCN:基于多任务边缘增强FCN的网络使用边缘二进制掩码和使用篡改区域掩码的篡改区域联合检测篡改边缘。
•J-LSTM:基于LSTM的网络联合训练补丁级别篡改边缘分类和像素级别篡改区域分割。
•RGB Net:单个Faster R-CNN网络,RGB图像作为输入。即,我们的RGB Faster R-CNN流。
•噪声网:单个Faster R-CNN网络,其噪声特征映射作为从SRM滤波器层获得的输入。在这种情况下,RPN网络使用噪声特征。
•Late Fusion:直接融合,结合RGB Net和噪声网络的所有检测到的边界框。来自两个流的重叠检测区域的置信度得分被设置为最大值。
•RGB-N:用于操作分类的RGB流和噪声流的双线性池和用于边界框回归的RGB流。即本文的完整模型。
使用[29] 中报告的NOI1、CFA1、ELA的 F_{1} 分数, 并运行 [33] 提供的代码来获得 AUC的结果。MFCN和 J-LSTM 的结果从原始文献中复制, 因为它们的代码不是公开的。
表3显示了我们的方法和基线之间的 f1 分数比较。表4提供了AUC的比较。从这两个表中可以清楚地看出, 我们的方法优于传统方法, 如 ELA、NOI1 和 CFA1。这是因为它们都关注仅包含局部信息的特定篡改项目, 从而限制了它们的性能。我们的方法在Columbia和 NIST16 数据集上的性能优于 MFCN。
我们的方法比J-LSTM实现更好的性能的原因之一是 J-LSTM寻求被篡改的边缘作为篡改的证据, 这中方法并不能总是检测到整个被篡改的区域。另外, 我们的方法具有更大的可能区域, 捕获全局上下文像素而不是附近的像素, 这有助于收集更多的线索, 如分类的对比差。
如表3和4所示, 我们的 RGB-n 网络还改进了除 Columbia之外的所有数据集的各个流。Columbia只包含未压缩的拼接区域, 它很好地保留了噪声差异, 因此只需使用噪声特征即可。这将为噪声流提供令人满意的性能。 对于所有数据集, 后期融合的性能都比 RGB-n 差, 这表明了我们的融合方法的有效性。
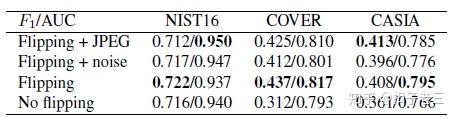
数据增强
我们比较了表5中的不同数据扩充方法。与无增强相比, 图像翻转提高了性能, 其他增强方法 (如 jpeg 压缩和噪声) 几乎没有改善。
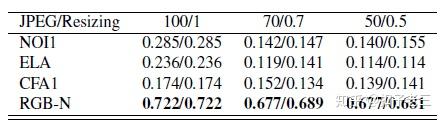
对 jpeg 的鲁棒性和调整攻击大小
我们测试了我们方法的鲁棒性, 并与表6中的3种方法 (其代码可用) 进行了比较。我们的方法对这些攻击更加可靠, 并且优于其他方法。





顶行:COVER数据集的结果。复制-移动混淆了 RGB 网和噪声网。RGB-n 在这种情况下实现了更好的检测, 因它结合了两个流的特征。中间一排显示了来自Columbia的结果。RGB 网络产生的结果比噪声流更准确。底部:casia1.0 的定性结果。拼接对象在 RGB 和噪声流中都会留下明显的篡改伪影, 从而为 RGB、噪声和 RGB-n 网络提供精确的检测。





4.3篡改技术检测
我们网络的丰富的特征表示使其能够区分不同的篡改技术。我们探索了篡改技术检测, 并分析了三种篡改技术的检测性能。NIST16 包含所有三种篡改技术的标签, 可实现多类图像篡改检测。我们将操作分类的类更改为拼接、删除和复制-移动, 以便为每个类学习不同的视觉篡改部分和噪声特征。每个篡改类的性能如表7所示。 表7中的 ap 结果表明, 拼接是使用我们的方法检测到的最简单的操作技术。这是因为拼接具有很高的概率, 可以同时生成 RGB 篡改和噪声篡改 (如非自然边缘、对比度差异以及噪声伪影等)。对于删除操作的检测,性能也优于复制-移动, 因为移除过程会对噪声特征产生很大影响, 如图3所示。复制-移动是我们提出的方法中最难检测的篡改技术。解释是, 一方面, 复制的区域来自同一张图像, 这就产生了类似的噪声分布, 以混淆我们的噪声流。另一方面, 这两个区域的对比度普遍相同。此外, 该技术最好需要将这两个对象相互比较 (即, 它需要同时查找和比较两个 ROI), 而当前的方法并不这样做。因此, 我们的 RGB 流在区分这两个区域方面的证据较少。
4.4. 定性结果
在图5中显示了一些定性结果, 用于比较二类图像处理检测中的 RGB、噪声和 RGB-n 网络。这些图像是从 cover、columbia 和 casia 1.0 中选择的。图5提供了这样的示例: 即使其中一个流失败, 我们的双流网络也会产生良好的性能 (图5中的第一行和第二行)。 图6显示了 RGB-n 网络在使用 nist16 进行操作技术检测任务时的结果。如图所示, 我们的网络为不同的篡改技术产生准确的结果
5.结论
提出了一个新的网络, 同时使用RGB 流和噪声流, 以了解图像处理检测的丰富功能。我们通过从隐身分析文献中提取噪声特征的SRM 过滤层, 使我们的模型能够捕获被篡改区域和真实区域之间的噪声不一致。我们探讨了从RGB 中发现被篡改区域的补充贡献和图像的噪声特征。毫不奇怪, 这两个流的融合会提高性能。在标准数据集上的实验表明, 我们的方法不仅能检测到篡改伪影, 而且还能区分各种篡改技术。未来将探索更多功能, 包括 jpeg 压缩等。
