![[论文总结] 图像分类经典模型](https://pic1.zhimg.com/v2-f4c985a5e7d95b4375b32871ef7783ea_r.jpg?source=172ae18b)
[论文总结] 图像分类经典模型

[论文总结] 图像分类经典模型
\quad 欢迎大家关注我的专栏,顺便点个赞~~~
\quad 图像分类是计算机视觉中最为基本的任务,即将图像分类到具体的语义类别。近年来,卷积神经网络在图像分类上大放异彩,自2012年AlexNet出世以来,具有优异性能的图像分类模型往往是由CNN构成。一般认为,CNN具有很强的特征提取能力,被称为Backbone(主干网络),在分类任务具有良好性能的模型往往在下流任务(检测、分割等)中也有很好的表现。
\quad 目前来说,衡量图像分类性能的数据集为ImageNet-1k(ILSVRC)。ImageNet-21k具有超过1500万个标记的高分辨率图像的数据集,并且具有22000个类别。这些图像是从网上收集的,并使用亚马逊的Mechanical Turk crowd-sourcing工具手工进行标记。从2010年开始,作为Pascal视觉对象挑战赛的一部分,举办了名为ImageNet大规模视觉识别挑战赛(ILSVRC)的年度比赛。
\quad ILSVRC使用ImageNet的一个子集,在1000个类别中分别拥有大约1000个图像。总计,大约有120万个训练图像,50000个验证图像和150000个测试图像。在ImageNet上,习惯上报告两个错误率:top-1和top-5,其中前5个错误率是测试图像的分数,正确的标签不属于模型认为最可能的5个标签之中。
\quad 用CNN进行图像分类最早可以追溯到LeNet,本文主要介绍经典的CNN图像分类模型,包括AlexNet、GoogLeNet、VGG、ResNet、ResNeXt和SENet。
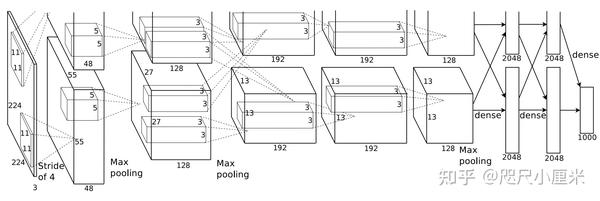
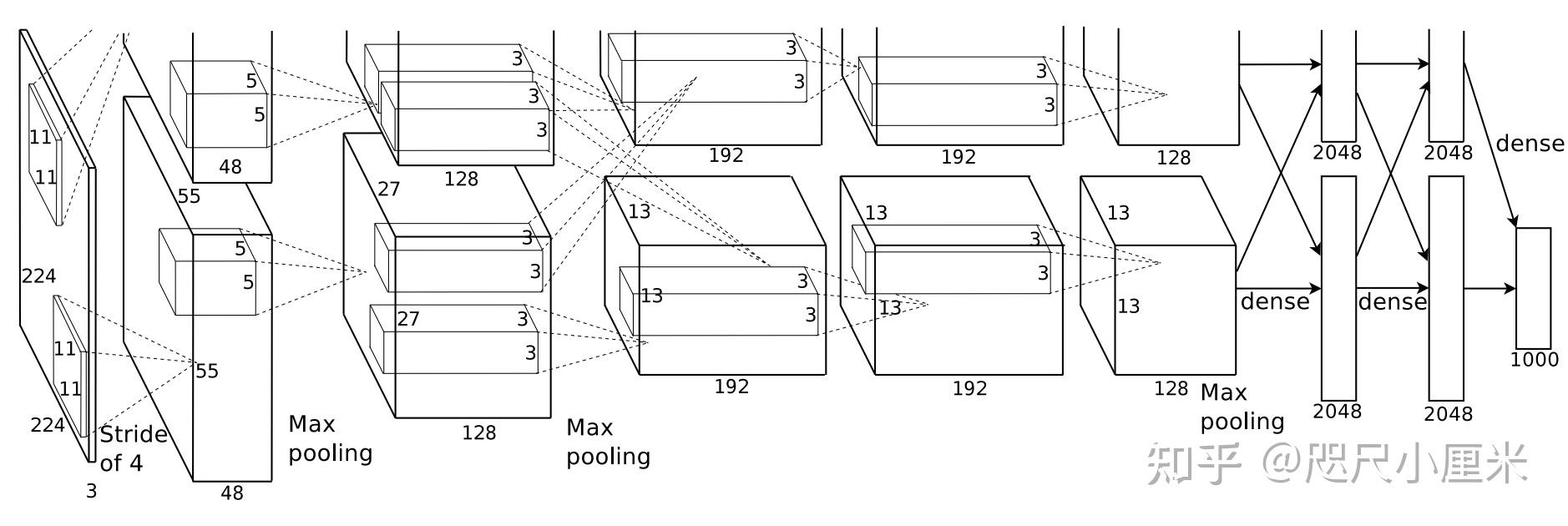
- AlexNet
- NIPS 2012,自LeNet之后体现出很强的性能
- AlexNet在ILSVRC-2012中获得了冠军,top-1为62.5%,top-5为83.0%,比第二名高近10%
- 使用Relu激活函数,局部响应归一化(现在基本弃用)
- 因为当时显卡显存不够,使用两卡并行训练
- 优化器是SGD+Momentum
- 一作的名字叫Alex
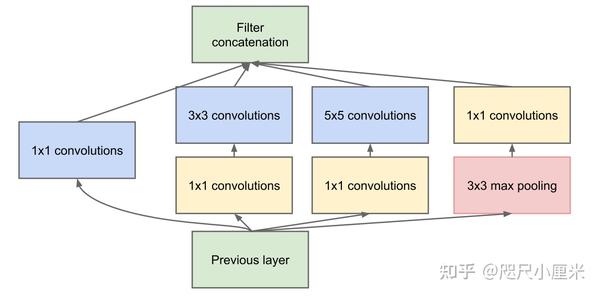
- GoogLeNet
- CVPR 2015,GoogLeNet是Inception v1,ILSVRC14的top-1解法,top-5准确率为93.33%
- 赫布理论和稀疏性原则作为指导,利用密集计算来实现稀疏性的神经网络结构
- 这种精心设计的网络结构可能在其他数据集上泛化性稍稍弱些
- GoogLeNet是为了致敬LeNet
- 研究了宽度对网络性能的影响

- VGG
- ICLR 2015,ILSVRC14的top-2解法,top-5准确率为93.2%
- 研究了深度对CNN性能的影响,提出用堆叠的小卷积核来代替大卷积核
- 因为模型构造简单有效,因此其实VGG适用性更广一些(个人觉得)
- VGG是作者单位的简称,Oxford Visual Geometry Group
- VGG模型在多个迁移学习任务中的表现要优于GoogLeNet
- 缺点在于参数量和计算量都很大
- VGG16、VGG19中的数字都是指有参数层的数量
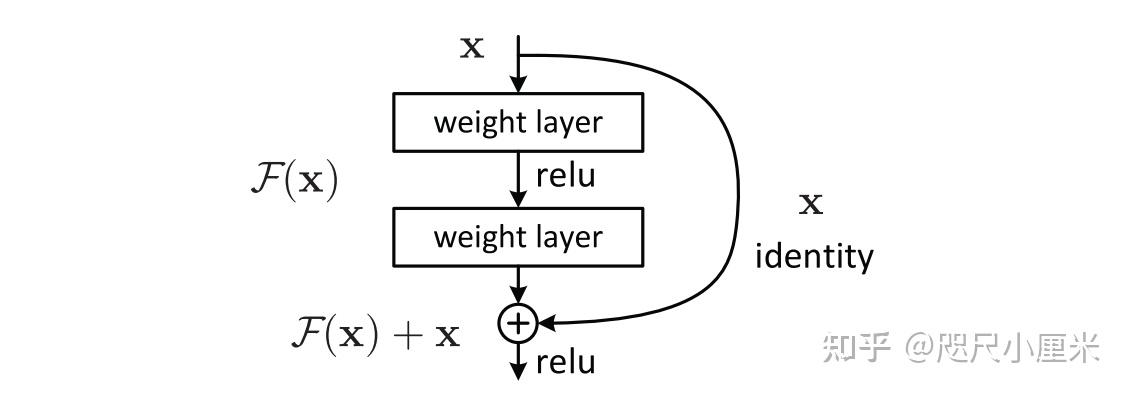
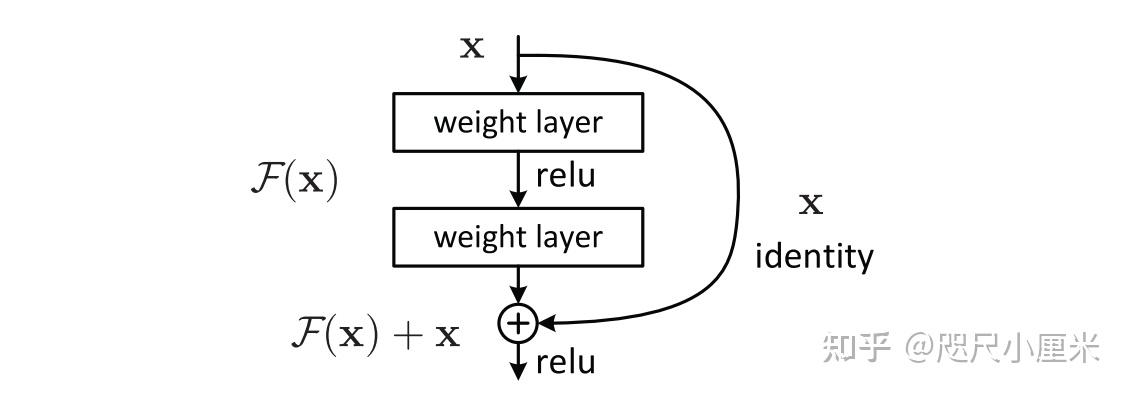
- ResNet
- CVPR 2016 best paper,Kaiming大作,ILSVRC 2015的top-1解法,top-5错误率5.57%,而且多项全能
- 发现了CNN深度越深,但是性能退化的问题,并用残差学习解决
- 提出了残差学习,学习残差比学习一个未知的函数要容易
- 目前使用最广泛的CNN模型,其残差模块和bottleneck的设计被之后很多的工作follow
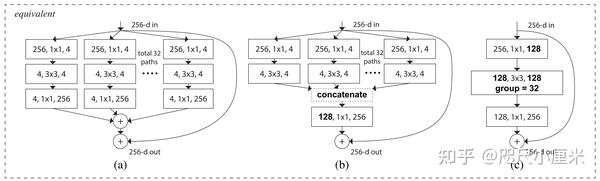
- ResNeXt
- CVPR 2016,ILSVRC 2016的top-2解法,改进了ResNet,top-5错误率5.3%
- 研究了基数对CNN性能的影响,其实就是对普通卷积做分组的分组数量,它是深度和宽度维度之外的一个重要因素
- 想到了Xception(CVPR 2017),它是普通卷积的分组数的极限情况,性能也比Inception要好,当时作者就说,他认为最好的情况不一定是极限,可能是其中的某一种分组情况,正好和本文对上了

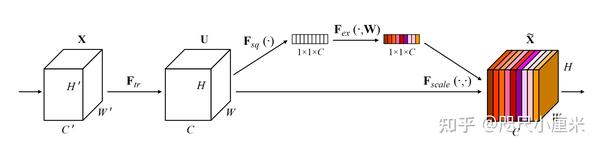
- SENet
- CVPR 2018,ILSVRC 2017的top-1解法,top-5错误率2.251%,领先第二近25%
- 引入通道注意力机制,对通道进行加权,这不是引入一个新的空间维度来进行特征通道间的融合,而是采用了一种全新的“特征重标定”策略
- 即插即用,引入的参数量较小,但是提升巨大

\quad 官方的解释文章:
- 小结
\quad 针对分类的工作很多很多,最新的进展已经进入MLP->CNN->ViT->MLP的循环里了。除此之外,网络框架搜索的工作也推动了图像分类模型的进展。不得不说,深度学习的确是由图像分类这些CNN模型带火的。
