梯度中心化 一种新的深度神经网络优化技术 Gradient Centralization

先前的一些工作已经研究了投影梯度的性质本文为论文 Gradient Centralization A New Optimization Technique for Deep Neural Networks 的笔记,论文原文链接如下:
源码地址:
梯度中心化
定义
这一部分,作者给出了梯度中心化的基础定义。
对于全连接层,权重矩阵定义为 W_{fc} \in R^{C_{in} \times C_{out}} 。
对于卷积层,权重张量定义为 W_{conv} \in R^{C_{in} \times C_{out} \times (k_1 k_2)} ,其中 C_{in} 是输入通道的数目, C_{out} 是输出通道的数目, k_1, k_2 是卷积核的尺寸。
为了便于表示,作者将卷积层的权重矩阵展开为一个矩阵/张量,并用统一用 W \in R^{M\times N} 表示全连接层( W \in R^{C_{in} \times C_{out}} ) 和 卷积层( W \in R^{(C_{in} k_1 k_2) \times C_{out}} ) 的权重矩阵。
w_i \in R^{M}(i = 1,2,3,...,N) 定义了权重矩阵 W 的第 i 列向量, L 是目标函数。
\nabla_{W}L 和 \nabla_{w_i}L 分别定义了 L 相对于权重矩阵 W 和权重向量 w_i 的梯度。梯度矩阵 \nabla_{W}L 的尺寸和权重矩阵 W 的尺寸一致。
定义 X 为该层的输入激活, W^{T}X 为该层的输出激活。 e=\frac{1}{\sqrt{M}}1 定义了一个 M 维单位向量, I\in R^{M\times M} 定义了一个单位矩阵。
梯度中心化的公式
对于一个全连接层或一个卷积层,假设已经通过反向传播获得了梯度,那么对于一个梯度为 \nabla_{w_i}L(i=1,2,...,N) 的权重向量 w_i ,当梯度中心化操作定义为 \Phi_{GC} 时, \Phi_{GC} 的公式如下:
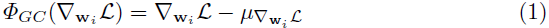

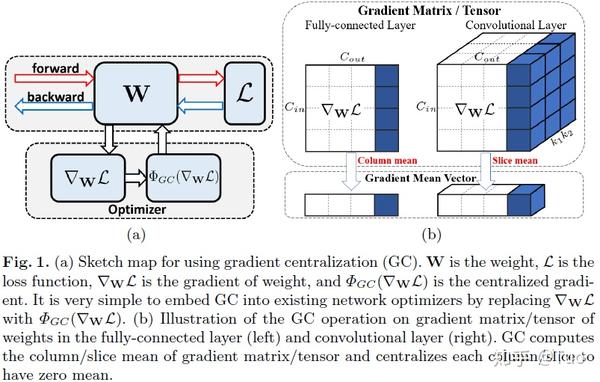
由于权重矩阵的尺寸为 M\times N , \mu\nabla_{w_i}L 表示计算权重矩阵第 i 列的梯度均值。
其中, \mu\nabla_{w_i}L=\frac{1}{M}\sum_{j=1}^{M}{\nabla_{w_i,j}L} 。如图 1(b)所示,只需要计算权重矩阵中列向量的均值,并从各个列向量中减去其各自的均值即可。公式 (1)也可以用矩阵表示,如下:
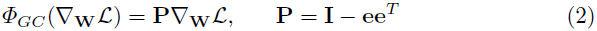

P 的物理意义将在“提升泛化性能”这一节进行讲解。在实际实现中,作者直接从每个权重向量中减去其均值来实现梯度中心化操作。这种计算方式非常简单、高效。

梯度中心化嵌入到 SGDM/Adam
梯度中心化可以容易地嵌入到当前的 DNN 优化算法,如 SGDM 和 Adam。获得中心化的梯度 \Phi_{GC}(\nabla_wL) 之后,直接用其更新权重矩阵。算法 1 和算法 2 给出了如何将梯度中心化嵌入到两个最流行的优化算法:SGDM 和 Adam。如果想使用权重衰减,可以设置 \hat{g}^{t} = P(g^t + \lambda w) ,其中 \lambda 是权重衰减因子。只需要在多数现有的 DNN 优化算法中添加一行代码即可以可忽略不计的计算成本执行梯度中心化。


梯度中心化的性质
提升泛化性能
梯度中心化的一个重要优势是可以提升 DNNs 的泛化性能。作者从两个角度进行了说明:权重空间正则化和输出特征空间正则化。
- 权重空间正则化
首先解释公式 (2) 中 P 的物理意义。实际上,很容易证明以下内容:
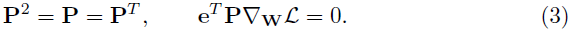

上述公式表明了 P 是权重空间中,法向量为 e 的超平面的投影矩阵, P\nabla_WL 是梯度的投影。
P 负责将梯度 \nabla_WL 投影到法向量为 e 的超平面上。
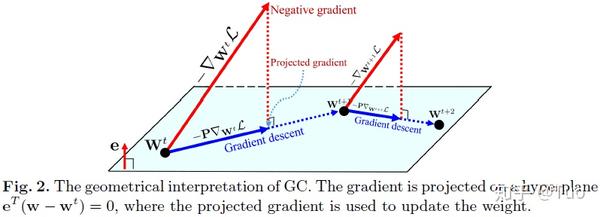
先前的一些工作已经研究了梯度投影的性质,投影权重梯度将限制超平面或者黎曼流形中的权重空间。类似的,梯度中心化的作用也可以从被投影梯度下降的角度来评估。作者在图 2 中给出了使用梯度中心化的 SGD 的几何说明,如图 2 所示,在使用梯度中心化的 SGD 的第 t 步中,梯度首先被投影在由 e^{T}(w-w^{t})=0 决定的超平面上,其中 w^{t} 是第 t 次迭代中的权重向量,然后该权重沿着梯度投影 -P\nabla_{w^t}L 的方向进行更新。从 e^{T}(w-w^{t})=0 可以得出 e^Tw^{t+1}=e^Tw^t=...=e^Tw^0 ,即, e^Tw 在训练期间是常量。从数学上讲,对应一个权重向量 w 的潜在目标函数可以写成如下:
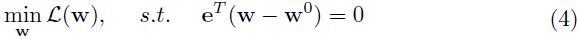

很明了,这是一个关于权重向量 w 的约束优化问题。它正则化了 w 的解空间,从而减少了过度拟合训练数据的可能性。因此,梯度中心化可以提升经过训练的 DNN 模型的泛化能力,尤其是训练样例数目有限时。

在已有研究WS[1]中,使用约束条件 e^Tw=0 来优化权重。该方法通过重新参数化权重来满足这个约束。但是,该约束条件大大限制了其实际应用,因为初始化的权重可能不满足该约束条件。例如,一个通过 ImageNet 预训练的 DNN 模型,其初始化的权重向量通常不满足 e^Tw^0=0 。如果使用 WS 来微调该 DNN 模型,预训练模型的优势将消失。因此,在微调该模型之前,必须在 ImageNet 上使用 WS 重新训练该 DNN 模型。幸运的是,公式 (4) 中梯度中心化的权重约束满足任何权重初始化,例如,ImageNet 预训练的初始化,因为它将初始化权重 w^0 考虑在约束中,因此 e^{T}(w^0-w^{0})=0 永远是对的。这极大地扩展了梯度中心化的应用。
- 输出特征空间正则化
对于基于 SGD 的算法,可以得到 w^{t+1}=w^t-\alpha^tP\nabla_{w^t}L 。可以派生出 w^t=w^0-P\sum_{i=0}^{t-1}{\alpha^{(i)}}\nabla_{w^{(i)}}L 。对于任何输入特征向量 x ,有以下定理:
定理 4.1:假设使用梯度中心化的 SGD(或 SGDM)来更新权重向量 w ,对任何输入特征向量 x 和 x+\gamma 1 ,可以得到:
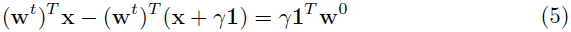

其中, w^0 是初始化权重向量, \gamma 是一个标量。
定理 4.1 表明一个输入特征的一个恒定强度变化(例如, \gamma1 ),会引起一个输出激活的变化;有趣的是,这个变化只与 \gamma 和 1^Tw^0 相关,而不是当前权重向量 w^t 。 1^Tw^0 是初始权重向量 w^0 的缩放均值。特别地,如果 w^0 的均值趋近于0,那么输出激活对输入特征的强度变化不敏感,并且输出特征空间对于训练样例的变化具有更强的稳定性。
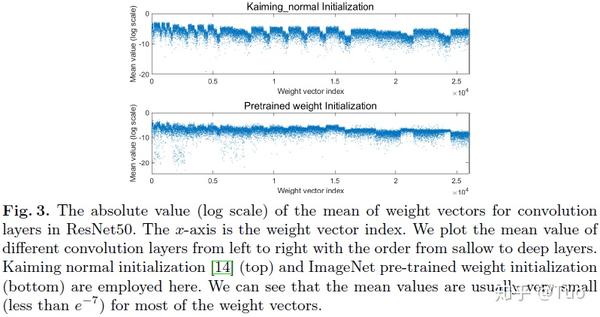
实际上,常用的权重初始化策略使权重 w^0 的均值非常趋近于0,例如 Xavier 初始化方法,Kaiming 初始化方法,甚至包括 ImageNet 预先训练权重的初始化。图 3 给出了使用 Kaiming 标准初始化和 ImageNet 预训练权重初始化的 ResNet50 中卷积层权重向量的绝对值均值(取 权重向量的 log 值)。可以看到大多数权重向量的均值都非常小,并且接近0(小于 e^{-7} )。这保证了如果使用梯度中心化训练 DNN 模型,其输出特征将对输入特征的强度变化不敏感。

加速训练过程
- 平滑优化轨迹
在文献[1][2]中说明了 BN 和 WS 可以平滑优化轨迹。尽管 BN 和 WS 针对激活和权重进行操作,但是它们隐式地限制了权重的梯度,使权重的梯度针对快速训练更具有预测性和稳定性。特别地, BN 和 WS 使用梯度的 L2 范式 ||\nabla f(x)||_2 来使函数 f(x) 满足利普希茨(Lipschitzness) 特性。对于损失函数和其梯度, f(x) 为损失函数 L , \nabla_{w}L 为损失函数的梯度, x 为权重 w 。 ||\nabla_{w}L||_2 和 ||\nabla^{2}_{w}L||_2 ( \nabla^{2}_{w}L 是 w 的 Hessian 矩阵) 的上界已经在文献[1][2]中给出了,并且依据该上界说明了 BN 和 WS 能够平滑优化轨迹的特性。通过比较原始损失函数 L(w) 和公式 (4) 中带有约束的损失函数的利普希茨特性,以及它们各自梯度的利普希茨特性,可以对梯度中心化得到相似的结论。作者给出了如下的定理:
定理 4.2:假设 \nabla_wL 是损失函数 L 相对于权重向量 w 的梯度。通过公式 (2) 中定义的 \Phi_{GC}(\nabla_wL) ,可以得到以下关于损失函数和其梯度的结论:
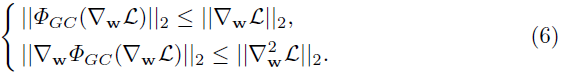

定理 4.2 说明了对于损失函数 L 和其梯度 \nabla_wL ,公式 (4) 中被梯度中心化约束的损失函数与原始的损失函数相比,能够达到更好的利普希茨特性,因此,优化轨迹变得更为平滑。这意味着梯度中心化在加速训练上与 BN 和 WS 有相似的优势。一个关于梯度的好的利普希茨特性意味着用于训练的梯度更具有预测性、表现更好,因此,能够使优化轨迹更为平滑,达到更为快速、高效的训练目的。
- 抑制梯度爆炸
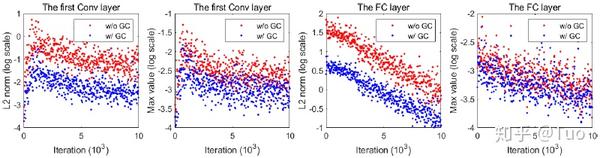
梯度中心化对 DNN 训练的另一个益处就是可以避免梯度爆炸,是训练过程更为稳定。这一特性与梯度裁剪相似。过大的梯度会导致训练过程中权重突然变化,从而可能使损失剧烈波动且难以收敛。现有研究[3][4]已经证明了梯度裁剪可以抑制大梯度,从而使训练更为稳定、快速。当前主要有两种流行的梯度裁剪方法:按元素值裁剪[3][5]和范式裁剪[4][6],这两种方法对梯度矩阵的按位元素值和梯度范式施加阈值,以此达到裁剪的目的。为了探查梯度中心化对梯度裁剪的影响,在图 4 中,作者绘制了使用梯度中心化的ResNet50(基于 CIFAR100 训练)中第一个卷积层和全连接层的梯度矩阵的最大值和 L2 范式值。从图 4 中可以看出通过使用梯度中心化,训练过程中梯度矩阵的最大值和 L2 范式值均变得更小。这符合定理 4.2 中的结论,即梯度中心化可以是训练过程更为平滑、快速。

参考
- ^abcQiao, S., Wang, H., Liu, C., Shen, W., Yuille, A.: Weight standardization. arXiv preprint arXiv:1903.10520 (2019)
- ^abSanturkar, S., Tsipras, D., Ilyas, A., Madry, A.: How does batch normalization help optimization? (no, it is not about internal covariate shift) pp. 2483{2493 (2018)
- ^abPascanu, R., Mikolov, T., Bengio, Y.: Understanding the exploding gradient prob- lem. CoRR, abs/1211.5063 2 (2012)
- ^abPascanu, R., Mikolov, T., Bengio, Y.: On the diculty of training recurrent neural networks. In: International conference on machine learning. pp. 1310{1318 (2013)
- ^Kim, J., Kwon Lee, J., Mu Lee, K.: Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 1646{1654 (2016)
- ^Abadi, M., Chu, A., Goodfellow, I., McMahan, H.B., Mironov, I., Talwar, K., Zhang, L.: Deep learning with di erential privacy. In: Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. pp. 308{ 318. ACM (2016)
