Neural LP

文章:Differentiable Learning of Logical Rules for Knowledge Base Reasoning
本文提出了一个可微的基于知识库的逻辑规则学习模型。现在有很多人工智能和机器学习的工作在研究如何学习一阶逻辑规则(逻辑规则的好处是可解释,保证鲁棒性),规则示例如下图:
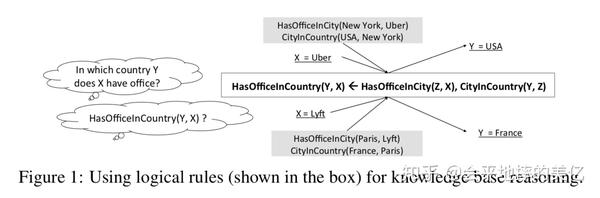

关系规则的学习集合是一种统计关系学习,通常底层逻辑是概率逻辑。使用概率逻辑的优点是,通过给逻辑规则配备概率,可以更好地对统计上复杂和有噪声的数据进行建模。不幸的是,这个学习问题相当困难——它需要学习结构(即模型中包含的特定规则集)和参数(即与每个规则相关联的置信度)。
形式化本文关心的逻辑规则如下:
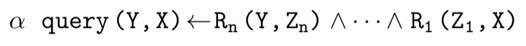

每一个规则由多个约束条件组合而成,并且被赋予一个置信度 α,其中query(Y,X) 表示一个三元组,query 表示一个关系。
不同于基于 embedding 的知识库推理,规则应该是实体无关的,规则可以应用于任何新添加到知识库中的实体,但在知识库 embedding 方法里,新添加到知识库中的实体由于没有对应的表示,无法就这些实体进行相关的推理。
不同于以往的基于搜索和随机游走的规则学习方法,本文的目标是提出一个可微的一阶谓词逻辑规则学习模型,可用基于梯度的方法进行优化求解。
本文提出的NeuralP模型主要收到 TensorLog 的启发。TensorLog 可视为一个可微的推理机。ensorlog operation主要包括用one-hot表示实体,用邻接矩阵表示关系,维度为 \left| E \right| × \left| E \right|。每一条逻辑规则的右边部分被表示为以下形式:
这篇paper是基于Tensorlog的。Tensorlog operation主要包括用one-hot表示实体,用邻接矩阵表示关系,结合这两个操作就可以得出logical rule R(Y,X)←P(Y, Z) ∧ Q (Z, X) 要inference Y的结果为
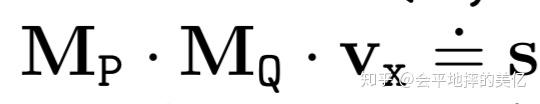

向量s中为1的位置就是Y的答案。
上面这个式子说的是规则长度为2的case,泛化到任意长度的规则就是,
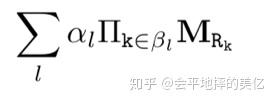
l表示所有的可能规则, \alpha_{l} 是规则l的置信度, \beta_{l} 是某特定关系里的有序关系列表,所以在inference时,给定实体 v_x ,实体y的score等于下式中向量s中的对应y的位置的值。
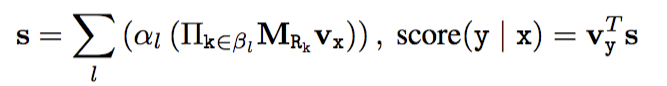

所以对应的objective function就是
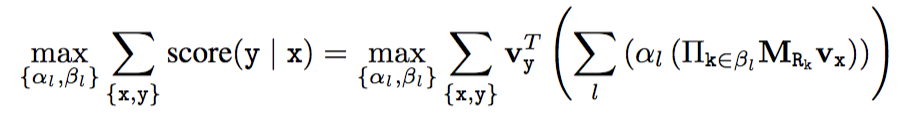

\alpha_l,\beta_l 是要学习的参数,分别对应规则集中第l个规则的权重和关系序列,也就是前面说的parameter和structure。很明显,这是不可微的。在在上式的优化问题中,算法需要学习的部分分为两个:一个是规则的结构,即一个规则是由哪些条件组合而成的;另一个是规则的置信度。由于每一条规则的置信度都是依赖于具体的规则形式,而规则结构的组成也是一个离散化的,因此上式整体是不可微的。因此作者对前面的式子做了以下更改:
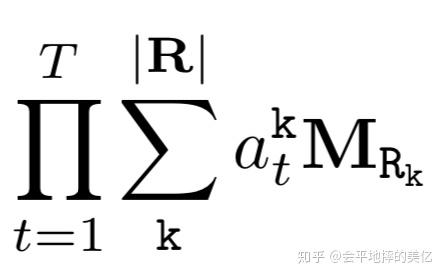

主要交换了连乘和累加的计算顺序,对预一个关系的相关的规则,为每个关系在每个步骤都学习了一个权重,即上式的 \alpha_{t}^{k} 。T是规则的最大长度,|R|是KB的规则个数,这样确实可微了,但限定了规则的长度。为了能够学习到变长的规则,Neural LP中设计了
记忆向量 u_t 表示第t个步骤输出的答案,即每个实体作为答案的概率分布。
记忆注意力向量b_t 表示在第t个步骤时对于之前每个步骤的注意力。
算子注意力向量a_t 表示在步骤t时对于每个关系算子的注意力。
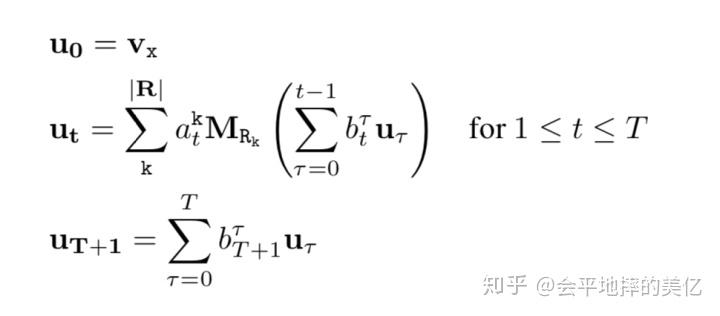

a_t,b_t 都是用RNN网络得出的:


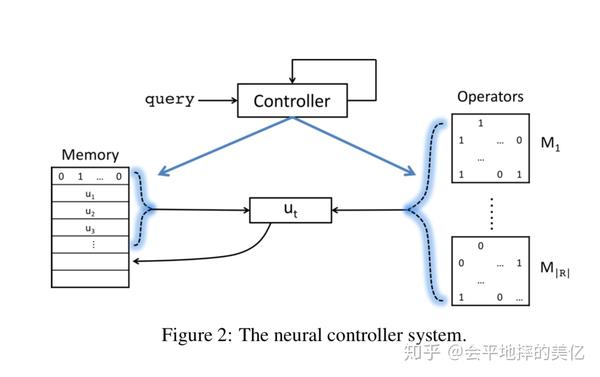

其中memory存的就是每步的推理结果(实体),最后的输出即u_{T+1},objective就是最大化logv_y^Tu,加log是因为非线性能让效果变好。
总结:embedding based主要学习关系和实体的表示,而neural logic programming学习逻辑规则。此外,由Neural LP学习的逻辑规则可以应用于训练时看不到的实体。这是无法通过结构嵌入实现的,因为它的推理能力依赖于实体依赖的表示。
作者设计了一个实验,使得只有他的模型和他的假设能 work. 主要的细节是: 让 train 和 test 没有 entity overlap。本文完胜embedding的方法。
