如何评价EfficientZero?

0. Summary
本文在MuZero的基础上针对model-based的image-based 的环境的强化学习算法采样效率低的问题进行改进。提出了三个影响效率的问题并针对问题分别提出了三个解决方法,分别是自监督的一致性损失、端到端的预测值前缀、基于模型的策略外修正。这些方法和MuZero结合得到了EfficientZero,在Atari100k上用两个小时的游戏时间进行训练,超过人类平均水平。并通过消融实验验证了三个方法的有效性。
1. Problem Statement
强化学习算法的样本复杂度很高,相比人类需要很多的样本去学习。在真实场景中,比如机器人、医疗保健、广告推荐的样本是有限的,怎么在有限的样本得到 较好的结果十分重要。
提高采样效率的方法自然就会想到 Model-based methods,构建模型来模拟环境。现有的方法主要对 state-based 环境有效,而对于 image-based 的环境,达到超过人类水平但是采样效率不高(MuZero,Dreamer V2),SimPLe 采样效率高但是效果差。
2. Method(s)
针对 model-based visual RL 提出了 EfficientZero。通过 MuZero 在有限数据的消融实验确定了三个问题,分别对于这三个问题提出了三个解决方法。在 Atari100k (相当于两个小时游戏时间)超过人类水平。
2.1 三个问题
- 缺乏对环境模型的监督(Lack of supervision on environment model):比如在 MuZero 中只学习 reward,value,policy function。奖励是标量且稀疏,无法提供足够的训练信号来学习环境模型。
- 难以处理不确定性(Hardness to deal with aleatoric uncertainty):由于环境是复杂的,导致预测的奖励误差大,并且在 MCTS 搜索深度增加这种误差会不断积累。
- 具有多步骤价值的策略外问题(Off-policy issues of multi-step value):MuZero 采用多步奖励来计算 value target,虽然加快学习,但是存在严重的 off-policy 的问题。
2.2 自监督的一致性损失(Self-Supervised Consistency Loss)
之前的方法由于奖励标量的性质不能学习到足够的信息,而 MCTS 的策略提升极度依赖环境模型的正确性,所以学好环境模型非常重要。SimSiam是通过自监督学习图像的表示的方法,本文以此为框架学习图像的表示和转换。
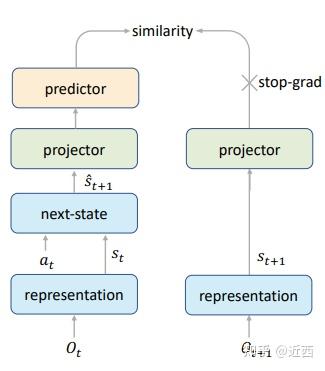
如上图所示本文加入了一个新的损失——自监督一致性损失。用 s_{t+1} 来监督 \hat s_{t+1} ,加强了对环境变换的学习。
\mathcal{L}_{\text {similarity }}\left(s_{t+1}, \hat{s}_{t+1}\right)=\mathcal{L}_{2}\left(s g\left(P_{1}\left(s_{t+1}\right)\right), P_{1}\left(P_{2}\left(\hat{s}_{t+1}\right)\right)\right) \\
2.3 端到端的预测值前缀( End-To-End Prediction of the Value Prefix)
model-based 的方法,需要根据当前状态和一系列后序动作预测未来的状态,因此 错误会不断累加,这种问题称为 the state aliasing problem(状态混叠问题)。 Q\left(s_{t}, a\right)=\sum_{i=0}^{k-1} \gamma^{i} r_{t+i}+\gamma^{k} v_{t+k} ,值前缀是 \sum_{i=0}^{k-1} \gamma^{i} r_{t+i} 的部分。之前的方法每一步独立的对reward进行预测, r_{t}=\mathcal{R}\left(s_{t}, a_{t}\right), \hat{s}_{t+1}=\mathcal{G}\left(s_{t}, a_{t}\right) ,这样的方法前面的错误会对后面产生影响并不断累积。本文提出端到端的方式计算值前缀,value-prefix =f\left(s_{t}, \hat{s}_{t+1}, \cdots, \hat{s}_{t+k-1}\right) ,采用LSTM模型来实现。这种方法计算更准确,因为它可以自动处理中间状态混叠问题。
2.4 基于模型的策略外修正(Model-Based Off-Policy Correction)
value function是对当前策略网络好坏的估计。但是在MuZero需要从relay buffer采样trajectory计算 z_{t}=\sum_{i=0}^{k-1} \gamma^{i} u_{t+i}+\gamma^{k} v_{t+k} ,然而这些都是旧策略的结果,与当前的策略存在偏差(对于数据限制的情况尤为明显)。首先减少计算的步长来减少偏差, l <= k ,然后使用model-based的环境模型对当前策略重做 MCTS 搜索,并计算根节点处value进行修正。
z_{t}=\sum_{i=0}^{l-1} \gamma^{i} u_{t+i}+\gamma^{l} \nu_{t+l}^{\mathrm{MCTS}}\\
3. Evaluation
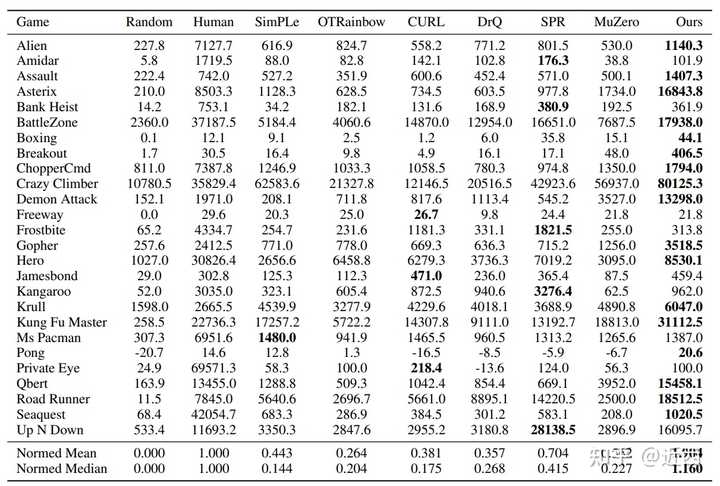
作者在Atari 100k benchmark和DMControl 100k benchmark上进行了实验,并对于三个方法进行了消融实验(Ablations)。
Atari 100k benchmark

DMControl 100k benchmark


Ablations


通过实验可以看出一致性损失起到的作用较大。
4. Conclusion
EfficientZero在 Atari 游戏中只需要两个小时的游戏时间表现超过人类平均水平,通过消融实现表明了三个方法的有效性。作者认为该方法在连续动作空间需要更好的设计、需要研究MCTS的加速、以及与终身学习(life-long learning)相结合。
Reference
[1] Ye W, Liu S, Kurutach T, et al. Mastering Atari Games with Limited Data[J]. Advances in Neural Information Processing Systems, 2021, 34. (EfficientZero)
[2] Schrittwieser J, Antonoglou I, Hubert T, et al. Mastering atari, go, chess and shogi by planning with a learned model[J]. Nature, 2020, 588(7839): 604-609.(MuZero)
[3] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. arXiv preprint arXiv:2011.10566, 2020.(SimSiam)