
AAAI 2020 | 中科院&云从科技:双视图分类,利用多个弱标签提高分类性能

作者 | 云从科技
编辑 | Camel
本文是对中科院信工所和云从科技共同完成,被 AAAI2020 录用的论文《Coupled-view Deep Classififier Learning from Multiple Noisy Annotators》进行解读。


近年来,深度学习已在各种分类任务中证明了有效性,例如使用深度神经网络(DNN)在有标签的数据上训练风控模型,取得了良好效果。但在许多现实情况下,例如真实场景的视频监控和医疗图像诊断,很难收集到清晰准确的标注。
云从科技与中科院信工所发表《Coupled-view DeepClassififier Learning from Multiple Noisy Annotators》,探索能够有效地利用多个弱标签的信息进行深度学习分类的方法,提出了一种从多人标注的带噪标签中进行双视图深度分类器学习的新方法。
文中,我们专注于研究从多人标注的噪声标签中进行深度神经网络分类学习这一问题,将期望最大化算法的迭代估计过程看作标签视图和数据视图的相互学习问题(如图1)。我们通过让两个视图分别学习对方视图生成的伪标签,把这一问题转化为监督学习问题,并通过迭代的更新伪标签和模型参数,让两个视图进行相互学习。我们提出的方法(称为 CVL)减少了对错误标签的过拟合,并且具有更稳定的收敛表现。
新方法基于深度学习的双视图分类算法,充分利用多个弱标签的信息进行建模,在安防布控、业务风控、金融安全等领域均可应用,可有效提升安防水平及风控业务等。与安防领域创新应用相结合,显著提升安防监管系统的加固,更高效地提升安防作战能力,提高安保工作效率。同时,在金融风控、创新安全等领域也有技术上的稳定效用。
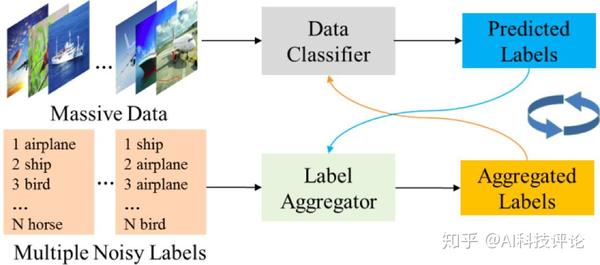

新算法概述
新算法尝试在特征空间和标签空间两个视图里分别构建分类器,在训练过程中,两个分类器的结果互为指导、互相监督,通过交替迭代更新,最终训练出性能稳定的分类器。
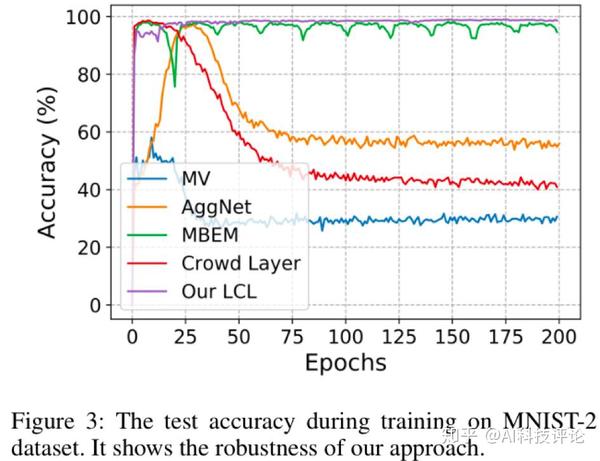
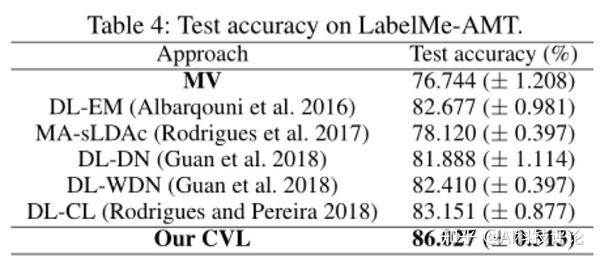
在两个合成数据集(MNIST和CIFAR10)和一个真实数据集(LabelMe-AMT)中进行实验,最后对比结果显示,CVL方法在有效性、鲁棒性、稳定性等方面均优于其他算法。
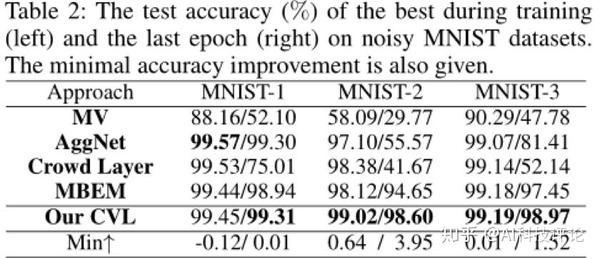

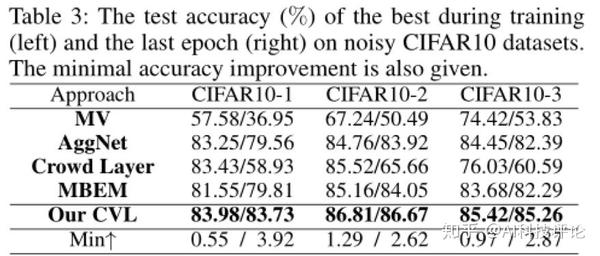

图 2、图3:在合成数据集mnist和cifar10上实验,我们的方法在有效性和鲁棒性方面胜过现有的其他技术示例结果


方法解读
首先,我们可以将所研究的弱监督问题转化为两个视图的相互学习问题:
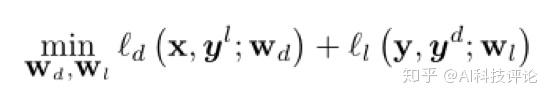

在经过初始化和预训练后,这一问题可以在交替更新的预测标签和聚集标签的监督下,通过替代优化解决。这种双视图视角提供了一种简单而通用的方式,使标签聚合器和数据分类器彼此交换知识。
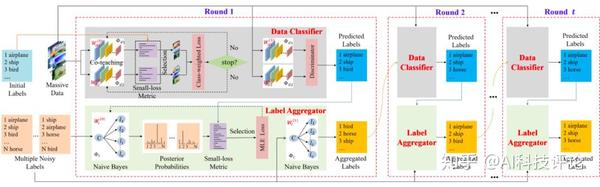

随后,我们在两种学习视图中采用了几种策略,以促进相互学习收敛到良好和稳定的结果。
1、标签视图
基本模型。假设每个标注者的标签噪声都是随机且独立的情况下,我们采用了一种以噪声混淆矩阵为学习参数的朴素贝叶斯分类器。在噪声混淆矩阵π和类别先验分布q不变的情况下,第 i 个样本的第 k 类的后验概率可以用下式计算:
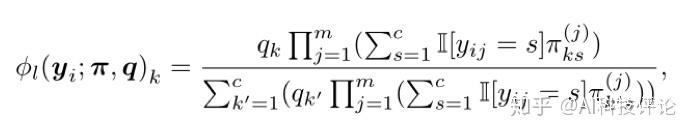

训练模型。两个视图的训练会遇到视图的不充分性问题,这意味着该视图提供的信息不足以充分地完美地预测所有样本,其中必然会发生预测错误。为了减少这一因素的影响,我们使用小损失度量标准作为测量标签的置信度,对进行样本选择。
在标签视图中,采用小损失度量标准选择标签之后极大似然估计的损失如下:
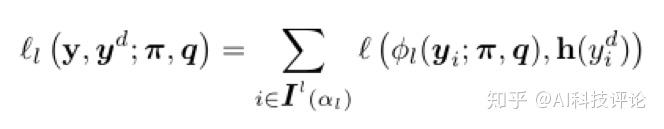

根据损失函数,参数π可以通过下式来估计:
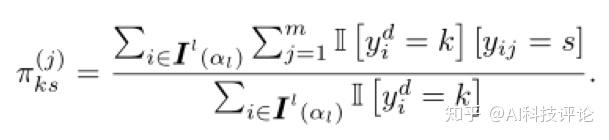

此外,在已知类别均衡的情况下,设置 q_k =1/c 。
更新聚合标签。每一轮,标签视图更新自己的伪标签一次:
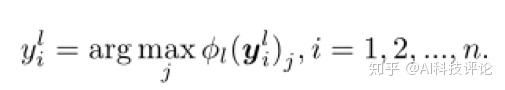

2、数据视图
基本模型。由于深度网络具有很高的学习能力,我们选择神经网络作为数据分类器。
训练分类器。除了同样使用小损失度量之外,我们还提出了两种策略。首先,由于深度网络具有很高的容量,能够拟合任意数据,在使用小损失度量之后,它由于会初始化的不同导致不同的错误选择偏置。我们还进一步采用了协同教学策略减少这一影响。这意味着 \phi_d
使用结构相同但初始化不同的两个网络 \phi_{d1} 和 \phi_{d2} ,并且在每个batch中,每个网络都将其选定的小损失样本视为有用的知识,并将此类样本教给其对等网络以进行更新参数。由于两个网络具有不同的学习能力,这样可以过滤掉带噪标签引起的不同类型的错误。其次,由于所选样本通常是类别不平衡的,因此必须添加类平衡约束。对于深度分类器,由于我们的方法会在每个batch中选择样本,因此我们在每个batch中进行动态的类别加权损失,以防止网络过度偏好某些特定类别。
在训练过程中,每个epoch中,我们首先将 \{x, y^l\} 洗牌并划分为p 个batch, \{x_k, y_k^l\} ,(k= 1, 2, ... , p)。然后两个网络在每个batch中选择出各自的小损失样本集合给对等网络学习。第k个batch的损失函数如下:
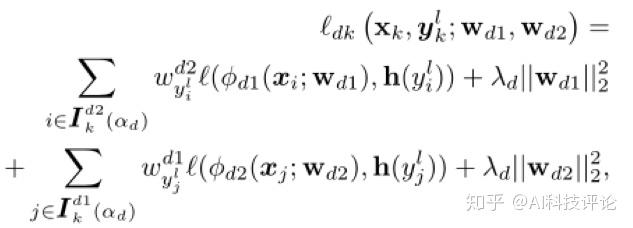

更新预测标签。每一轮,在两个网络输出分类结果分别为 y_i^{d1} 和 y_i^{d2} 的情况下,数据视图通过下式更新标签。
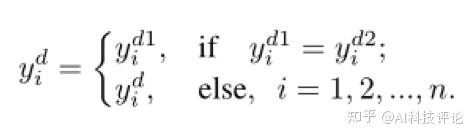

AAAI 2020 论文集:AAAI 2020 论文解读会 @ 望京(附PPT下载)
AAAI 2020 论文解读系列:
01. [中科院自动化所] 通过识别和翻译交互打造更优的语音翻译模型
02. [中科院自动化所] 全新视角,探究「目标检测」与「实例分割」的互惠关系
03. [北理工] 新角度看双线性池化,冗余、突发性问题本质源于哪里?
04. [复旦大学] 利用场景图针对图像序列进行故事生成
05. [腾讯 AI Lab] 2100场王者荣耀,1v1胜率99.8%,腾讯绝悟 AI 技术解读
06. [复旦大学] 多任务学习,如何设计一个更好的参数共享机制?
07. [清华大学] 话到嘴边却忘了?这个模型能帮你 | 多通道反向词典模型
08. [北航等] DualVD:一种视觉对话新框架
09. [清华大学] 借助BabelNet构建多语言义原知识库
10. [微软亚研] 沟壑易填:端到端语音翻译中预训练和微调的衔接方法
11. [微软亚研] 时间可以是二维的吗?基于二维时间图的视频内容片段检测
12. [清华大学] 用于少次关系学习的神经网络雪球机制
13. [中科院自动化所] 通过解纠缠模型探测语义和语法的大脑表征机制
14. [中科院自动化所] 多模态基准指导的生成式多模态自动文摘
15. [南京大学] 利用多头注意力机制生成多样性翻译
16. [UCSB 王威廉组] 零样本学习,来扩充知识图谱(视频解读)
17. [上海交大] 基于图像查询的视频检索,代码已开源!
18. [奥卢大学] 基于 NAS 的 GCN 网络设计(视频解读)
19. [中科大] 智能教育系统中的神经认知诊断,从数据中学习交互函数
20. [北京大学] 图卷积中的多阶段自监督学习算法
21. [清华大学] 全新模型,对话生成更流畅、更具个性化(视频解读,附PPT)
22. [华南理工] 面向文本识别的去耦注意力网络
23. [自动化所] 基于对抗视觉特征残差的零样本学习方法
24. [计算所] 引入评估模块,提升机器翻译流畅度和忠实度(已开源)
25. [北大&上交大] 姿态辅助下的多相机协作实现主动目标追踪
26. [快手] 重新审视图像美学评估 & 寻找精彩片段聚焦点


